
Statystyki z Messengera
Co mówią o nas wiadomości.
Wpis z serii Kochajmy się jak bracia, analizujmy się jak Facebooki
Witajcie w kolejnym wpisie poświęconym analizowaniu rzeczy z Facebooka! ![]() Dawnośmy już tu nie gościli tej serii.
Dawnośmy już tu nie gościli tej serii.
Poprzednio pokazałem, w jaki sposób można pobrać swoje dane z Facebooka. Opisałem też krótko, jakie wiązały się z nimi problemy. A teraz czas na wiadomości z Messengera.
W pierwszej części wpisu opisuję różne ciekawostki ze swoich danych.
W części drugiej opisuję różne przeszkadzajki, z którymi musiałem się uporać, żeby wyciągnąć te ciekawostki.
Część trzecia to link do skryptu, którego użyłem.
Wystarczy go pobrać i odpalić, żebyście również dla swoich danych stworzyli krótkie podsumowania.
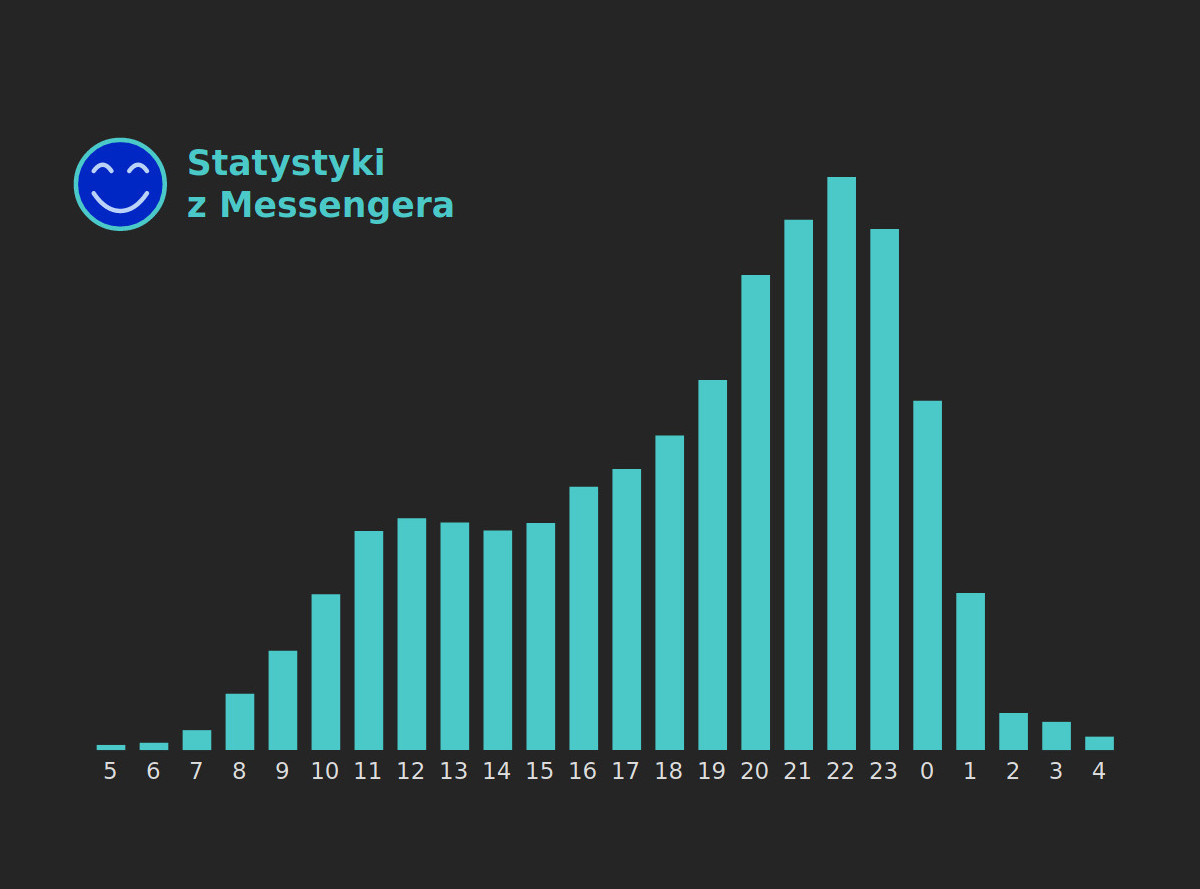
W tym taki sympatyczny histogram dla godzin, w których wysłaliście wiadomości:
 Porada
Porada
Jeśli interesuje Was tylko część z powyższych rzeczy, to możecie swobodnie do niej przeskoczyć. Są od siebie raczej niezależne.
Zanim zaczniemy, uprzedzę lojalnie: wpis nie zawiera popularnego w ostatnich latach data science. Głównie dlatego, że data science tworzy się na laptopach srebrnych, siedząc na pufie w pozycji kwiatu lotosu.
Ten wpis natomiast powstał na laptopie czarnym, głównie na meblach drewnianych i topornych. Jest tu tylko zwykła statystyka ze średnimi i medianami.
Nie odstraszyłem? To zapraszam do lektury!
Analiza
Moje statystyki są proste. Liczę różne rzeczy znajdujące się w wiadomościach, czasem patrzę jaki to procent wszystkich rzeczy.
Patrzyłem na kilka kryteriów:
- Długość wiadomości.
- Godziny wysłania wiadomości.
- Użyte ciągi emoji.
- Dodane załączniki.
- Otrzymane reakcje.
Przejdźmy do rzeczy!
