
Jak piszesz? Zapytam Messengera
Liczę średnią szybkość pisania i wyłapuję błędy ortograficzne.
Wpis z serii Kochajmy się jak bracia, analizujmy się jak Facebooki
Witam Was w pierwszym wpisie w nowym 2022 roku! I zarazem kolejnym poświęconym analizowaniu danych z Facebooka.
(Ich nadrzędna spółka to teraz Meta, ale będę używał starej nazwy, bo jakoś trudno się przestawić. Tak jak z Woodstockiem i Pol’and’rockiem).
Sporo czasu minęło od poprzedniego wpisu z tej serii, więc przypomnę jej cel.
Chodzi tutaj o to, że pobieram z portalu Facebook dane na swój temat (korzystając z opcji, którą udostępnili; zapewne pod presją GDPR/RODO). Następnie amatorsko je analizuję i wypatruję ciekawostek.
Jeśli nawet laik ze skryptem Pythona wyłowi ciekawe informacje, to co o nas wiedzą w samym Facebooku?
W poprzednim wpisie skupiłem się na liczeniu podstawowych statystyk dla wiadomości z Messengera. Głównie swoich, choć odczytałem też ciekawe rzeczy o osobach, z którymi najwięcej piszę.
Patrzyłem między innymi na przeciętną długość wiadomości, godziny ich wysłania, używane w nich emoty.
Tym razem skupię się na dwóch nowych rzeczach.
- Wyłapię „ciągi” złożone z kilku wiadomości pod rząd. W przypadku niektórych z nich pozwoli to liczyć czyjąś przybliżoną szybkość pisania, a nawet wychwytywać wiadomości wklejone.
- Poza tym użyję publicznie dostępnych list słów – a nawet książki „Znachor” i paru innych – żeby znajdować potencjalne błędy ortograficzne

Pod koniec wpisu znajdziecie nową wersję skryptu, dzięki któremu możecie przeprowadzić takie analizy również na własnych danych.
Ruszajmy!
Spis treści
- Analizowanie ciągów wiadomości
- Wyłapywanie błędów ortograficznych
- Podsumowanie
- Bonus: skrypt do analiz
Analizowanie ciągów wiadomości
Ciąg wiadomości rozumiem jako co najmniej jedną wiadomość pod rząd, wysłaną przez jedną i tę samą osobę. Takie combo.
Na pierwszy rzut oka nie daje nam to wielu dodatkowych informacji w porównaniu z patrzeniem na same wiadomości. Ale spójrzmy chociażby na tego mema!
Obrazek z gatunku luźnych odmóżdżaczy. Takich, jakie wrzuca się na spamowe stronki, żeby ludzie oznaczali się w komentarzach, kwitując sprawę ambitnym „haha” albo roześmianymi emotami.
A jednak ma w sobie trochę prawdy – liczba wiadomości słanych pod rząd to mocny wyznacznik stylu pisania.
Jeśli ktoś raz wykształci określony styl, to raczej nieprędko się go pozbędzie. Wniosek: to cecha, którą by można korelować z innymi, żeby klasyfikować ludzi.
Przeciętną długość wiadomości (mierzoną w słowach i znakach) analizowaliśmy już w poprzednim wpisie.
Liczba wiadomości wysłana pod rząd to drugi element układanki. Razem pozwoliłyby określić czyjś styl pisania – czy zwykle podchodzi do wiadomości jak do maili, wysyłając dłuższe bloki? Czy może raczej „strzela krótkimi seriami”?
Zobaczę, jak z tym u mnie!
Liczba różnych ciągów wiadomości
Poprzednia wersja mojego programu nie była zbyt przystosowana do wychwytywania ciągów wiadomości, bo szukała tylko tych od jednej konkretnej osoby, bez patrzenia na resztę.
