
Internetowa inwigilacja 9 – JavaScript, cz.1
„Na pewno mówisz prawdę?”
Wpis z serii Internetowa inwigilacja
W większości wpisów z serii „Internetowa inwigilacja” pisałem o tym, co wysyła nasza przeglądarka przy każdym kontakcie z właścicielami odwiedzanych stron. Zanim w ogóle otrzymamy „zamówioną” stronę internetową.
A teraz – po ponad roku, odkąd zacząłem pisać – ta strona wreszcie do nas dotarła. Ładna, współczesna, animowana. Interaktywna.
Ta interaktywność potrafi jednak być pułapką. Za kulisami często odpowiada za nią JavaScript – język programowania internetu.
Który ma różne sposoby, żeby wybadać kim jesteśmy. Sprawdzić, czy wysyłane przez nas informacje zgadzają się z rzeczywistością. A na koniec powiadomić o swoich wnioskach stronę-matkę.
To bardzo złe wieści dla naszej prywatności, ale całkiem niezłe dla tych czytelników, którzy już czuli rutynę. JavaScript przynosi dużo nowości, egzotyki, nietypowych metod śledzenia. Poznajmy go!
Bardziej kreatywne zastosowania zostawię na kolejne wpisy, a teraz zobaczymy prostsze informacje. Taki wpis przejściowy.
Ale niech was to nie zwiedzie. Nawet pierwszy rzut oka na możliwości JavaScriptu może wystarczyć, żeby zrobiło nam się odrobinę nieswojo.
JavaScript w kontekście
Wróćmy na chwilę do naszej analogii pocztowej, przewijającej się przez całą serię. Streszczając:
- Nasza przeglądarka jest jak poczta; my tylko mówimy, z kim się chcemy skontaktować, a oni wszystko ogarniają za kulisami.
- Jeśli chcemy otrzymać od kogoś odpowiedź (stronę internetową), musimy najpierw sami wysłać list z prośbą.
- Na każdy taki list jest naklejona etykieta/wizytówka z podstawowymi informacjami na nasz temat (nagłówki HTTP).
Widnieje na niej nasz pseudonim (user agent), adres (adres IP) i parę innych bajerów. - Możemy otrzymać odpowiedź w formie listu lub paczki z dowolną zawartością. Może tam być między innymi JavaScript.
Ten JavaScript to często niegroźny interaktywny gadżet. Otrzymamy go i zostaje z nami. Tak jak wbudowana pozytywka z niektórych kartek z życzeniami, która potrafi grać melodyjkę.
Czasem jednak trafi się „zły” JavaScript. Na przykład taki, który jest w stanie wysyłać nasze dane osobie, od której go dostaliśmy. Bez naszej zgody i wiedzy.
Gdybyśmy szukali analogii z życia, to można traktować go jak AirTaga lub innego rodzaju nadajnik śledzący, wysyłający komuś naszą lokalizację. Albo tresowanego gołębia pocztowego, który po otwarciu klatki podkrada nam coś z biurka i leci z tym do swojego właściciela.
Dla wzrokowców naszykowałem parę schematów. Na początku mamy normalną, zdrową komunikację. Po lewej nasz laptop, po prawej serwer.
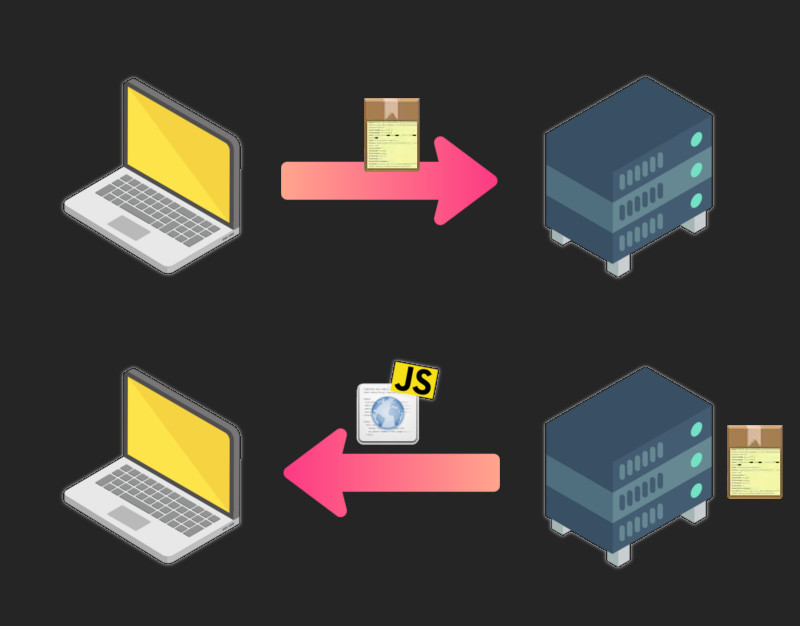
Ikonki z serwisu Flaticon: laptop autorstwa vectorsmarket15, serwer autorstwa Smashicons, strzałka autorstwa Freepik. Aranżacja moja.