Plik HTML z moimi statystykami znajdziecie tutaj.
Nie wstydzę się niczego, zresztą kto wie, czy to moje prawdziwe dane ![]() . Usunąłem z niego natomiast niektóre daty i listę ludzi dających reakcje.
. Usunąłem z niego natomiast niektóre daty i listę ludzi dających reakcje.
Parę ogólnych uwag:
Starałem się patrzeć na wartości względne. Co nam powie suchy fakt, że ktoś wysłał 1000 emot? Będzie to miało inne znaczenie, jeśli od takiej osoby mamy łącznie 2000 wiadomości, a inne, jeśli mamy ich 20 000.
Jeśli przedstawimy to jako procent od łącznej ilości, to łatwiej nam będzie porównywać.
Poza tym sprawdzałem tylko te osoby, od których mam tysiące wiadomości (zarówno z konwersacji pojedynczych, jak i grupowych). Im próba większa, tym wiarygodniejsza.
Czas na trochę poanalizowania siebie i innych.
Długość wiadomości
Niektórzy wyrzucają serie krótkich wiadomości jak z karabinu, dorzucając treść na bieżąco. Inni podchodzą do nich jak do maili i tworzą dłuższy blok tekstu.
Statystyka pozwala wyłapać te dwa przypadki.
Rozstrzał jest tutaj naprawdę spory. Od osób używających przeciętnie 6 słów na wiadomość do takich piszących całe elaboraty. A patrzymy na średnie z tysięcy wiadomości, więc to dość wiarygodne dane.
U osób bardziej zwięzłych wychodzi mi średnia 30-40 znaków i 5-6 słów na wiadomość.
Ja jestem z tych bardziej rozpisanych. średnio 99 znaków na wiadomość, mediana to 75.
(w czym jednak nie jestem wyjątkiem, bo jedna osoba miała niemal identyczne statystyki – jeśli to czytasz, A., to pozdrawiam! ![]() ).
).
Może też zastanawiać różnica między moją średnią a medianą. Gdybym pisał konsekwentnie wiadomości o podobnej długości, to średnia i mediana byłyby równe.
Tymczasem u mnie średnia jest o ponad 1/4 większa. Co to znaczy?
Widocznie miałem trochę wyjątkowo długich wiadomości (linki? Listy zakupów? Większe dramy?), które jednak nie są reprezentatywne.
Ze swoimi statystykami chowam się przy rekordzistce z medianą 104 znaków i 19 słów na wiadomość. Którą zresztą szanuję, bo te wiadomości to często fajne relacje z podróży!
Unikalnych słów użyłem ponad 64 000. Nie wierzyłbym temu bezgranicznie, bo jedno słowo potrafi się pojawić w wielu przypadkach (np. góra, górze, górom…).
Patrząc na to, że polskie słowniki potrafią liczyć po kilkaset tysięcy haseł w różnych odmianach, mam tu jeszcze sporo słów do zebrania ![]()
Godziny wysłania
Mam pełne informacje o datach i godzinach wysłania wiadomości. Skupiłem się na godzinach, żeby wyłapać wśród znajomych sowy i skowronki.
Zrobiłem tutaj wykresy częstości, żeby dało się porównywać dane – czyli ile procent wszystkich wiadomości wysłano o określonej godzinie
(gdybym brał suchą liczbę wiadomości, przytłoczyłbym innych. W końcu mam kilkadziesiąt tysięcy, a oni kilka).
W przypadku moich danych widać wyraźnie dwie górki. Mniejsza koło południa, mniej więcej po pełnym dobudzeniu. Druga w godzinach wieczornych i nocnych. To wtedy się uaktywniam.
Niektóre osoby są z kolei bardziej wyważone i można je dorwać o dowolnych godzinach w ciągu dnia.
Poniżej porównanie takich dwóch wykresów, mojego (u góry) i cudzego.
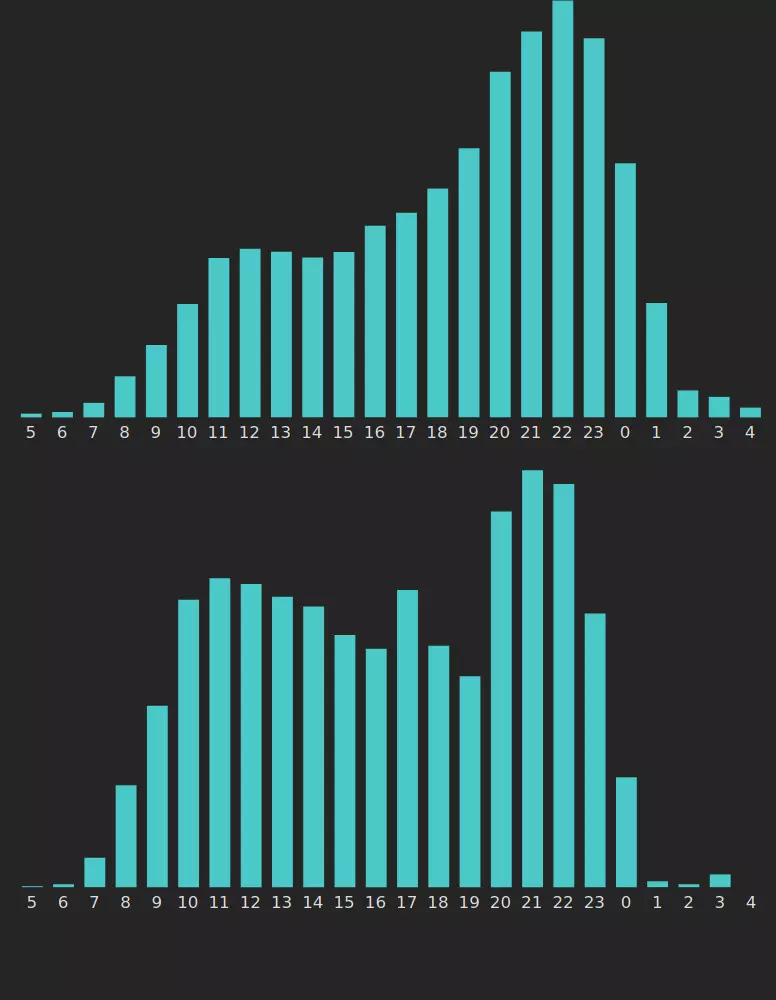
Ten drugi histogram by sugerował, że mam do czynienia ze skowronkiem, a nie sową. Rano ta osoba jest znacznie bardziej aktywna niż ja, ale po północy prawie nic nie pisze. Dla mnie północ jest jeszcze w miarę częsta, 1:00 się zdarza, a potem też się wyłączam.
