
Linux Mint i brakujące znaki z azjatyckich czcionek
W tym miniwpisie opiszę problem z azjatyckimi znakami, jaki mi się przytrafił na systemie Linux Mint (dokładniej: edycja Mate, wersja 22.1). Obstawiam jednak, że ma proste przełożenie na inne Linuksy oraz inne przypadki, gdy nie wyświetlają się niektóre znaki.
Opisuję tu całą ścieżkę od zauważenia problemu do jego rozwiązania, po drodze dzieląc się paroma codziennymi konsolowymi sztuczkami.
Jeśli ktoś nie ma cierpliwości, to może od razu przeskoczyć na koniec, do rozwiązania.
Zarys problemu
Pewnego dnia w przeglądarce Firefox przestały mi się wyświetlać znaki japońskiego alfabetu (kanji i nie tylko). Zamiast nich widać było prostokąty wypełnione cyframi – tak zwane tofu, znaki zastępcze.
Po pewnym czasie odkryłem, że problem dotykał również zwykłych plików tekstowych oraz nazw plików wyświetlanych w domyślnym „Eksploratorze”.
Nie chodzę po stronach azjatyckich, ale brak znaków utrudniałby mi życie. Nie widziałbym, czy ktoś pisze w komentarzach arigato czy bakayaro. No i tekstowe wzruszenia ramion nie były już jak dawniej:
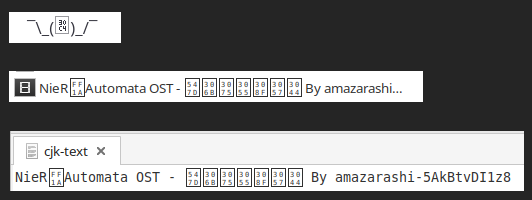
Brakujące znaki kolejno w: przeglądarce internetowej, przeglądarce plików, prostym edytorze tekstu.
Przyczyny problemu nie znałem. W tamtym czasie testowałem różne warianty Linuksa, więc było sporo instalowania i eksploracji. Może któryś z pakietów podczas instalacji przenosił czcionki w inne, tymczasowe miejsce? A mnie instalacja przerwała się w połowie, przez co nigdy nie wróciły ze swojego czyśćca? Nie wiem, mogę tylko gdybać.
W każdym razie: sam to na siebie sprowadziłem, a większość użytkowników Linuksa nie zetknie się z tym problemem. System będzie im śmigał, wyświetlając informacje we wszystkich językach świata.
…Ale gdyby ktoś przypadkiem dołączył do grona nieszczęśliwców, to zapraszam na spacer w stronę rozwiązania problemu.
Szukanie przyczyny
Chcąc odzyskać swoje kochane hieroglify, musiałem od czegoś zacząć.
Pierwsze założenie: jeśli problem dotyczy wielu programów naraz, to zapewne wiąże się z czymś systemowym.
Na systemie Linux czcionki działają na szczęście w bardzo prosty sposób – umieszcza się je w paru specjalnych folderach, znanych systemowi. Na moim Mincie to /usr/share/fonts i jego podfoldery.
System sięga sobie do tych folderów, kiedy pojawia się taka potrzeba (np. napotka w danych nowy znak i musi go wyświetlić). Jeśli nie znajdzie jakiegoś znaku, to wyświetla zamiast niego znak zastępczy, czyli właśnie wspomniane tofu. Prostokąt z liczbami.
Wiedząc o tym i widząc, że reszta znaków działa, mogłem przyjąć założenie drugie – brakuje mi jakiejś czcionki. Mówiąc dokładniej: brakuje mi czcionek azjatyckich. Sprawdziłem to, wchodząc sobie na koreańską Wikipedię i widząc więcej tofu.
Czcionki azjatyckie to w oficjalnym nazewnictwie CJK fonts (skrót od Chinese, Japanese, Korean). Zawsze miałbym jakiś punkt wyjścia do szukania w internecie: linux mint cjk fonts not showing. Na którymś forum znalazłbym zapewne polecenie instalujące, a po jego wykonaniu zdobyłbym brakujące czcionki – choć niekoniecznie te co wcześniej.
Zamiast tego postanowiłem jednak działać metodycznie i sprawdzić, czego dokładnie mi brakowało. Część niżej jest nieobowiązkowa, jeśli panicznie boicie się konsoli. Mimo to zachęcam, bo pokazuje, w jaki sposób można rozwiązać krok po kroku swoje problemy.
