
AI i współcześni szamani
Też macie wrażenie, że w ostatnich latach wszędzie namnożyło się nam Sztucznej Inteligencji?
Pokazują ją billboardy i reklamy internetowe:

Również w mediach co pewien czas miga artykuł z obowiązkową gębą robota albo inną fotką ze Stocka:

Źródła: Futurism, PC Format, Chip, Brief.pl, Spider’s Web.
Wkrótce strach będzie otworzyć lodówkę, bo jeszcze z niej Ej-Aj wyskoczy!

Źródła: The Verge.
…No właśnie ![]()
W reakcji na te wszystkie obrazy pojawiają się również komentarze internetowych Nostradamusów wieszczących katastrofę:
Źródło: Wykop.
Nasuwają się pytania: czym jest to powszechnie reklamowane AI? Dlaczego tak nagle się pojawiło w naszym życiu? Czy faktycznie istnieją już jakieś myślące maszyny? Czy mogą się zbuntować?
Krótko na dwa ostatnie: nie.
I nie dlatego, że „sztuczna inteligencja nie zbuntowałaby się przeciw swoim twórcom”.
Ani nie dlatego że „to mądrzy naukowcy tworzą, na pewno dodali zabezpieczenia”
(protip: lepiej nie zdawać się na cudzy rozsądek).
Nie, prawdziwy powód jest prostszy – nie istnieje obecnie żadne „AI” w tym znaczeniu, które kojarzymy z popkultury. To nazwa czysto marketingowa.
„AI” to po prostu pewien rodzaj elastycznych programów. Ale media i wielkie firmy świadomie sugerują możliwości, których takie programy zwyczajnie nie mają. Wchodzą w rolę szamanów, którzy posiedli wiedzę tajemną i próbują uzależnić od siebie wyznawców.
W tym wpisie przedstawię kilka rzeczy związanych z metodą szumnie nazywaną „AI”, obalę popularne mity i pokażę, dlaczego sposób mówienia o niej uważam za przekłamany.
Mit 1 jest tuż poniżej. Tu linki do pozostałych, jeśli nie macie czasu na wszystko:
- Mit 2: AI to coś nowego;
- Mit 3: AI to coś dla wybranych;
- Mit 4: roboty Facebooka tworzyły własny język.
Mit 1: AI może zyskać świadomość
Najłatwiej mi będzie obalić ten mit, pokazując w praktyce, czym jest to „AI”.
Wyobraźmy sobie sytuację z życia codziennego: znajomi często nas proszą o polecenie jakiegoś fajnego filmu. Zamiast polecać zawsze to samo, chcemy dopasować się do gustu drugiej osoby.
Możemy to rozwiązać na kilka sposobów:
Odpowiedzieć „na czuja”
Opcja najprostsza i najbardziej naturalna – myślimy przez chwilę, co może lubić dana osoba, trochę ją podpytujemy. Dzielimy się przemyśleniami.
Zaleta tej opcji to na pewno prostota i to, że jest dopasowana do odbiorcy.
Wadą może być subiektywizm, bo trzeba zdać się na nasz gust.
Poza tym, jak by powiedzieli branżowcy: „ło panie, to się nie skaluje”.
Wyobraźmy sobie, że znajomi uważają nas ze filmowych ekspertów. I rozpowiadają to innym. Teraz naszej porady chce zasięgnąć mnóstwo osób. Ale nasz czas jest ograniczony, nie damy radę obsłużyć tak dużej grupy.
Rozrysować schemat
Jeśli staniemy się taką „znaną marką” w kwestii polecania filmów i chcemy dogodzić większej liczbie osób, to możemy narysować jeden schemat zawierający nasze przemyślenia.
Wystarczy, że go zawiesimy na drzwiach / wrzucimy na bloga / roześlemy mailem. A ludzie już sami sobie dopasują film według tego klucza. Tworzymy raz, a służy wszystkim. W ten sposób rozwiązujemy problem „skalowania”.
Natomiast powstaje inny problem – tym razem nie mamy opcji podpytywania ludzi, zanim im coś polecimy. Trzeba stworzyć coś na tyle ogólnego, żeby zawierało jak najwięcej możliwości.
Pytanie: czy potrafimy sobie coś takiego wyobrazić naszym ludzkim mózgiem? Prosty, jajcarski schemat może jeszcze damy radę:
Drzewko decyzyjne stworzone przez człowieka.
Źródło: Pinterest.