Uwaga
Facebook nie podaje informacji o tym, z jakiej strefy czasowej wysłano wiadomość. Komputer oblicza godzinę wysłania na podstawie aktualnie ustawionej strefy.
Dlatego, gdybym teraz wyprowadził się do Australii, ustawił strefę australijską i wygenerował nowe podsumowanie, to wszystkie godziny byłyby przesunięte i nie oddawałyby rzeczywistości.
Dane dotyczące godzin od innych osób mogą być nieco skrzywione, bo zależą od mojego trybu życia. W końcu nie napiszę do kogoś, kiedy sam śpię! A zatem nie dostanę odpowiedzi, które by się liczyły do statystyk i np. pokazały, że ktoś często zarywa nocki.
Odrobinę tutaj pomagają konwersacje grupowe, ponieważ ludzie mogą pisać o różnych godzinach. I jeśli ktoś faktycznie nie śpi, to odpisuje, dając cenne punkty danych.
No i marzenie nadgorliwego menedżera – mając znacznik czasu, można łatwo sprawdzić, czy ktoś wysłał wiadomość w czasie pracy!
Wprowadziłem osobną statystykę: jaki procent wszystkich wiadomości został wysłany między poniedziałkiem a piątkiem i między 8:00 a 16:00? Zobaczymy, kto się messengeruje zamiast pracować!
U mnie wyszło 25%, z czego część zapewne w czasie wolnym. Nuuda.
Ale u rekordzistki to już 70,5%. Bez obaw, M., nie wypaplam nikomu.
Żeby dopracować metodę, mógłbym zebrać listę dni ustawowo wolnych i nie liczyć tego, co napisano w ich trakcie. Ale wciąż nie miałbym sposobu na odjęcie dni urlopowych, które mogą wypadać kiedykolwiek.
Natomiast, jeśli korpolobby zniesie kiedyś przepisy o ochronie danych, to mam taką wizję:
Facebook zakłada usługę Employee Productivity by Facebook.
Korpo w ramach subskrypcji mogą im wysyłać arkusze z grafikiem swoich pracowników sprzed jakiegoś czasu. A w odpowiedzi dostaną elegancki raporcik z informacją, ile wiadomości wysłały te osoby przez Messengera w czasie pracy.
Potem dowalą im jakieś review, coaching, Performance Improvement Plan albo immediate termination, w zależności od przewinienia.
Welcome to the future
Załączniki
W tych przypadkach, na które patrzyłem – w tym moim własnym – najczęściej do wiadomości dodaje się zdjęcia i naklejki. Bez większego zaskoczenia.
Ujawnia się natomiast moja awersja do filmów i GIF-ów, są rzadkie (pojawiły się odpowiednio 9 i 5 razy).
Jakoś nie przekonałem się do tych wszystkich Tenorów i innych bibliotek z GIF-ami. Jeśli wstawiam taki plik, to częściej skopiowany z przeglądarki.
W miarę często podrzucam za to pliki i linki do różnych rzeczy. Może dlatego, że na komputerze to kwestia paru kliknięć? A używam go częściej niż telefonu.
U niektórych te proporcje wyglądają zgoła odwrotnie – linki i pliki szorują po dnie, są najrzadszym załącznikiem.
Czy może to wynikać z faktu, że takie osoby częściej używają aplikacji na telefonie? Przez co dodanie linka wymagałoby od nich:
- wyjścia z Messengera,
- otwarcia przeglądarki i jakiejś strony,
- skopiowania linka (niektórzy nawet nie wiedzą jak!),
- ponownego otwarcia Messengera,
- wklejenia linka?
Linki mogą się nie lubić z telefonami. Taka hipoteza.
Wyszła mi też ciekawa rzecz – niektóre z moich starszych wiadomości, skądinąd całkiem zwyczajne i pozbawione załączników, program oznaczał jako „Nieznany rodzaj” (czyli nazwą, jaką zostawiłem dla nierozpoznanych).
Okazało się, że miały one atrybut ip zawierający… mój adres IP. Nie mam pojęcia, skąd się wziął i czemu akurat w tych wiadomościach. Sprawa do zbadania.
Reakcje i emoji
Małe obrazki uprzyjemniające rozmowę. Emoji możemy wstawiać w tekst swoich wiadomości, zaś reakcje „przypinamy” pod wiadomościami innych osób.