Obecnie, po zmianach, działa w następujący sposób:
- Bierze wszystkie konwersacje, dwuosobowe i grupowe, w których brała udział jakaś osoba;
-
Po kolei „przejeżdża” wzdłuż konwersacji, patrząc na autorów wiadomości.
Jeśli znajdzie poszukiwaną osobę, to zaczyna tworzyć nowy ciąg.
Dodaje do niego wiadomości, dopóki to ta sama osoba je napisała.
Jeśli napotka wiadomość wysłaną przez kogoś innego, to znaczy że ciąg został przerwany. Można go odłożyć do osobnej listy. - Po zebraniu wszystkich ciągów ze wszystkich konwersacji bierze się za ich analizowanie.
Skorzystałem z tego samego zestawu danych co przy poprzednim wpisie, bo nie chciało mi się pobierać nowych. Mam zatem zbiór ponad 50 000 wiadomości napisanych na przestrzeni ponad 9 lat.
Mając różne ciągi, można sobie stworzyć wykres ilustrujący, jak często się pojawiają. Ten dla moich wiadomości wygląda tak:
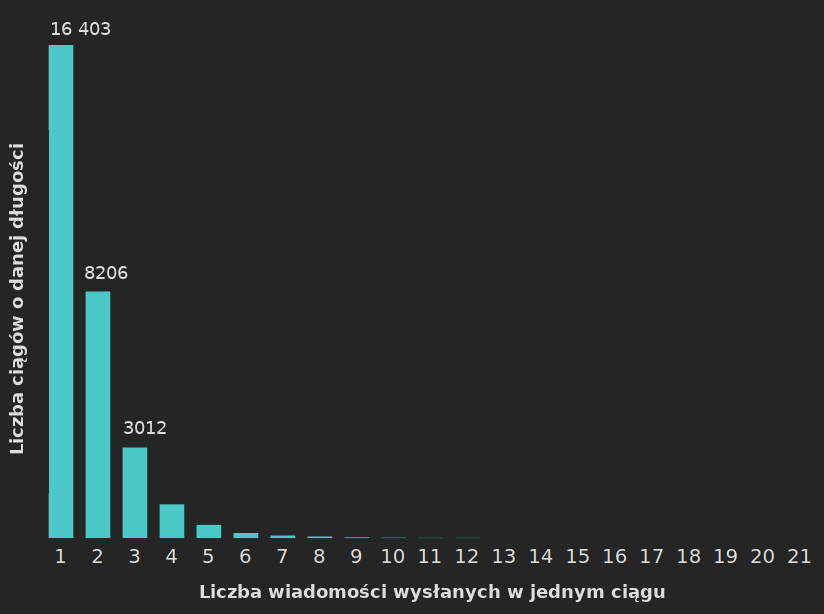
Wykres dla liczby ciągów o różnej długości. Podpisy osi i kolumn dodałem w osobnym programie.
Najdłuższych ciągów jest mało w porównaniu z krótszymi, więc są w tej skali nieczytelne. Poniżej macie ich liczbę (w formacie długość ciągu: liczba takich ciągów).
Moim rekordem jest ciąg złożony z 21 wiadomości wysłanych pod rząd – swoista relacja z podróży wrzucana do grupowej rozmowy (zdjęcia wymieszane z tekstem).
Patrząc na wykres, zauważymy pewną rzecz, która wydaje się dość naturalna – im dłuższy jest ciąg wiadomości, tym rzadziej się pojawia.
Takie „stopniowe wygasanie” jest czymś bardzo powszechnym w statystyce, w naturze zresztą też. Zainteresowani mogą poczytać o rozkładach wykładniczych.
Mając ciągi wiadomości, można zrobić kolejny krok!
Szybkość pisania
Ilość tekstu, jaką ktoś jest w stanie stworzyć w określonym czasie. Wyrażana w znakach na minutę, słowach na minutę albo innych przekształconych jednostkach.
Uznałem, że to dość ciekawa statystyka. Może być czyjąś cechą charakterystyczną, podobnie jak sama tendencja do tworzenia krótkich bądź długich wiadomości.