Jeśli bardzo nam się chce, to możemy nawet narysować gigantyczny schemat-potwora, jak ten dla filmów z Netflixa.
Ale mózg w końcu przestaje wyrabiać. Filmów jest za dużo, możliwości zbyt wiele. No i zaczynają się mnożyć wyjątki:
- Ogólnie moglibyśmy pomyśleć, że nie polecamy filmów nisko ocenionych.
- …Ale wśród filmów kiepskich są też kultowe. Więc niska ocena to nie wszystko.
- …Ale jak odróżnić klasykę tak złych, że aż dobrych od zwykłego nudnego gniota?
W takim gąszczu możliwości człowiek zwyczajnie nie da rady. Nie stworzymy o własnych siłach drzewka decyzyjnego dla wszystkich filmów i wielu różnych odbiorców.
Przyda się pomoc komputera.
Zaprząc do pracy „AI”
To w tym momencie wchodzi uczenie maszynowe (ang. machine learning), nazywane szumnie „sztuczną inteligencją”. Całe na biało.
Nasz mózg nie dawał rady ogarnąć wszystkich możliwych kombinacji. Dla komputera to pestka. Jedynym jego ograniczeniem jest to, że potrzebuje danych w jakiejś schludnej formie.
Możemy więc pobrać je z IMDB, wielkiej strony z informacjami o filmach. Gromadzimy bazę danych o praktycznie wszystkich filmach, jakie powstały na świecie. Dla każdego z nich:
- ocenę od widzów;
- ocenę od krytyków;
- gatunki, do jakich się zalicza;
- czas trwania;
- treść recenzji widzów;
- wszelkie inne dane, jakie tylko nam przyjdą do głowy.
Opracowujemy dane. Ocenę i czas trwania można po prostu zostawić jako liczby. Teksty recenzji są w surowej formie mało przydatne (zbyt duża różnorodność), więc trzeba je przetworzyć i np. liczyć w nich jakieś słowa kluczowe.
Upiększone dane wrzucamy w komputer. I dajemy mu polecenie: „Komputerze, stwórz z tego model”.
Komputer pracuje i mieli dane. Porównuje jedne rzeczy z drugimi, znajduje różne prawidłowości. Ten proces nazywamy uczeniem (albo treningiem) modelu. Jest najbardziej praco- i czasochłonnym etapem.
Przy dużej ilości danych komputer znajdzie nawet subtelne zależności – takie jak grupa „filmy o niskiej ocenie krytyków + wyższej od użytkowników + w ich recenzjach często jest słowo cult”. Przypadkiem wykrył gatunek so bad it’s good!
Efektem działań komputera jest tzw. model – również schemat decyzyjny, ale bardziej złożony:
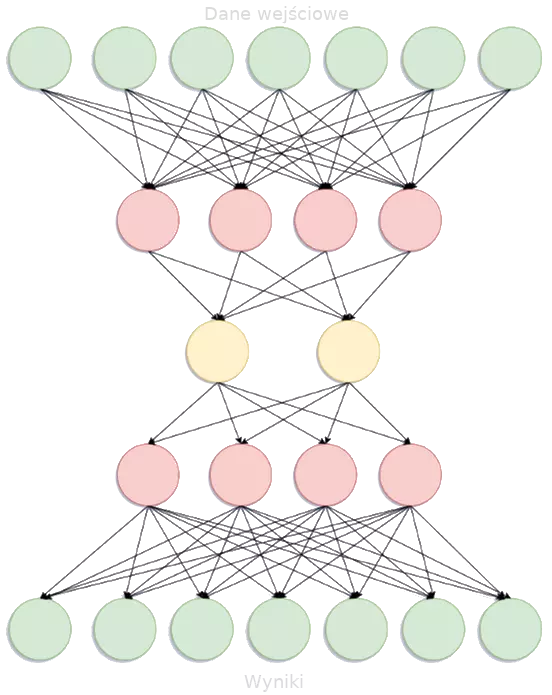
Drzewko decyzyjne stworzone przez komputer.
Źródło: blog Hrishekesha Shinde. Modyfikacje moje.
…A to tylko ilustracja. W praktyce model jest dużo, dużo większy.
 Ciekawostka
Ciekawostka
Taką metodę jak wyżej nazywamy siecią neuronową. Dlaczego? Ponieważ jej działanie nieco przypomina to, jakie wykazują neurony w naszym mózgu.