Aktualizacja, grudzień 2021: Kiedyś po reakcjach można było poznać, czy ktoś używa aplikacji Messengera! Wersja komputerowa pozwalała wstawić tylko jedną z 7, zaś aplikacja umożliwiała zareagowanie dowolną. Wniosek: jeśli ktoś użył niestandardowej, to używa apki.
Od lata/jesieni 2021 r. (dokładnie nie pamiętam) wersja komputerowa też daje możliwość reagowania dowolną emotą. Więc regułka sprawdzi się jedynie przy starszych wiadomościach.
Ciekawostka
Na początku zamiast emoji czerwonego serca jedną z kilku domyślnych reakcji była buźka z sercami zamiast oczu. Serce stopniowo ją wyparło.
Zatem, gdybyśmy wśród archiwalnych reakcji znaleźli serca w oczach, to nie musi oznaczać, że ktoś je specjalnie wybierał z listy. Po prostu mógł pisać w czasach, gdy niektórych jeszcze na świecie nie było. Sam na przykład zebrałem 224 sercookie reakcje.
Zresztą reakcje jako takie też są względnie nowe, pojawiły się w 2017 roku.
Kolejna ciekawostka: najwięcej zebrałem reakcji domyślnych (polubienie, śmiejąca się emota, serce, zdziwiona emota). Każda z nich pojawiała się kilkadziesiąt razy więcej niż te niestandardowe.
Mimo dostępu do pełnego przybornika z emotami, ludzie jednak trzymają się podstaw.
Tyle tytułem reakcji, przejdźmy do emoji w tekście.
W ich przypadku przede wszystkim można sprawdzić, jak często ktoś ich używa. Niektórzy dodają je notorycznie, a inni mają raczej alergiczny stosunek.
I tak rekordzistka z moich konwersacji używa emot w 70,4% wiadomości. U mnie też goszczą często, w 58,1%.
Kolejna sprawa to rozróżnienie między emotami „tekstowymi” (jak :D) a obrazkowymi, wybranymi z przybornika. Dokładniej to opisuję w dalszej części wpisu.
Jaskrawym przykładem jest jedna z moich znajomych, która użycie emot ma całkiem spore (637, w 62,5% wiadomości)… ale jest wśród nich dokładnie 0 emot obrazkowych. Wszystko wpisane z klawiatury.
Gdyby kiedyś zaczęła wysyłać obrazkowe, to jest ryzyko, że ktoś się podszywa ![]()
Kolejna rzecz? Powtarzalność. Można sprawdzić, kto lubi urozmaicenie i często daje różne kombinacje emot. A kto woli trzymać się kilku takich samych.
Osobiście nie mam duszy do eksperymentów. Na prawie 33 000 wysłanych ciągów emoji tylko 418 się nie powtarza.
Dla porównania bardziej emojionalna znajoma nabiła 219 unikalnych ciągów na 1815 wszystkich. Gdyby sprawdziła wszystkie swoje dane, to ta liczba na pewno jeszcze by wzrosła.
Niby zwykłe głupie obrazki, a ile radochy z analizy!
A samą analizę może na tym zakończę. Myślę, że pokazałem już, że nawet samo liczenie rzeczy, bez większych bajerów, może zdradzić ciekawe informacje i zwyczaje ludzkie.
Jeśli chcecie stworzyć taki sam raport dla siebie, to łapcie skrypt.
A jeśli ciekawią Was kulisy moich analiz, to czytajcie dalej.
Przygotowanie danych
Ułożenie folderów
Jeśli aktywnie używamy Facebooka, to wiadomości prawie na pewno będą największą częścią naszych danych.
Głównie przez różnego rodzaju obrazki. Nawet jeśli sami ich nie dodamy, to wystarczy spam w wykonaniu innych, żeby skrzynka szybko się rozrosła.
Jeśli zaznaczyliśmy na Fejsie, że chcemy w pakiecie z naszymi danymi pobrać też wiadomości, to w otrzymanym ZIP-ie znajdziemy folder messages.
W nim mamy pięć podfolderów:
| used |
folder z obrazkami dodawanymi do wiadomości jako tzw. naklejki |
| inbox | główny folder z konwersacjami |
| message |
konwersacje z facebookowej zakładki „Inne”. Czyli np. wiadomości od osób spoza grona znajomych, na które nie odpowiedzieliśmy |
| filtered |
taki śmietnik na te konwersacje, które sami wybraliśmy, żeby nam się nie wyświetlały. Stopień wyżej od wyciszenia |
| archived |
konwersacje, które opuściliśmy – wiadomości tylko do momentu odejścia |
W czterech ostatnich folderach znajdują się podfoldery. Każdy odpowiada jednej konwersacji i zawiera materiały dodatkowe (wysłane w tej konwersacji zdjęcia, GIF-y itp.). A także plik albo pliki w formacie JSON z wiadomościami wymienionymi w konwersacji.
To te pliki JSON analizujemy.
Budowa plików
Przypomnę krótko, czym jest Messengerowa konwersacja. Nie musi być prywatna, między dwiema osobami. Ma formę czatu. Można w dowolnym momencie dodawać nowe osoby albo opuszczać „pokój rozmów”. Każda z osób uczestniczących może dodawać tekst, pliki, nagrania głosowe itp.