W poprzednim punkcie patrzyłem na wszystkie ciągi wiadomości – niezależnie od tego, czy zawierały tekst, obrazki, nagrania czy inne załączniki z Messengera.
Tym razem interesuje mnie tylko tekst, więc podzieliłem ciągi na krótsze, wycinając z nich wszelkie wiadomości z załącznikami.
Poza tym wywaliłem też ciągi złożone z jednej wiadomości. Znam tylko godziny ich wysłania, a chcąc określić szybkość muszę również wiedzieć, kiedy ktoś zaczął je pisać.
W ten sposób moim materiałem źródłowym stały się ostatecznie ciągi złożone z co najmniej dwóch wiadomości tekstowych napisanych przez tę samą osobę.
Czas wysłania pierwszej z nich przyjmuję za punkt początkowy. Przy każdej kolejnej, dzieląc jej długość przez czas, jaki minął od wysłania poprzedniej, mogłem ustalić czyjąś szybkość pisania. Oczywiście w przybliżeniu.
…Ale pozostaje pewien ważny szczegół! Zobaczmy na żywym przykładzie:
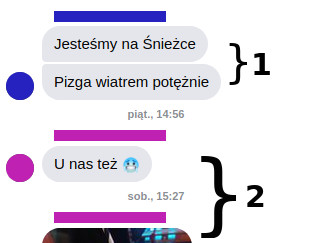
Mamy tu dwa ciągi wiadomości, oznaczone jako 1 i 2.
Ciąg 1 jest w porządku, bo sprowadza się do jednej myśli rozbitej na dwie wiadomości. Można założyć, że autor zaraz po wysłaniu pierwszej zaczął pisać kolejną. A zatem: da się tu zmierzyć szybkość pisania.
Z kolei ciąg 2 jest bardziej problematyczny – są to niby wiadomości od tej samej osoby, ale wysłano je w różnych dniach (pomińmy już to, że druga z nich to obrazek).
Wyobraźmy sobie ciąg złożony z dwóch wiadomości, z których druga brzmi „To jak?”. Czyli ma 7 znaków, licząc spację i znak zapytania.
Gdyby została wysłana 2 godziny (120 minut) po pierwszej, to by nam wyszło 7/120, czyli szybkość około 0,06 znaku na minutę!
Sami przyznacie, że nie do końca oddawałoby to rzeczywistość.
Dlatego musiałem przyjąć jakiś umowny zakres i odrzucać wartości spoza niego jako zbyt szybkie albo zbyt wolne, żeby moje średnie były nieco bardziej wiarygodne. Ostatecznie za normę przyjąłem zakres od 100 do 400 znaków na minutę.
Skąd górna wartość? Zasugerowałem się losowym wpisem o szybkości pisania na klawiaturze. Znaczna większość badanych, w tym zawodowcy, nie przekraczała szybkości 80 słów na minutę (czyli właśnie 400 znaków, bo popularny przelicznik to 1 słowo = 5 znaków).
A minimum? Musiałem tu wziąć pod uwagę osoby piszące z urządzeń mobilnych, w tym niekoniecznie z wprawą.
Ktoś zapytał o to na forum Quora. Według osoby ponoć zajmującej się tematem zawodowo, przeciętna szybkość pisania na mobilnych to 25-30 słów na minutę. Czyli 125-150 znaków.
Bardziej niż średnia interesowało mnie minimum, więc asekuracyjnie przyjąłem 100 znaków.
Wszystko to oczywiście subiektywne decyzje; poza tym nie uwzględniam czasu potrzebnego na wstawienie emotek z przybornika. Jak to mawiają: „Kiedyś jeszcze dodam nowe funkcjonalności” ![]()
Może i prowizorka, ale działa! Na podstawie moich wiadomości mieszczących się w zakresie pokazuje mi, że piszę ze średnią szybkością 184 znaków na minutę.