Oczywiście komputer nie myśli. Po prostu analizuje zależności między wieloma informacjami, połączonymi każda z każdą. Jeśli jakieś zależności często się powtarzają, to wzmacnia połączenia między nimi. Z czasem ustala się kilka wyraźnych ścieżek przepływu informacji.
Na podobnej zasadzie wzmacniają się połączenia między ludzkimi neuronami.
Jak tego użyć w praktyce? Gdybyśmy taki schemat dali ludziom na kartce, to by zgłupieli. Dlatego działa to nieco inaczej:
-
Umieszczamy model na jakimś serwerze, żeby tam sobie siedział. A ludziom podrzucamy np. link do formularza, w którym wpisują, jakie inne filmy im się podobały.
-
Kiedy wypełnią formularz, zostaje wysłany na nasz serwer, tam gdzie czeka model. Ich odpowiedź zostaje przetworzona na postać lekkostrawną dla modelu.
-
Wyobraźcie sobie, że dane trafiają teraz do któregoś z zielonych kół w górnej części schematu. A następnie przeciskają się w dół – trafiając w inną ścieżkę w zależności od tego, jakie są ich wartości.
-
Na koniec trafiają do którejś z grup filmów, które wyodrębnił model. Można taką listę odesłać odbiorcom z informacją, że takie filmy im polecamy.
W ten sposób mamy polecarkę i pokonaliśmy ograniczenie dwóch poprzednich podejść:
- Mamy coś, czego może używać wiele różnych osób i co nie wymaga obsługi;
- …I czego nie bylibyśmy w stanie stworzyć ręcznie;
-
Pozbyliśmy się części subiektywizmu.
Nie do końca – nadal to my wybieramy, na jakie cechy ma zwrócić uwagę komputer.
Ale nie musimy już sami decydować, która z nich jest ważniejsza ani w jakiej kolejności na nie patrzeć.
Na tym w praktyce polega często metoda sprzedawana jako AI. Używamy jej, kiedy mamy kwestię nie do końca jasną i zdefiniowaną, której nie rozwiążemy pracą ludzką (albo moglibyśmy, ale chcemy przyoszczędzić). Wtedy szykujemy dane, karmimy nimi komputer i każemy mu stworzyć schemat rozwiązania dopasowany do naszego problemu.
To przydatna metoda. Natomiast czy może zyskać świadomość? Nie może – jest zwykłym narzędziem, jak średnia arytmetyczna.
Moglibyśmy odpalić Excela i wydać komputerowi polecenie „Stwórz z tych danych wykres”.
Tak samo możemy odpalić PyTorcha i wydać polecenie „Stwórz z tych danych model”.
Owszem – tego rodzaju modele potrafią zabijać, jeśli się je wgra do drona bojowego. Ale tak samo zabijałby najprostszy program while True: shoot().
Mit 2: AI to coś nowego
Nie sądzę, żebyście pojęcie „sztuczna inteligencja” usłyszeli po raz pierwszy dopiero w ostatnich latach. Chyba że jesteście naprawdę młodzi. Raczej obiła Wam się wcześniej o uszy choćby seria „Terminator”.
To kino łączy pokolenia – kojarzę je ze swojej młodości z lat 90., a jego kolejne części wypuszczają z regularnością zegarka… od roku 1984.
Ale to i tak niemalże współczesność, da się sięgnąć jeszcze dalej. W jednym ze źródeł z Uniwersytetu Waszyngtona piszą wprost:
Pojęcie sztucznej inteligencji przedstawił John McCarthy w 1956 roku, podczas konferencji naukowej.
Źródło: notatki na temat historii AI (wszystkie tłumaczenia moje).
W artykule z Digitaltrends wymienili jeszcze więcej ważnych punktów w historii AI. Sięgając aż do momentu sformułowania teorii matematycznej, która stoi u podstaw sztucznej inteligencji.
Metody uczenia maszynowego, czasem w kształcie bliskim tym współczesnym, były znane już prawie 70 lat temu!
Ciekawostka
Gdyby sięgnąć jeszcze dalej wstecz, pewnie znaleźlibyśmy więcej przykładów, tyle że w sensie abstrakcyjnym albo filozoficznym. Takich jak Talos z antycznej mitologii.
Jest jednak coś, co się zmieniło. Szeroko pojęta branża AI przeżywa boom.