Tak wygląda treść przykładowego pliku z konwersacją dwóch osób w formacie JSON:
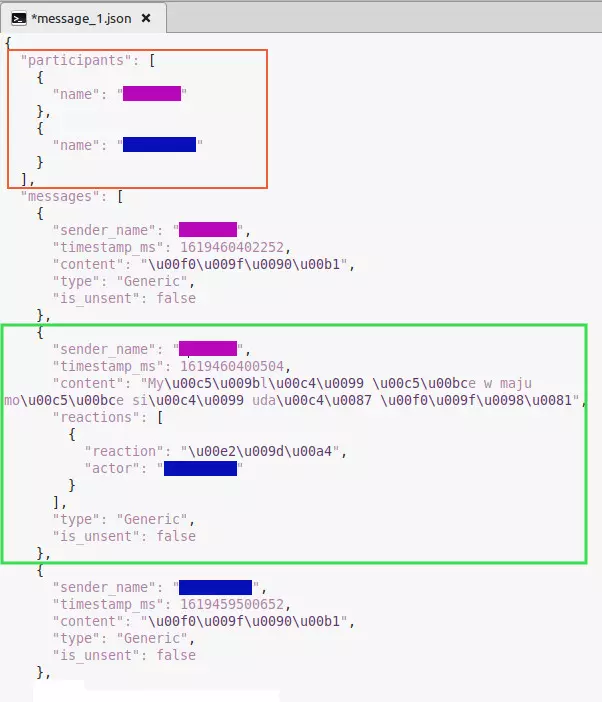
Nawiasy kwadratowe wydzielają proste listy, a nawiasy wąsate – tzw. słowniki (listy złożone z par nazwa-wartość). Te dwa rodzaje elementów mogą być w sobie zagnieżdżone.
W pliku są dwa najważniejsze elementy: participants (lista uczestników) i messages (wiadomości). Jest też parę innych rzeczy, ale nie znalazłem dla nich zastosowania.
Zieloną ramką otoczyłem przykładową wiadomość. Jej atrybuty to:
sender |
Kto wysłał wiadomość. |
timestamp |
Znacznik czasu; kiedy wysłano. |
content |
Tekst wiadomości. |
reactions |
Lista reakcji w formie emoji pod wiadomością. Każda z nich ma atrybut reaction (jaka to emota) oraz actor (kto ją wysłał). |
type |
Mówi, czy to wiadomość od kogoś czy komunikat od Messengera. |
is_ |
Czy wiadomość została usunięta. |
Oprócz tego niektóre wiadomości mogą mieć dodatkowe atrybuty (takie jak załączniki – zdjęcia, GIFY, pliki, nagranie itp.). Sam nie znam i nie znalazłem ich pełnej listy, więc eksperymentowałem.
Uczestnicy
Na początku wydawało się kuszące, żeby po wczytaniu pliku nie czytać wszystkiego i sprawdzić pod elementem participants, czy ktoś w ogóle tam pisał.
Niestety, jeśli ktoś opuścił konwersację, to go na tej liście nie będzie. A wiadomości takiej osoby pozostaną.
Dlatego dla pewności, zamiast patrzeć na listę spod participants, po prostu zbierałem wszystkie wiadomości i odczytywałem ich autorów.
Zatem sposób na jeden z dwóch głównych elementów to zignorowanie ![]()
A co z samymi wiadomościami? Każda zawiera kilka cennych elementów, które trzeba rozpracować na różne sposoby.
Daty
Elementy timestamp_ms to daty wysłania wiadomości. W takim dość popularnym formacie – jako liczba jednostek czasu, jakie upłynęły od punktu zero (ustalonego umownie na rok 1970).
Na odczytywanie dat ze znaczników czasu już znalazłem sposób w pierwszym wpisie, ale te są nieco inne. Tutaj mamy timestamp_ms. W milisekundach, a nie sekundach.
Zatem po prostu dzielę taką liczbę przez 1000, żeby przeliczyć na sekundy. A potem wrzucam do konwertera, domyślnie dostępnego w Pythonie. Otrzymuję datę wysłania wiadomości.
from datetime import datetime
# A przy czytaniu danych...
timestamp = data[ "timestamp_ms" ] // 1000
date = datetime.fromtimestamp( timestamp )
Emoji
Mogą pojawiać się zarówno w samym tekście wiadomości, jak i na liście otrzymanych reakcji.
Reakcje muszą być „prawilnymi” emoji z zamkniętej listy, więc nie sprawiają kłopotów. Pewien niuans pojawia się za to przy wiadomościach.
Z punktu widzenia użytkownika sprawa jest prosta. Korzystając z Messengera, wpisujemy skrót emoty z klawiatury (np. :P, :| itp.) albo wybieramy ją z przybornika. Emota się pojawia.
Okazuje się jednak, że Facebook zapisuje te dwie odmiany zupełnie inaczej.
Jeśli wpiszemy emoji jako skrót tekstowy, to właśnie tak zapisze się w pliku. Jeśli wstawimy jako obrazek, to w pliku JSON-a zapisze się kod odpowiadający emoji.
Poniżej przykład (z popsutym kodowaniem Facebooka):
| Co wstawiamy | Co widać | Co widać w danych |
|---|---|---|
| :D |  |
:D |
 |
|
\u00f0\u009f\u0090\u00b1 |
Heheszki
Na Messengerze da się zamiast domyślnego polubienia (kciuka w górę) ustawić własną emotę. Na przykład głowę kota z przykładu.
Jednak, jeśli klikniemy takie nietypowe polubienie, to w pliku z danymi będzie to wyglądało dokładnie tak, jak wiadomość mająca w treści tę jedną emotę.
Doszło przez to do ciekawej sytuacji. U jednego ze znajomych, pod pewnymi względami tradycjonalisty, najczęściej używaną emotą jest tęcza.