Porównanie stanu między systemami
Na początku czcionki mi działały, dopiero po drodze coś się zepsuło. Wiedząc o tym, mogłem założyć że system czysty i nowy powinien zawierać prawidłowe wersje czcionek i ustawień. Można podejrzeć, czym się różni od mojego wadliwego.
Miałem nadal na pendrivie plik ISO, którego użyłem podczas instalacji. Ten sam system, ta sama wersja – idealnie! Jak grupa kontrolna w badaniach naukowych.
Włożyłem tego pendrive’a do portu USB, nacisnąłem odpowiednią kombinację klawiszy (u mnie F12 tuż po wciśnięciu przycisku zasilania) i wybrałem opcję uruchomienia systemu z pendrive’a.
Włączył się w tak zwanym trybie live. Mogłem sobie majsterkować bez zobowiązań, podczas gdy mój główny system „spał” sobie na dysku, nieruszany przez nikogo.
 Wątek poboczny
Wątek poboczny
Instalowanie Linuksów jeszcze kiedyś opiszę, ale zostawię tu streszczenie dla chętnych: pobieram plik ISO z wybranym Linuksem ze strony projektu oraz program Ventoy, szykuję też pustego pendrive’a.
Uruchamiam Ventoya i wskazuję mu pendrive’a, zmieniając go w wielkiego instalatora LInuksów. Potem po prostu kopiuję na tego pendrive’a plik ISO. Lub więcej plików, jeśli chcę testować.
Najtrudniejsza część to wejście w menu uruchamiania (bootowania), bo różni się ono między producentami i modelami komputerów.
Brakujące pliki?
Mając czysty system pod ręką, mogłem sprawdzić obecne na nim czcionki. Choćby przez wypisanie wszystkich plików zawartych w oficjalnym folderze czcionkowym /usr/share/fonts i jego podfolderach:
find /usr/share/fonts
To polecenie wypisuje listę plików i folderów. Domyślnie wyświetla się ona tylko w konsoli. Żeby zamiast tego zapisać ją do pliku, mogłem użyć operatora strzałki:
find /usr/share/fonts > czcionki-czysty-system.txt
Nazwa pliku całkiem dowolna, wybrana subiektywnie przeze mnie.
Po uzyskaniu listy z czystego systemu mogłem ją sobie zgrać na pendrive’a, wyłączyć komputer i uruchomić swój używany system. Powtórzyłem na nim polecenie, tym razem zapisując pliki do czcionki-uzywany-system.txt.
Do wyłapania różnicy między plikami użyłem własnego skryptu Pythona, ale równie dobrze mógłbym użyć wbudowanego programu:
diff PLIK1 PLIK2
Miałem nadzieję, że okaże się po prostu, że gdzieś mi wcięło pliki, i że skończy się na ich kopiowaniu z systemu czystego do „nieczystego”.
…Okazuje się jednak, że było inaczej. System używany miał wszystkie te pliki, co nowy, plus jeszcze trochę dodatkowych. W tym na przykład czcionkę o wdzięcznej nazwie Lato.
Problem tkwił w czymś więcej niż pliki. Musiałem przyjrzeć się sposobowi, w jaki system je ładuje.
Sposób na ustalenie konkretnej ładowanej czcionki (strace)
Linux daje również możliwość użycia przydatnego programiku strace, monitorującego wszystkie interakcje z systemem. W tym otwieranie plików i ładowanie ich zawartości, co może się idealnie przydać w naszym przypadku.
Zarys planu? Mogę monitorować strace‘em, jak otwieram plik zawierający obcojęzyczne znaki. Zobaczyć, co ładuje na sprawnym systemie, a co na niesprawnym.
Ze względu na prostotę wybrałem w roli tego programu edytor tekstu, odpowiednik Notatnika z Windowsa.
Naszykowałem plik z kilkoma znakami japońskimi, które na czystym systemie są widoczne, a na używanym zmieniają się w tofu (to ten plik ze zrzutu ekranu na początku wpisu).
Programik strace wymaga pracy w konsoli, więc musiałem ustalić, jakie konsolowe polecenie odpowiada mojemu „Notatnikowi”. Najpierw uruchomiłem go klasycznie, kliknąłem w informacje, ustaliłem że jego nazwa to Xed.