Spójrzmy na liczby od Fortune Business Insights – wskazują, że w 2019 roku rynek AI był wart 27,23 mld dolarów. Jego wartość w 2027 prognozuje się na 266,92 mld. Prawie 10-krotny wzrost.
Jakieś bardziej organiczne wyniki?
Może popularność tagów artificial-intelligence i machine-learning na StackOverflow, największym forum pytań i odpowiedzi dla programistów i nie tylko:
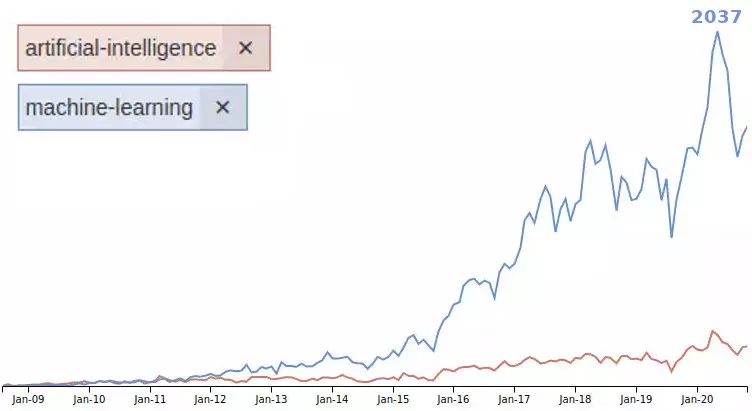
Źródło: dane o liczbie tagów na StackOverflow. Modyfikacje moje.
W maju 2012 r. było 38 pytań otagowanych jako AI i 92 jako uczenie maszynowe.
W maju 2020 r. (największa „górka”) już 295 dla AI i aż 2037 (prawie papieżowa liczba!) dla uczenia maszynowego.
Ciekawi wielka przewaga ML nad AI. Może to jakiś pośredni dowodzik na to, że AI to nazwa marketingowa, a branża stosuje tę praktyczną? ![]()
Ale my nie o tym. Ważniejszy jest sam fakt, że tagi stają się popularniejsze, a machine-learning przeżył prawdziwą eksplozję w ostatnich latach. Czyli programiści częściej o to pytają, branża się rozwija.
Również liczba artykułów przyjętych na NeurIPS, jedną z największych konferencji na temat uczenia maszynowego, cały czas rośnie. Z 569 (2016 r.) na 1899 (2020 r.).
Na chwilę obecną wystarczy przykładów i można już chyba obalić mit. Częściowo. Bo AI jest stare, ale eksplozja zainteresowania jest nowa.
Możemy się zastanowić – co się zmieniło, nie dało się tak dawniej?
Jedną z przyczyn na pewno jest dostępność mocniejszych komputerów. Nowe możliwości pozwoliły nakręcić samonapędzającą się falę – badań, wdrożeń, zapotrzebowania, nowych badań itd.
Kiedyś tego nie było, a wyczerpujące trenowanie modeli było ponad siły komputerów.
Ale było coś jeszcze – zima AI z lat 80. i 90. A właściwie zimy. Kilka razy na dłuższy czas odkładano badania nad sztuczną inteligencją, a branża zamierała.
Dlaczego? Czytajcie dalej, wrócę do tego na końcu.
Mit 3: AI to coś dla wybranych
Innymi słowy: czy robić wielkie oczy, kiedy jakiś startup mówi, że „stosuje nowoczesne metody bazujące na AI”.
Nie. Wbrew pozorom można bardzo łatwo zacząć przygodę z AI.
Weźmy takie zagadnienie OCR (Optical Character Recognition). Polega na rozpoznawaniu tekstu na obrazkach i przetwarzaniu go na postać cyfrową.
Takie rozpoznawanie nie jest prostym zagadnieniem. Wymaga elastycznych rozwiązań – w końcu litery mogą być różne, mieć rozmaite kształty i ułożenie. Jeśli to zdjęcie, a nie skan, to dochodzi też mnóstwo kwestii związanych z oświetleniem.
Z tego względu w tej metodzie stosuje się sieci neuronowe. Kiedyś by się zaliczała do uczenia maszynowego. Obecnie takie rzeczy reklamuje się jako AI – przykładem program ABBYY FineReader, którego strona mówi obecnie o “latest AI-based OCR technology”. Mimo że używają bardzo podobnych rozwiązań jak lata temu i kiedyś ich tak nie nazywali.
Jeśli chcemy własnego OCR-a, mamy darmową bibliotekę – Tesseract. To już gotowe i dopieszczone rozwiązanie.