Dlaczego? Bo sam z siebie prawie nie dodaje emot obrazkowych. Za to w jednej konwersacji, z motywem „rzygania tęczą”, ktoś ustawił ją jako polubienie. Znajomy dał parę lajków i emota tęczy zdominowała mu statystyki ![]()
Jak się później okaże, rozróżnienie na emoty tekstowe i obrazkowe może być źródłem cennych informacji.
Ale bywa to też trochę uciążliwe. Żeby nie przegapić takich tekstowych emot, muszę znajdować ich listę w internetach, żeby potem je rozpoznawać w tekście.
Czasem te listy, takie jak ta, zawierają nieprawdziwe informacje (tu na przykład nie działa pingwin).
Kolejna sprawa to złożone emoty. Niektóre z nich, choć wydają się jednym obrazkiem, za kulisami składają się z kilku pomniejszych znaków.
To na przykład wszelkie emoty pokazujące postacie o jakimś odcieniu skóry. Tworzy się je przez połączenie emoty głównej z emotą odpowiadającą kolorowi. Jeśli ktoś wyśle ciemnoskórego kciuka w górę, to w danych wygląda to tak, jakby wysłał ogólnego kciuka, a zaraz po nim koło wypełnione ciemnym kolorem.
Na chwilę obecną nie rozwiązałem jeszcze tej sprawy. Znalazłem kod, który pozwala dokładniej grupować emoty, ale wymaga dodatkowego modułu Pythona (więc zdradziłbym ideę „pobierz i odpal”). Do tego działa raczej powoli. Dlatego póki co nastawcie się na rozszczepione emotki.
Ostatnia zagwozdka to dłuższe ciągi emoji. Liczyć każdy z nich jako osobną rzecz czy patrzeć tylko na emoty, z jakich się składa?
Jeśli ktoś używa dwóch rodzajów uśmieszków, ale urozmaica (raz da jeden, raz kilka identycznych, czasem wymiesza), to ma sztucznie zawyżoną liczbę. Bo często kilka emot pod rząd ma tylko zwiększać efekt (tak jak np. potrójny wykrzyknik w zdaniu).
Ale niektóre takie kombinacje mają specjalne znaczenie – choćby zestaw oko-usta-oko, który lubią młodsze pokolenia.
Gdybym chciał tu być perfekcjonistą, to bym musiał przechowywać listę takich specjalnych kombinacji. A i tak nie byłoby to stuprocentowo skuteczne.
Na szczęście poprzednia sprawa niejako narzuca rozwiązanie. Nie rozdzielam emoji, bo w obecnym stanie bym przez to rozbijał niektóre z nich na części. Patrzę na całe ich ciągi. Więc trzy uśmieszki jeden po drugim traktuję jak coś innego niż pojedynczy.
Tekst
Jesli chcę patrzeć tylko na liczbę znaków, to sprawa wydaje się prosta – główny problem to głupie Facebookowe kodowanie. Ale jeśli już go rozwiązałem, to wystarczy pewnie po prostu zgarnąć tekst?
I tak obecnie robię, ale jest tu wiele możliwości poprawy. Przede wszystkim, kiedy ktoś wrzuca długiego linka, a ja liczę go jako normalny tekst, tu sztucznie zawyżam długość wiadomości. Perfekcyjny analizator by zbierał i odsiewał linki z tekstu wiadomości.
Poza tym to, co w JSON-ie widnieje jako tekst wiadomości, bywa jedynie komunikatem.
„Dodałeś(aś) do konwersacji X”.
„Y opuścił(-a) grupę”.
Takie wiadomości szczególnie by nam nie psuły statystyk, bo są względnie rzadkie na tle całej naszej skrzynki. Mimo to postanowiłem je odfiltrować. Jeśli wiadomość ma atrybut users, to oznacza że jest interakcją. Wtedy jej tekst ustawiam jako alternatywny, a nie główny. Żeby się wyświetlał w trybie interaktywnym, ale nie wchodził do statystyk.
Żeby wyniki były odporniejsze na wahania, liczę dodatkowo medianę. Pojedyncze wahania w długości tekstu nie są w stanie jej oszukać, ponieważ patrzy tylko na wartości środkowe. Jeśli ktoś parę razy wrzucił wpis liczący tysiące znaków, to nic nie szkodzi.
Oprócz samych znaków patrzę również na słowa. Proces rozbijania zdania na części składowe, czyli tokeny, to tzw. tokenizacja i w żadnym razie nie jest prostą sprawą, jeśli chcemy mieć dokładność bliską 100%. Przykład:
- Na pewno chcemy rozbić zdania na spacjach, bo te rozdzielają słowa;
- …Ale gdyby dzielić tylko na spacjach, to zostałyby nam tokeny takie jak
sklep.ze zdaniajest tam taki sklep.zakończonego kropką. - Więc może na spacjach ORAZ kropkach, przecinkach, średnikach itp.?
- W tym przypadku zadziała, ale skróty takie jak m.in. rozbije na
morazin. Trzeba by mieć listę wyjątków, których nie dzielimy.
Dlatego dokładna tokenizacja wymaga dużo, bardzo dużo pracy. Albo pobrania cięższych modułów.
Ja poszedłem na łatwiznę i po prostu rozbijam na spacjach i popularnych znakach interpunkcyjnych. A potem biorę tylko te tokeny, które składają się wyłącznie z liter. Na koniec sprowadzam wszystko do małych liter.
import re
TOKENIZER_RE = re.compile('[.,;:()!?/*" ]+')
TOKENIZE = lambda text: TOKENIZER_RE.split( text )
# Później
all_words = [ TOKENIZE(text) for text in msgs_with_text]
all_words = [w.lower() for words in all_words for w in words if w.isalpha()]
Gubię w ten sposób liczby i nazwy własne (np. Dąb jako nazwisko i dąb jako drzewo skończą jako to samo słowo).