Na Linuksie nazwa konsolowa zwykle odpowiada oficjalnej, więc sprawdziłem, czy polecenie xed go uruchamia. Tak było.
Otwieranie pliku przez xeda jest bardzo proste: xed PLIK.
Z kolei zapisywanie wyników strace‘a do pliku wyjściowego, żeby móc je sobie potem porównać między systemami, wymaga podania argumentu -o PLIK_WYJŚCIOWY.
Łącząc to w całość, skleciłem ostateczne polecenie:
strace -o czysty-system-strace.txt xed PLIK_Z_KANJI.txt
Nazwy plików, wyróżnione na czerwono, jak zwykle dowolne i dobrane subiektywnie.
Poczekałem, aż plik się wczyta. Azjatyckie znaki działały na świeżym systemie jak marzenie. Zamknąłem edytor, pozostając z zapisaną pełną historią interakcji z systemem.
Przeszukałem ją niezawodnym programem grep, wypatrując słowa font, bo wiedziałem, że powinno odpowiadać ścieżkom do czcionek:
grep "font" czysty-system-strace.txt
Wyniki (nieco oczyszczone, żeby zostawić tylko przypadki otwarcia plików, bez duplikatów):
openat(AT_FDCWD, "/lib/x86_64-linux-gnu/libfontconfig.so.1", O_RDONLY|O_CLOEXEC)
openat(AT_FDCWD, "/usr/share/fonts/truetype/ubuntu/Ubuntu[wdth,wght].ttf", O_RDONLY)
openat(AT_FDCWD, "/usr/share/fonts/truetype/dejavu/DejaVuSansMono.ttf", O_RDONLY)
openat(AT_FDCWD, "/usr/share/fonts/opentype/noto/NotoSansCJK-Regular.ttc", O_RDONLY)
Ostatnia linijka pokazuje mi, skąd załadował znaki bezproblemowy „czysty” system – z pliku /usr/share/fonts/opentype/noto/NotoSansCJK-Regular.ttc, gdzie Noto to nazwa czcionki, zaś CJK ujawnia jej azjatycką naturę.
…Tyle że, jak wspomniałem, brak pliku nie był tu problemem i miałem go na obu systemach. Gdybym natomiast znalazł się w sytuacji, gdy szukam konkretnej rzeczy, to strace i patrzenie na otwierane pliki byłoby sensownym podejściem.
Brakujące przyporządkowania
Skoro problem nie tkwił w brakujących plikach, to w czym? Logika podpowiada, że system mógłby mieć jakąś swoją wewnętrzną regułę. Coś w stylu: „znak azjatycki? To muszę sięgnąć do pliku X”.
Pomogła mi tu odrobina wiedzy nagromadzona w innych przypadkach. Takie powiązanie między jedną rzeczą (językiem) a drugą (plikami zawierającymi czcionki) po angielsku nazywa się często mapping.
Odrobina szukania pod hasłami linux showing system font mapping itp. pokazała, że od zaglądania w czcionki system ma swój program fc-list (skrót od fontconfig).
A zatem jak wcześniej – uruchomiłem czysty system i użyłem polecenia zapisującego listę znanych rzeczy do pliku:
Potem to samo powtórzyłem na systemie z czcionkowym problemem.
Miałem teraz dwie listy czcionek. Patrząc na różnice między nimi, mogłem ustalić, co się zmieniło. Zamiast robić pełną wizualizację różnic, użyłem na początku programiku grep, szukając słowa CJK, często obecnego w nazwach czcionek:
grep "CJK" czysty-system-fclist.txt
Zwróciło kilkadziesiąt wyników dla systemu czystego i sprawnego. Kilkadziesiąt powiązań między językiem a czcionką, tak jak być powinno.
A kiedy wykonałem to samo polecenie dla systemu problematycznego… Nie wyświetliło niczego. Wprawdzie system używany miał parę powiązań, których brakowało czystemu (np. do wspomnianej wyżej czcionki Lato), ale pod względem czcionek azjatyckich zostawał w tyle.
Miałem prawdopodobną przyczynę – na moim używanym systemie brakowało przyporządkowań językowo-plikowych, które miał system czysty.
Patrząc pod hasłami linux fixing font mapping i zbliżonymi, znalazłem przypadkiem ciekawe polecenie. Analizuje ono pliki umieszczone w folderach czcionkowych, patrzy jakim logicznym znakom odpowiadają i zapisuje te informacje.