Dostaliśmy stronkę w zamian za wizytówkę/etykietę z podstawowymi danymi. Można lekko kręcić nosem, bo z poprzednich wpisów już wiemy, ile da się z nich odczytać… No ale taki jest internet. Coś za coś.
Jednak jeśli trafi nam się „wścibski” JavaScript, to może odczytać parę informacji z naszego komputera i jeszcze raz skontaktować się z nadawcą. Zazwyczaj wysyłając dokładniejsze szczegóły niż te, które sami ujawniliśmy w pierwszym kroku.
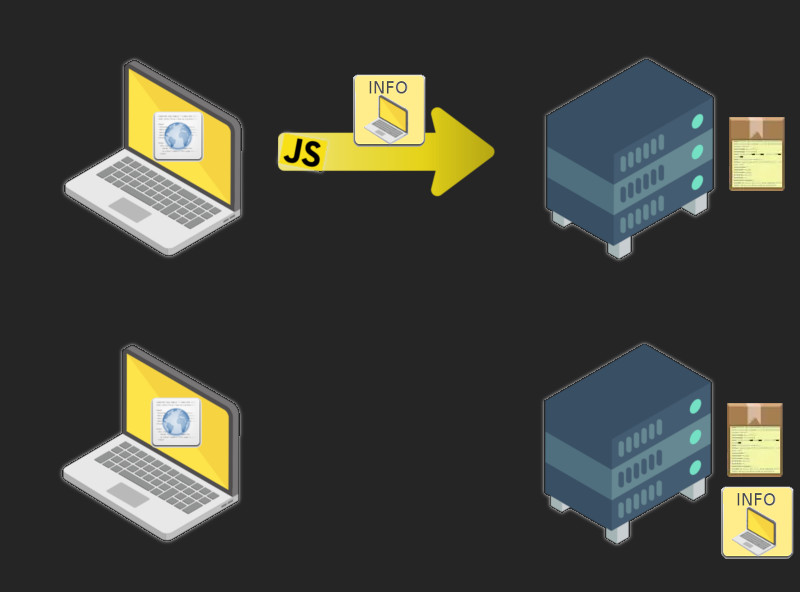
A jak wygląda ten cały JavaScript i co kryje się pod ikonką INFO z obrazka? Temu poświęcimy aktualny wpis.
Szczypta kodu
JavaScript to jeden z wielu języków programowania. Jest zwięzły, ma stosunkowo prostą składnię, jest bardzo elastyczny. I zawiera różne niuanse, które przystosowują go do tworzenia interaktywnych dokumentów.
 Ciekawostka
Ciekawostka
Gdzieś mogło Wam się obić o uszy, że oprócz JavaScriptu istnieje też taki język jak Java.
Te dwa języki nieraz się ludziom mylą. Do tego stopnia, że popularne są anegdoty o rekruterach, którzy dopiero na rozmowie kwalifikacyjnej odkrywali, że właśnie zmarnowali swój i cudzy czas.
A samo podobieństwo nazw podobno wynika z układów między firmami. Pierwotnie JS nazywał się Mocha, ale jego twórcy zaczęli współpracę z firmą Sun, właścicielami Javy. Zaś ci, w zamian za pewne korzyści, chcieli zmiany nazwy na taką, która promowałaby ich produkt.
Spośród dziesiątków innych języków programowania ten wyróżnia się jednym: postawiły na niego przeglądarki. Dlatego można go uznać za język programowania internetu.
Chcemy zobaczyć, jak on wygląda? Proszę bardzo, krótki przykład inspirowany moim dawnym wpisem na temat parametrów w linkach. Nie musicie tego zapamiętywać.
var full_link = window.location.href;
document.getElementById("params").innerHTML = full_link;
-
windowidocument, zaznaczone fioletowym kolorem, to zmienne z domysłu udostępnione przez przeglądarkę. My tylko do nich sięgamy. -
varoznacza, że tworzymy jakąś własną zmienną, tutaj o nazwie full_link. - Kropki pozwalają uzyskać dostęp do „wnętrza” różnych elementów albo do ich „zdolności”. Można je łączyć w zwięzłe łańcuszki.
Jeśli chodzi o ogólne działanie:
- pierwsza linijka „pyta” przeglądarkę, jaki jest link do oglądanej właśnie strony;
- druga linijka każe znaleźć na obecnej stronie element z właściwością
id="params"i wstawić do jego wnętrza link z poprzedniej linijki.