Liczba nie powala, być może przez to, że to miks danych dla klawiatury i smartfona. Ale myślę, że nie jest jakoś bardzo odległa od rzeczywistości.
Liczba wiadomości wklejonych
Wartości spoza przyjętego zakresu (w znakach na minutę), choć nie są liczone do średnich, nadal mogą nam coś ujawnić!
Wartości skrajnie niskie, oznaczające długie odstępy czasu między wiadomościami, nie wydają się aż takie ciekawe. Wpadłby tutaj każdy przypadek, kiedy jakaś osoba najpierw napisała „Do usłyszenia”, a ileś dni później sama napisała.
Ciekawsze wydają się wartości skrajnie wysokie. Co to znaczy, że ktoś nagle wyprodukował wiadomość w tempie kilku tysięcy znaków na minutę, zawstydzając stenotypistów?
Odpowiedź: w takim przypadku ktoś zapewne wkleił treść wiadomości. Jedno Ctrl+V, potem Enter i mamy dowolnie długi tekst w bardzo krótkim czasie.
Odkryłem, że w moich wiadomościach najczęściej wklejanym długim tekstem były linki i cytaty. Raczej małe zaskoczenie.
Druga możliwa przyczyna – czasem pisałem coś dłuższego, ale jakaś osoba weszła mi w słowo. Wyciąłem pisaną wiadomość, wpisałem krótką odpowiedź na sprawy bieżące, a zaraz po niej wkleiłem poprzednio tworzony tekst, żeby wrócić do wątku.
Trzecia przyczyna – ktoś mogł specjalnie tworzyć wiadomości „na brudno”, w osobnym programie, i dopiero potem przeklejać je do czatu/Messengera.
Sam tak nie robiłem, ale wypatrzyłem parę przypadków u innej osoby – w momencie, w którym zrobiło się poważnie i zaczęły lecieć ściany tekstu.
Wyłapywanie błędów ortograficznych
Krok 1: wyłapywanie najczęstszych błędów
Chcę znajdować błędy w języku polskim, powszechnie uważanym za trudny przez swoją sporą elastyczność i możliwość odmieniania słów (tak zwaną fleksyjność).

Źródło: konferencja Euro Clojure 2016.
{kind=link}
Do tego chcę to zmieścić w jednym prostym skrypcie; fajnie też, żebym nie wymagał od użytkowników pobierania gigabajtów dodatkowych słowników. Brzmi jak wyzwanie ![]()
Uznałem, że na początek skupię się na najczęściej popełnianych błędach – takich jak nieszczęsne pisanie wogóle zamiast w ogóle.
Skrypt, nim zrobi coś sprytniejszego, po prostu przejrzy tekst wiadomości i poszuka konkretnych błędów z zamkniętej listy.
Listy najczęstszych błędów w internecie można znaleźć na różnych stronach; osobiście skorzystałem z tej ze strony polszczyzna.pl.
Wprowadzenie listy do skryptu poszło dość szybko. Ale czułem niedosyt. Fajnie by było mieć coś ogólniejszego.
Krok 2: znajdowanie nieznanych słów
Już w poprzednim wpisie znalazłem przybliżony i mocno niedoskonały sposób, żeby rozbijać wiadomości na słowa, z jakich się składają. Teraz czas trochę za te słowa pochwytać ![]()
Zacznijmy od podstawowej kwestii: potrzebujemy jakiejś zamkniętej, w miarę sporej listy słów języka polskiego. Będzie pełniła rolę wstępnego sita, odsiewającego słowa poprawne od niepoprawnych.
Jako swojej głównej listy użyłem tej ze strony Słownika Języka Polskiego.
Po rozpakowaniu stosunkowo małego pliku ZIP (12 MB) otrzymujemy plik tekstowy ważący 67 MB, wypełniony po brzegi polskimi słowami i wyrażeniami!