To tak zwana pamięć (podręczna) czcionek. Po angielsku font cache. A polecenie to:
fc-cache -f -v
Użyłem tego polecenia, po czym ponownie sprawdziłem przez fc-list, jakie mam przyporządkowania. Pojawiły się te brakujące względem czystego systemu!
W przeglądarce plików nie od razu się poprawiło, musiałem uruchomić ponownie komputer. Natomiast Firefox po odświeżeniu zaczął wyświetlać brakujące znaki ![]()
Skąd się wziął cały problem? Nie wiem. Ale od teraz mogę przynajmniej zilustrować tę niewiedzę pełnoprawną reakcją bez tofu:
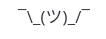
Podsumowanie
W tym miejscu kończę część eksploracyjną i podsumowuję rozwiązania problemu z azjatyckimi czcionkami.
Zaczynając od rozwiązań najprostszych:
-
Aktualizacja powiązań między znakami logicznymi a graficznymi.
Trzeba otworzyć konsolę, wpisać w nią
fc-cache -f -vi nacisnąć Enter. Jeśli przyczyną nie był brak plików, tylko brak powiązań, to w tym momencie powinno się naprawić. Jak u mnie. -
Zainstalowanie innego pakietu czcionek.
Jeśli przyczyną problemu jest brak plików z czcionkami, to trzeba je pozyskać. Można to zrobić zarówno przez interfejs graficzny (na Mincie: menu w dolnym rogu,
Menedżer oprogramowania), jak i konsolę – np. wpisaćsudo apt-get install ttf-mscorefonts-installerżeby zainstalować czcionki Microsoftu. Po instalacji tym sposobem powinny automatycznie powstać potrzebne powiązania.
Rozwiązanie szybkie i kompletne, jeśli chcemy po prostu widzieć brakujące znaki. Ale niewystarczające, jeśli zależy nam na konkretnej czcionce.
-
Ręczna instalacja konkretnej czcionki.
Jeśli wiemy, czego nam brakuje, to trzeba zdobyć plik z czcionką z jakiegoś źródła, zapewne internetu. Potem należy go umieścić w odpowiednim folderze (co będzie wymagało uprawnień administratora). A na koniec: odświeżyć pamięć czcionek, poleceniem
fc-cache -f -v, jak parę punktów wyżej. -
Ponowna instalacja systemu.
Opcja nuklearna, ale pozwala przywrócić system do początkowego stanu. Może się przydać, gdyby się okazało, że za bardzo nabroiliśmy i problem jest większy niż jakiś brak czcionek. To zwykle prowadzi do usunięcia plików, więc należy najpierw je zgrać w bezpieczne miejsce.
Na przyszłość
Rozwiązałem problem, ale nie ustaliłem jego źródła – to mogłoby być zadanie na przyszłość.
Linux daje wiele możliwości kontrolowania swojego systemu. Załóżmy, że przyczyną mojego problemu był jakiś program zbyt śmiało ingerujący w pamięć czcionek.
W takim wypadku pomógłby cyfrowy odpowiednik „fotokomórki” wyłapującej, kiedy jakiś program próbuje mi tam grzebać. Po wykryciu prób ingerencji mógłbym je blokować albo przynajmniej zapisywać, żeby ustalić winnych.
Ale póki co, nie widząc łatwego sposobu na odtworzenie błędu, umieszczę tu listę azjatyckich czcionek, jakie mi „wcięło” i jakich według fc-list nie miałem na używanym systemie. Może komuś to pomoże w przypadku napotkania podobnego błędu.