Ale wydaje mi się, że częściej jednak zyskuję, traktując je jako tę samą rzecz.
Ciekawostka
Mimo wszelkich trudności i tak mamy łatwiej niż Azjaci.
W przypadku języków chińskiego i japońskiego (może innych też?) nie ma przerw między znakami. Rozbijanie zdań na słowa wymaga czasem sprawdzenia wszystkich możliwych kombinacji, szeregowania ich według prawdopodobieństw itp.
Więcej o wyzwaniach związanych z chińskim jest na przykład tutaj.
Załączniki
To różne rzeczy specjalne dodawane do wiadomości. Mogą to być zdjęcia i inne grafiki, GIF-y, filmy, dowolne pliki, linki przekształcone na format Facebooka…
W ich przypadku po prostu przeglądałem dane, aż ustaliłem, jakim rzeczom odpowiadają określone atrybuty. Na przykład wiadomość z atrybutem sticker zawiera naklejkę (obrazek dodany z dostępnych kolekcji Facebooka), gif to plik GIF itp.
Na razie tylko liczę, ile rodzajów poszczególnych elementów ktoś wysłał. Ale mogę też kiedyś to rozwinąć i np. wyciągać z archiwum odpowiednie naklejki i dodawać do pliku HTML, żeby powstała lista najczęściej używanych.
Miałem tu również próbkę tego, że Messenger potrafi zmieniać swój format. Poprzednio pracowałem na danych pobranych kilka miesięcy temu. Od tego czasu Facebook wprowadził atrybut is_unsent, którego wcześniej nie było.
Efekt? Odpaliłem skrypt i wyszło mi, że najczęściej dodawana rzecz to “atrybut nieznany”. W liczbie równej liczbie wszystkich wiadomości. To mnie nauczyło, żeby nie wierzyć w niezmienność facebookowych formatów.
Indeksowanie
Problemy mniej więcej rozwiązane, działa! ![]()
Ale wszystko jest fajnie, dopóki ładuję tylko konwersacje, w których brałem udział (czyli de facto wszystko).
A co, jeśli chcę sprawdzić wiadomości dla innej osoby?
Wtedy jest sporo marnotrawstwa. Program ładuje i sprawdza wszystkie 700+ konwersacji, nawet jeśli wybrana osoba jest tylko w kilku.
Żeby trochę to poprawić, dodałem tzw. indeks. Przy pierwszym uruchomieniu program odwiedza każdą konwersację i tworzy listę osób, jakie brały w niej udział.
Potem zapisuje sobie w jednym miejscu (u mnie: do pliku index.json), w jakich plikach znajdzie wiadomości poszczególnych osób.
Teraz poszukiwania „rzadszych” osób są dużo szybsze! Wpisuję na przykład, że chcę wszystko od Adama Kowalskiego:
# Na końcu skryptu
name = "Adam Kowalski"
Komputer zagląda do indeksu, bierze listę plików, w których ta osoba coś pisała. Wczytuje dane jedynie z nich.
Porównajmy, ile czasu zajmują poszczególne przypadki:
| Stworzenie od zera indeksu dla 782 osób + wczytanie 705 konwersacji ze mną: |
5,73 s |
| Wczytanie z indeksu moich konwersacji (705): | 4,5 s |
| Wczytanie z indeksu konwersacji innej osoby (79): | 0,78 s |
Wszystko to na dość wątłym laptopie (Windows 10, 64-bitowy, Intel Core i5-3210M 2,5 GHz, 4 GB RAM).
Jak widać, mój bida-indeks trochę przyspieszył sprawy. Czasy i tak nie były jakieś drastyczne, nawet w najgorszym przypadku, ale zawsze to kilka zyskanych sekund życia. Jeśli chcemy analizować wielu znajomych, to oszczędność czasu będzie całkiem spora ![]()
Skrypt
A tutaj efekt moich prac, skrypt w Pythonie. Dzięki niemu możecie sprawdzić też swoje wiadomości. Albo te wiadomości od innych osób, które trafiły do Waszych wspólnych konwersacji.
Ten skrypt pozwala analizować wiadomości z Messengera. Wystarczy:
- Zainstalować Pythona (instrukcje w samouczku wyżej).
- Pobrać ten skrypt.
-
Pobrać swoje dane z Facebooka
Metodę opisałem w pierwszym wpisie z serii. Koniecznie wybieramy format JSON. Następnie umieszczamy skrypt w tym samym folderze co zipa z danymi. Nie trzeba go rozpakowywać.
- Odpalamy skrypt (instrukcje również w samouczku)
I gotowe! Skrypt przejrzy konwersacje i domyślnie wybierze osobę, która brała udział w największej liczbie (czyli zapewne Ciebie). W folderze powstaną trzy pliki:
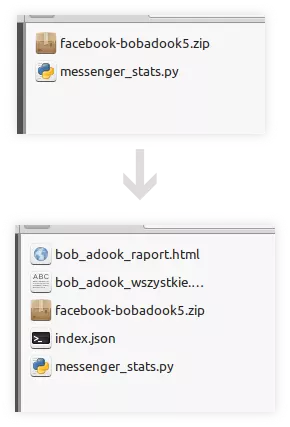
- Indeks w formacie JSON jest tu dla przyspieszenia wyszukiwań, nie musi nas interesować.