Ale, żeby nie było zbyt pięknie, część z nich wydaje się dość niszowa:
ab Urbe condita
ab urbe conditia
aba
ABA
abachit, abachicie, abachitach, abachitami, abachitem, abachitom, abachitowi, abachitów, abachitu, abachity
Abacja, Abacją, Abację, Abacji, Abacjo
Abadan, Abadanem, Abadanie, Abadanowi, Abadanu
Nie ma tam natomiast popularnych polskich słów-zapychaczy. Jednoliterowców takich jak i, w, a, wielu spójników i innych części mowy. Czyli akurat tego, co na pewno się pojawi w każdej rozmowie między ludźmi ![]()
Dlatego ta lista to jednak odrobinę za mało. Żeby wypełnić lukę, zacząłem szukać kolejnego źródła. Interesował mnie język bardziej nieformalny i konwersacyjny, ale przy tym poprawny, więc wszelkie bazy twittów i tym podobnych odpadały.
Zaświtało mi: a może coś z książek? Znalazłem serwis „Wolne lektury”, a stamtąd wziąłem kilka książek w formacie TXT. Były to:
- „Ziemia obiecana”,
- „Znachor”,
- „Kariera Nikodema Dyzmy”.
Dwie książki Dołęgi-Mostowicza były moim subiektywnym wyborem, bo je lubię. Ale decyzja była częściowo pragmatyczna – to jedne z najnowszych książek w zasobach. Z dwudziestolecia międzywojennego, do tego uwspółcześnione. Język powinien być zbliżony do tego stosowanego współcześnie.
A nawet gdyby zaplątały się jakieś archaiczne słowa, to mogłoby to tylko wyjść na dobre! Pamiętam ze swoich rozmów na czacie, że czasem odpowiedzią na „Chodźmy się napić” bywało „Dobrze waszmość prawisz”.
Format TXT idealnie się nadawał do szybkiego załadowania tekstów i rozbicia ich na słowa. Tak też zrobiłem, otrzymując swoją uzupełniającą listę słów. Do skryptu dodałem możliwość ładowania wielu list, żeby jeszcze łatwiej było rozszerzać w przyszłości jego możliwości.
 Heheszki
Heheszki
Korzystanie z książkowych źródeł miało pewien efekt uboczny – otóż autorzy bywają kreatywni w wymyślaniu neologizmów. I tak oto na mojej liście, między całkiem zwyczajnymi i pospolitymi słowami, znalazło się elektryczno-homeopatyczno-wegetariańsko-arszenikowej:

W moich konwersacjach z Messengera niestety nie pojawiło się ani razu.
Po załadowaniu obu list skrypt zaczął działać nieco sensowniej. Nadal zdarza mu się oznaczać całkiem normalne słowa jako dziwne, ale do wstępnego przesiewu, którego wynik sami ocenimy, jest w porządku. Wypatrzyłem dzięki niemu trochę swoich literówek (takich jak sobocir zamiast sobocie, symie zamiast sumie).
Oczywiście żadna z moich list słów by się nie sprawdziła przy słowach bardziej niszowych, takich jak terminologia związana z komputerami. Albo przy nowinkach jak „śpiulkolot” (młodzieżowe słowo roku 2021).
Krok 3: znajdowanie innych błędów ortograficznych
Znajdowanie słów spoza listy znanych to dobry pierwszy krok, ale sam w sobie nie rozwiązuje sprawy.
Jak widzieliśmy, wyniki trzeba oceniać na oko, żeby coś w nich znaleźć. Czasem na listę podejrzanych trafią rzeczy całkiem prawidłowe.
Ale pomyślałem sobie: w niektórych miejscach błędy pojawiają się częściej niż w innych. Zwłaszcza tam, gdzie różnym zapisom odpowiada ta sama wymowa. Ch zamiast h, rz zamiast ż i tak dalej.