Dla naszych potrzeb wystarczy informacja, że JavaScript ma możliwość podpytywania przeglądarki o pewne informacje, a przeglądarka ochoczo się nimi dzieli.
Zamiast drugiej linijki, umieszczającej link na stronie, moglibyśmy oczywiście mieć kod wysyłający go komuś wścibskiemu. Wrócę do tego pod koniec wpisu.
JavaScript jako łapacz kłamczuchów
Zdobywanie informacji z nagłówków
JavaScript ma dostęp do większości rzeczy z naszej „etykiety” (nagłówków HTTP), o których już wspominałem w ramach „Internetowej inwigilacji”:
- referera,
- informacji o urządzeniu (user agenta),
- parametrów zawartych w linku,
- plików cookies,
- …i innych danych z „wizytówki”.
Nie ma dostępu do adresu IP; mówiąc bardzo ogólnie, tkwi on na nieco innym poziomie niż reszta danych.
Ale – zapyta ktoś – czy w ogóle warto się tym przejmować? Nasz komputer i tak to ujawnia przy pierwszym kontakcie. Więc co to zmieni, że potem JavaScript odczyta to samo?
Faktycznie; jeśli kontrolujemy serwer, na którym znajduje się strona, to możemy poznać te informacje jeszcze wcześniej. Ale nie każdy administrator strony posiada taką kontrolę.
Tak jest chociażby z blogiem, który właśnie czytacie – moje pliki znajdują się na serwerach Githuba, a ja nie mam wglądu w to, kto o nie prosił. Nie będę wiedział, czy liczba czytelników jest jedno- czy dwucyfrowa ![]()
Ale gdyby nagle zachciało mi się zbierać informacje o ludziach, mógłbym dodać do swojej strony skrypty analityczne. Wysyłające informacje do jeszcze innego serwisu, gdzie już mógłbym je podejrzeć.
Możemy z tego wynieść naukę, że brak władzy właściciela nad serwerem nie jest dla nas gwarancją prywatności. Nadal miałby sposób, żeby podejrzeć informacje o nas.
Podpytywanie przeglądarki o możliwości
Jak wspomniałem przy pierwszym przykładzie JS-a, przeglądarki udostępniają mu pewne funkcje albo informacje na życzenie.
Wystarczy krótki fragment kodu, żeby na przykład wypisać na stronie wszystkie możliwości, jakimi chwali się nasza przeglądarka (navigator):
for (i in navigator)
{
document.write('<br />navigator.' + i + ' = ' + navigator[i]);
}
Źródło: quirksmode.org.
Jeśli zajrzycie na podlinkowaną stronę, zobaczycie dość obszerną listę możliwości. 61 w przypadku mojego nowego nabytku, przeglądarki Brave.
Warto zauważyć, że przeglądarka przeglądarce nierówna. Niektóre udostępniają funkcje, których próżno szukać w innych.
Wchodząc na powyższą stronę z różnych przeglądarek, możemy zaobserwować, czym się wyróżniają. Jakiejś szczególnej dyskrecji to nie ma:
- Firefox udostępnia JavaScriptowi funkcję
navigator.mozGetUserMedia
(moz jak Mozilla, czyli ich firma-właściciel), - Brave udostępnia
navigator.brave.
Różnice występowałyby także między nowszymi i starszymi wersjami tej samej przeglądarki – w końcu każda z nich dodaje na bieżąco nowe funkcje.
W swoim starym wpisie na temat user agenta (czyli m.in. informacji o tym, jakiej używamy przeglądarki) ostrzegałem przed samodzielną zmianą i wpisywaniem przeglądarki całkiem innej niż nasza:
krótkie ostrzeżenie – zbyt brawurowa zmiana user agenta może nawet osłabić naszą prywatność.
Wynikało to właśnie z faktu, że istnieje JS. Gdyby mógł zerkać do jakiejś wielkiej listy przeglądarek oraz ich funkcji, byłby w stanie dość łatwo zweryfikować, przez co ktoś naprawdę przegląda stronę.
A fakt, że dana przeglądarka przedstawiała się jako inna, byłby bardzo mocnym czynnikiem wyróżniającym kogoś z tłumu.
Jeśli nie chcemy się wyróżniać, to już lepiej być nieco rzadszym, ale standardowym Firefoksem, niż TYM lisem chytrusem, który przedstawia się jako Chrome.

Popularny mem na podstawie kreskówki Scooby Doo, przeróbka moja.
Dawanie przeglądarce zadań
Same nazwy funkcji to tylko wierzchołek góry lodowej.
Nawet gdyby jakaś przeglądarka bardziej się przyłożyła do udawania innej – i na przykład udostępniała funkcje-wydmuszki o takich samych nazwach – JavaScript wciąż miałby możliwość powiedzieć „sprawdzam”.