-
Plik tekstowy zawiera wszystkie wiadomości jednej osoby, ułożone w kolejności chronologicznej.
Można ten plik otworzyć w zwykłym notatniku i np. wyszukiwać w nim konkretne słowa, żeby zobaczyć, jak często ich używamy.
-
I najważniejsze – podsumowanie statystyk w formacie HTML. Kiedy klikniemy ten plik, powinien się otworzyć w przeglądarce.
Dla uspokojenia: plik nie łączy się z internetem i nigdzie nie wysyła Twoich informacji. Użyłem formatu HTML, bo był najmniej kłopotliwy, jeśli chodzi o dodanie obrazków i wyświetlanie emoji.
A co, gdybyśmy chcieli przeanalizować wiadomości od innej osoby, a nie od siebie? W takim wypadku otwieramy plik ze skryptem i zjeżdżamy na sam dół.
Tam możemy zmienić name="" na nazwę użytkownika, jaką tylko chcemy. Na przykład name="Justin Case" (pamiętamy o cudzysłowach!).
Skrypt poszuka wiadomości dla tego użytkownika i, jeśli coś znajdzie, również stworzy raport i listę chronologiczną.
Uwaga
Oprócz imienia najlepiej nic nie zmieniać w pliku, ani jednej spacji. Dla Pythona wcięcia mają duże znaczenie. Jeśli tekst nie będzie równo ułożony, może się wyświetlić SyntaxError. W takim wypadku, jeśli nie wiecie jak to naprawić, pobierzcie skrypt od nowa ![]()
Bonus: własne analizy
Moje analizy to tylko mały przykład tego, co da się zrobić! Jeśli chcemy – i znamy jakieś podstawy Pythona – możemy sami znaleźć ciekawostki w wiadomościach.
Można to zrobić nawet od razu po odpaleniu skryptu w IDLE. W pamięci pozostanie zmienna messages, czyli lista z wiadomościami. Możemy przy niej grzebać, na przykład sprawdzając jeszcze raz liczbę wiadomości…

Albo wiadomości zawierające reakcje…

Albo w ilu wiadomościach pojawia się słowo „piwo”…
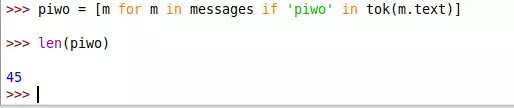
Dokładniej o tym ostatnim przypadku:
- zawsze dajemy
[m for m in messages], żeby przeczesywać listę wiadomości; - do tego na końcu możemy dodawać
if <WARUNEK>, żeby zbierać tylko część wiadomości - każda z wiadomości ma tekst, do którego „sięgamy”, wpisując
m.text. Dlatego możemy daćif "piwo" in m.text, żeby sprawdzić czy taki ciąg znaków jest w tekście; - ale uwaga! W ten sposób by znajdowało też wiadomości z innymi słowami, takie jak „piwonia” albo „spiwor” (śpiwór z literówką).
Dlatego rozbijam tekst funkcyjką pomocniczątok, która go dzieli na słowa.
Możemy też wyświetlać treść wiadomości, zadbałem o ich czytelne formatowanie. Aby je wyświetlić jedną pod drugą, możemy wpisać:
for m in piwo: print(m)
Tryb interaktywny ma jednak wady. Po pierwsze, po zamknięciu IDLE wyniki analiz znikną, o ile wcześniej nie zapiszemy ich do pliku.
Po drugie: zarówno IDLE, jak i PowerShell niezbyt dobrze radzą sobie z emoji. Ten pierwszy do niedawna wywalał błąd, ten drugi wyświetla kwadraty zamiast emot.
Co do błędów wyświetlania – najlepiej po prostu używać innego programu, wspierającego emoji. Na moim Linuksie (Mint) działa domyślny terminal. Na MacOS podobno też. W przypadku Windowsa można pobrać Windows Terminal.
Co dalej?
Jestem teraz w stanie wyciągać różne rzeczy z wiadomości z Messengera. Widzę dwa możliwe kierunki.
-
Trzymać się Messengera i pójść jeszcze bardziej w analizę tekstu.
Można spojrzeć na całe konwersacje – w ten sposób zobaczymy, ile ktoś zwykle wysyła wiadomości pod rząd, jak szybko pisze itp.
Poza tym analiza tekstu dopiero się zaczyna. Można otagować słowa jako rzeczowniki, skupić się na tych rzadziej występujących, na nazwach własnych, znajdować ludziom błędy ortograficzne sprzed lat ( )…
)… -
Rozbudować oś czasu z poprzedniego wpisu.
Skoro jestem w stanie odczytywać już wszystkie daty z facebookowych plików, to mogę rozwinąć poprzedni wpis i stworzyć wielką oś czasu. Wiadomości plus inne interakcje.
Będzie widać jak na dłoni, jeśli np. o czymś napisaliśmy, potem tego szukaliśmy na FB oraz innych stronach (na których FB też założył swoje „podsłuchy”), a potem napisaliśmy jeszcze innej osobie.
Obie rzeczy wydają się kuszące, którą by tu się zająć? Oczywiście:

Tak jest, oba tematy mnie ciekawią i oba chcę zbadać! ![]() Ale nie zdradzę Wam jeszcze, co będzie następne. Bo sam jeszcze nie wiem.
Ale nie zdradzę Wam jeszcze, co będzie następne. Bo sam jeszcze nie wiem.
A póki co – do zobaczenia i wypatrujcie kolejnych wpisów!
Był to wpis z serii Kochajmy się jak bracia, analizujmy się jak Facebooki