Stąd pomysł: dla każdego słowa uznanego za nieznane sprawdzę różne warianty pisowni. Jeśli jakieś słowo nie znajduje się na liście, ale jego wariant z innym zapisem już tak, to mamy mocnego kandydata na błąd ortograficzny.
Spójrzmy na przykład na dwa błędnie zapisane słowa – chex i chandel. Pierwsze powinno brzmieć Hex, od nazwy gry planszowej, a drugie – handel.
- W obu przypadkach skrypt odkrywa, że słowa nie ma na liście znanych;
- Wypatruje w każdym ze słów często mylonych cząstek, znajduje ch;
- Zamienia je na wariant z samym h i patrzy, czy taka wersja by była na liście;
-
Handel jest na liście. W związku z tym skrypt uznaje chandel za błąd ortograficzny.
Z kolei Hex się na liście nie znajduje, bo raczej niewiele jest na niej obcych słów. W związku z tym chex pozostaje zwykłym nieznanym słowem – wśród literówek i słów, które trafiły tam przypadkiem.
Rezultaty najgorsze z naszego punktu widzenia – gdy skrypt zamiast prawidłowo zapisanego słowa zaproponuje wersję z błędem – powinny być raczej rzadkie (ale możliwe; poniżej napisałem o tym ciekawostkę).
Częstszym przypadkiem będzie zaliczenie błędu ortograficznego do zwykłych słów nieznanych. Ale takie działanie, choć nie idealne, nie jest jakimś wielkim problemem.
A gdy już metoda działa, to działa – wyłapuje niektóre współczesne koszmarki, takie jak „ludzią” zamiast „ludziom”.
Ciekawostka
Póki nie udoskonaliłem listy o słowa z książek, potrafiło dochodzić do śmiesznych sytuacji. Przykład: komputer z całym autorytetem próbował mi wmówić, że zamiast „są” powinienem pisać „som”.
Wynikało to z faktu, który wcześniej opisałem – na liście z SJP nie było wielu powszechnych słów, w tym „są”. Były z kolei niszowe rzeczowniki. „Som” to dopełniacz słowa „soma”, oznaczającego po grecku „ciało”.
Pytanie, skąd się toto wzięło na liście słów polskich. Obstawiam jakieś biblijne zapożyczenia, ale pewności nie mam.
Podsumowanie
Patrząc na te analizy, ktoś mógłby wzruszyć ramionami i zapytać mnie: „Po co?”.
Dla frajdy! Robienie tego było fajną odskocznią na te niby-to-zimowe popołudnia i wieczory, dało mi niemało endorfin. Na tej odpowiedzi możemy poprzestać, bo wyjaśnia wszystko.
Ciekawszym pytaniem byłoby dla mnie to z motywu przewodniego tej serii: „Co wie o nas Facebook?”.
Nie twierdzę, że też nam liczy szybkość pisania czy liczbę błędów. Patrząc na to, jak mu czasem idzie odmienianie polskich imion i nazwisk, nie uważam go za materiał na korektora ![]()
Ale tak naprawdę nie wiemy, co tam za kulisami robi.
Korzysta z elastycznych algorytmów, ściślej nazywanych uczeniem maszynowym, a marketingowo – sztuczną inteligencją. I prawie na pewno, upychając nas w odpowiedniej przegródce dla reklamodawców, uwzględnia treść naszych wiadomości.
Łącząc wielkie zbiory tekstu z Messengera z historią innych naszych działań, może sobie wyliczać korelacje.
Nie mamy pewności, czy nasze krótkie, rwane i czasem niegramatyczne wiadomości nie będą ostatnią kroplą, która przeleje czarę i przerzuci nas do klastra numer 1237 (liczby wymyślam). Który będziemy dzielili raczej z patologią.
A to może oznaczać, że Fejs będzie nam wciskał reklamy tandety, chwilówek i patostreamów. Ilekroć odwiedzimy swój profil albo strony zaprzyjaźnione z FB.