Lista brakujących powiązań dla języków azjatyckich
/usr/share/fonts/opentype/noto/NotoSerifCJK-Bold.ttc: Noto Serif CJK SC:style=Bold /usr/share/fonts/opentype/noto/NotoSerifCJK-Bold.ttc: Noto Serif CJK TC:style=Bold /usr/share/fonts/opentype/noto/NotoSerifCJK-Bold.ttc: Noto Serif CJK JP:style=Bold /usr/share/fonts/opentype/noto/NotoSerifCJK-Bold.ttc: Noto Serif CJK HK:style=Bold /usr/share/fonts/opentype/noto/NotoSerifCJK-Bold.ttc: Noto Serif CJK KR:style=Bold /usr/share/fonts/opentype/noto/NotoSansCJK-Regular.ttc: Noto Sans CJK JP:style=Regular /usr/share/fonts/opentype/noto/NotoSansCJK-Regular.ttc: Noto Sans CJK HK:style=Regular /usr/share/fonts/opentype/noto/NotoSansCJK-Regular.ttc: Noto Sans CJK KR:style=Regular /usr/share/fonts/opentype/noto/NotoSansCJK-Regular.ttc: Noto Sans CJK SC:style=Regular /usr/share/fonts/opentype/noto/NotoSansCJK-Regular.ttc: Noto Sans CJK TC:style=Regular /usr/share/fonts/opentype/noto/NotoSerifCJK-Regular.ttc: Noto Serif CJK SC:style=Regular /usr/share/fonts/opentype/noto/NotoSerifCJK-Regular.ttc: Noto Serif CJK TC:style=Regular /usr/share/fonts/opentype/noto/NotoSerifCJK-Regular.ttc: Noto Serif CJK JP:style=Regular /usr/share/fonts/opentype/noto/NotoSerifCJK-Regular.ttc: Noto Serif CJK KR:style=Regular /usr/share/fonts/opentype/noto/NotoSerifCJK-Regular.ttc: Noto Serif CJK HK:style=Regular /usr/share/fonts/opentype/noto/NotoSansCJK-Bold.ttc: Noto Sans Mono CJK TC:style=Bold /usr/share/fonts/opentype/noto/NotoSansCJK-Bold.ttc: Noto Sans Mono CJK SC:style=Bold /usr/share/fonts/opentype/noto/NotoSansCJK-Bold.ttc: Noto Sans Mono CJK KR:style=Bold /usr/share/fonts/opentype/noto/NotoSansCJK-Bold.ttc: Noto Sans Mono CJK HK:style=Bold /usr/share/fonts/opentype/noto/NotoSansCJK-Bold.ttc: Noto Sans Mono CJK JP:style=Bold /usr/share/fonts/opentype/noto/NotoSansCJK-Regular.ttc: Noto Sans Mono CJK SC:style=Regular /usr/share/fonts/opentype/noto/NotoSansCJK-Regular.ttc: Noto Sans Mono CJK TC:style=Regular /usr/share/fonts/opentype/noto/NotoSansCJK-Regular.ttc: Noto Sans Mono CJK HK:style=Regular /usr/share/fonts/opentype/noto/NotoSansCJK-Regular.ttc: Noto Sans Mono CJK KR:style=Regular /usr/share/fonts/opentype/noto/NotoSansCJK-Regular.ttc: Noto Sans Mono CJK JP:style=Regular /usr/share/fonts/opentype/noto/NotoSansCJK-Bold.ttc: Noto Sans CJK JP:style=Bold /usr/share/fonts/opentype/noto/NotoSansCJK-Bold.ttc: Noto Sans CJK KR:style=Bold /usr/share/fonts/opentype/noto/NotoSansCJK-Bold.ttc: Noto Sans CJK HK:style=Bold /usr/share/fonts/opentype/noto/NotoSansCJK-Bold.ttc: Noto Sans CJK TC:style=Bold /usr/share/fonts/opentype/noto/NotoSansCJK-Bold.ttc: Noto Sans CJK SC:style=Bold
Tak działa świat otwartego źródła: ktoś zauważy problem, ktoś inny potwierdzi, ktoś nagłośni. Jakaś osoba wchodząca w świat programowania doda łatkę. O ile ktoś nie zrobi rewolucji i nie przepisze gruntownie swojego programu, to z każdą taką poprawką rzeczy działają coraz lepiej i stabilniej.
Dzięki tej współpracy świat open source może iść do przodu, być może odbierając Windowsowi dotychczasowe bastiony. Czemu bardzo kibicuję! ![]()
Wątek prywatnościowy
Strony internetowe mogą czasem zawierać elementy śledzące, rozpoznające użytkowników po zestawie zainstalowanych czcionek.
Patrząc na to w ten sposób, robienie co jakiś czas czystki i usuwanie czcionek poza domyślnymi, obecnymi na świeżym systemie, byłoby jak czyszczenie plików cookies albo historii przeglądania.
Jeśli ktoś nie chce gmerać przy swoich czcionkach, ale myśli czasem o prywatności, to może w poważniejszych przypadkach korzystać z internetu przez maszynę wirtualną.