Może na przykład kazać przeglądarce stworzyć jakiś element, a potem coś z nim zrobić.
!!document.createElement('canvas').getContext
Źródło: artykuł jeszcze z 2011 roku.
W tym przykładzie zadanie dla przeglądarki składa się z dwóch kroków:
- Musi stworzyć element
canvas; element specjalny, który został dodany do standardu HTML nieco później
(i służy do tego, żeby umieszczać na nim elementy graficzne; sama nazwa canvas to po angielsku płótno). - Musi użyć funkcji
getContext, którą ten element powinien mieć.
Jeśli przeglądarka jest starsza i nie wie nic o elemencie canvas ani jego możliwościach, to jej odpowiedzią będzie komputerowy odpowiednik „lol, ale o co ci chodzi?”. A skrypt, który kazał wykonać zadanie uświadomi sobie, że ma do czynienia ze starowinką.
Przykład z elementem canvas ma już swoje lata i obecnie praktycznie każda przeglądarka zdałaby ten test. Ale standardy stale idą naprzód. Kiedyś canvas było nowością, w przyszłości może to być jakieś metaverseCanvas.
Wysłanie informacji w świat
Gdyby działanie JavaScriptu było ograniczone do strony, w której jest osadzony, to wszystko byłoby w porządku. Dawałby nam interaktywność, nie szpiegując nas przy tym.
Ale jest inaczej. Stronki internetowe coraz częściej są ładowane dynamicznie; autorzy przeglądarek i samego JS-a dokładają starań, żeby komunikacja była jak najprostsza. Aktualnie wysłanie informacji w świat to kwestia kilku linijek kodu.
Przedstawiam nieco dłuższy fragment JS-a. Jak zwykle nie trzeba go rozumieć, zresztą większość to szablonowy tekst:
let xhr = new XMLHttpRequest();
let json = JSON.stringify( informacje_o_nas );
xhr.open("POST", stronka_nasza_lub_obca)
xhr.setRequestHeader('Content-type', 'application/json; charset=utf-8');
xhr.send(json);
Źródło: javascript.info, z moimi drobnymi zmianami.
Wystarczą nam trzy fakty:
-
XMLHttpRequestto kolejna rzecz domyślnie udostępniana przez przeglądarkę. Daje możliwość wysyłania informacji przez JS-a. -
JSONto dość zwięzły i czytelny format danych. Ogólnie wygląda jak zwykły tekst z nawiasami i apostrofami. - Zmienna
informacje_o_nasmoże zawierać dowolne rzeczy, jakie odczytał JavaScript. Zaś zmiennastronka_nasza_lub_obcato adres, pod który te informacje zostaną wysłane.
Pięć linijek nie licząc pustych. Ewentualnie jedna dodatkowa, jeśli ma to wszystko trafić w ręce całkiem obcej stronki.
Tyle wystarczy, żeby nasze informacje poleciały gdzieś w szeroki świat.
Parę słów na koniec
Widzimy, że JavaScript pod względem potencjału śledzącego jest co najmniej równy nagłówkom HTTP, które do tej pory omawiałem. Potrafi odczytać wszystkie te same informacje (poza adresem IP), a nawet zweryfikować ich prawdziwość. Swoje odkrycia może wysłać innym.
W kolejnych wpisach zobaczymy, że to dopiero początek jego możliwości.
Na koniec pozwolę sobie na lekką dygresję. Choć ogólnie można się cieszyć, że świat idzie do przodu, w przypadku JavaScriptu ma to swoje wady.
Pierwsza sprawa: ludzie chcą coraz to nowszych bajerów. Albo menedżerowie wmawiają programistom, że tak jest; wychodzi na to samo.
Jeśli jakaś przeglądarka przestanie dodawać bajery, to stanie się mniej popularna. Zatem trwa przeglądarkowy wyścig szczurów. Dodają coraz więcej funkcji, bo muszą, bo robią tak inni. Wielu tych funkcji, jak zobaczymy, można nadużyć do celów śledzenia.
Druga sprawa: rosnąca „aplikacjoza”. Zamiast nieruchomych, stałych stronek – internetowy odpowiednik aplikacji. Rzeczy większe, animowane, interaktywne. Strony ładowane na raty, żeby dało się je przewijać w nieskończoność.
Nieraz wszystko to powolne i dziadowskie… no ale trendy!
W takich warunkach popularność JavaScriptu będzie jedynie rosła. A prąd, wbrew któremu będą musiały iść osoby stawiające szacunek dla użytkowników nad nowoczesnością, może być niestety coraz silniejszy.
Ale nie ma co się poddawać! Gdy nie ma siły, żeby iść pod prąd, to można na chwilę się rozluźnić i dać się ponieść. Na przykład do kolejnego wpisu ![]()
Był to wpis z serii Internetowa inwigilacja