A może mówię stereotypami? A nasze krótkie, szybkie i niegramatyczne wiadomości skorelują w oczach Fejsa ze sławą i biznesem, profilami kadr menedżerskich?
Trafimy do klastra numer 1337. Będzie nam wciskało reklamy markowej tandety, kredytów mieszkaniowych i sesji coachingowo-lifestyle’owych.
A może raz ten klaster, raz ten? W zależności od fazy księżyca w dniu, kiedy algorytmy podejmowały decyzję?
W tym sęk – bardzo mało wiemy o tym, w jaki sposób Facebook nas klasyfikuje. Mogę tylko teoretyzować na temat mechanizmu, jakim się kieruje. Ale wiemy na pewno, że efekt końcowy tych klasyfikacji potrafi być nieprzyjemny.
Na chwilę zostawię Messengera w spokoju. Zapewne wrócę z bardziej złożonymi metodami, takimi jak analiza składniowa albo analiza sentymentu (tzn. patrzenie na ogólny bilans pozytywnych i negatywnych zwrotów w różnych wiadomościach).
Ale do tego czasu zajmę się innymi aspektami naszych (a może już Facebooka?) danych. Do zobaczenia w kolejnych wpisach!
Bonus: skrypt do analiz
To bezpośrednie rozszerzenie mojego poprzedniego skryptu, więc działa niemal identycznie – po prostu tworzy więcej statystyk i plików z dodatkowymi informacjami.
Aktualizacja 25.01: Naprawiłem i poprawiłem parę rzeczy, ładowanie list słów powinno teraz działać również na Windowsie.
- Instalujecie Pythona, jeśli jeszcze go nie macie.
- Pobieracie swoje dane z Facebooka, sposobem chociażby z mojego wpisu. Pamiętajcie, żeby zaznaczyć wśród rzeczy do pobrania swoje wiadomości.
Możecie je rozpakować albo pozostawić w pliku ZIP. - Pobieracie nową wersję mojego skryptu i umieszczacie go w tym samym folderze co wiadomości.
- Pobieracie listę słów od SJP. Rozpakowujecie ZIP-a w tym samym folderze, w którym jest skrypt.
- Pobieracie plik ZIP z moją listą uzupełniającą. Również rozpakowujecie go tam gdzie skrypt. Do powstałego folderu
MY_WORDLISTSmożecie wrzucać własne listy słów
(o ile są plikami tekstowymi, a słowa są w osobnych linijkach lub oddzielone od siebie przecinkami). -
Otwieracie plik ze skryptem, korzystając na przykład z domyślnego edytora IDLE. Odpalacie go (w przypadku IDLE klawiszem
F5).W domyśle skrypt przeanalizuje wiadomości osoby, która brała udział w największej liczbie konwersacji. Czyli zapewne Wasze.
-
W folderze powstanie podfolder nazwany od analizowanej osoby. A w nim kilka plików.
Najważniejszy to raport w formacie HTML zawierający różne statystyki dotyczące Waszych wiadomości (po kliknięciu zapewne otworzy się w przeglądarce, ale bez obaw, niczego nie wysyła do internetu!).
Oprócz tego w osobnym podfolderze znajdziecie kilka plików tekstowych: wszystkie wiadomości ułożone chronologicznie, listę słów nieznanych, listę potencjalnych błędów ortograficznych, listę szybko napisanych wiadomości.
…A jeśli, zamiast własnych, chcecie sprawdzić wszystkie wiadomości od konkretnej osoby, z którą pisaliście, to wpisujecie jej nazwę użytkownika (np. Jan Jakiś) pod koniec skryptu, przy zmiennej name, między cudzysłowami.
Miłego łapania ludzi za błędy sprzed lat! (Z nadzieją, że sami ich nie popełniacie. Kocioł garnkowi, drzazga w oku i te sprawy ![]() ).
).
Był to wpis z serii Kochajmy się jak bracia, analizujmy się jak Facebooki