Przyjmijmy teraz, że mamy pomysł na startup sprzedający dużym korpo usługi analizowania dokumentów. Robimy następujące rzeczy:
- pobieramy Pythona;
- pobieramy Tesseracta i modele dopasowane do języka polskiego;
- pobieramy bibliotekę pytesseract, żeby było jeszcze łatwiej;
-
dodajemy gdzieś do kodu trzy krótkie linijki:
import pytesseract def recognize_text( image ): return pytesseract.image_to_string( image ) -
Ogłaszamy się w materiałach reklamowych jako AI-powered document analysis. Kasa spływa!

I zasadniczo nie kłamiemy
 W końcu mamy jedną rzecz, którą gdzieś, jakoś się obecnie pod AI podciąga.
W końcu mamy jedną rzecz, którą gdzieś, jakoś się obecnie pod AI podciąga.
Powiecie, że trochę lekceważę branżę? Że na pewno robią coś bardziej ambitnego?
Być może. Ale pewne fakty nie napawają optymizmem. 40% europejskich startupów deklarujących, że stosuje sztuczną inteligencję, w rzeczywistości nie używa takich metod (źródło).
Dlaczego wciskają kit? Może dlatego, że to tam jest kasa i uwaga inwestorów.
Rekiny wodne można zwabić zapachem krwi, a rekiny byznesu słówkami, które są trendy. Jak AI czy blockchain. Obecnie jeden na 12 startupów twierdzi, że AI jest w centrum ich działalności (źródło jak wyżej).
Żeby już tak nie jechać po tej branży – czasem faktycznie muszą wymyślić coś sami. Zwłaszcza w kwestii metod zbierania i obróbki danych. Ale zaryzykuję stwierdzenie, że firm innowacyjnych działających „na froncie” AI jest dość mało, a większość korzysta z gotowców.
Ciekawostka
A jak się przedstawia sytuacja na tym froncie – tam gdzie tworzy się najnowocześniejsze rozwiązania?
Tam faktycznie jest ciekawie, a warunki dość zaporowe. Weźmy taki GPT-3 od organizacji OpenAI – obecnie najnowszy i najlepszy model do losowego generowania tekstu. Według wyliczeń koszt samego treningu modelu to ok. 4,6 mln dolarów..
…A do tego dochodzi przecież koszt treningu wielu prototypów, wynagrodzenia dla badaczy, reszta infrastruktury… Sam Altman, prezes OpenAI, mówi wprost o dziesiątkach milionów dolarów.
Tak, nowoczesne AI to drogi biznes.
Podsumowując: mit o niedostępności AI można obalić. Chyba że mówimy o naprawdę nowoczesnych i specjalistycznych modelach.
Wracając do wcześniejszego pytania – nie, nie trzeba robić „wow”, kiedy ktoś stwierdzi, że u niego w firmie używa się sztucznej inteligencji. Teraz łatwo to robić. A jeszcze łatwiej mówić.
Mit 4: Roboty Facebooka zaczęły tworzyć własny język
Mocno powiązane z mitem o świadomości, ale moim zdaniem zasługuje na osobny wątek. To idealny przykład medialnego chaosu, dezinformacji i niezrozumienia tematu, czyli wszystkiego, co mnie najbardziej irytuje w przedstawianiu tematu AI szerszej publiczności.
Być może słyszeliście o tej sprawie. Kiedyś było o niej głośno. W mediach na całym świecie pojawiły się sensacyjne nagłówki, takie jak mój ulubieniec:

Źródło: innpoland.pl
Jeśli jest jakieś bingo dla clickbaitów z AI, to chyba je mamy! Co gorsza, ten portal wymienia „technologię” jako jedną ze swoich specjalności. Dlatego skontrujmy ten nagłówek bez żadnej litości:
-
„Roboty”.
Roboty miałyby postać fizyczną, jak te gęby ze Stocka z początku wpisu. To były chatboty – programy komputerowe.
-
„Własny język niezrozumiały dla ludzi”.
Czyt. losowe angielskie słowa ułożone w bezsensowne zdania. Tak już czasem bywa, że ktoś źle określi warunki początkowe i potem cały długi trening modelu idzie na marne.
-
„Przestraszyli się”.
Zobaczyli, że program tworzy bzdury. Spisali go na straty, wzięli się za łatanie błędów i tworzenie nowego.
Czy Wy byście się przestraszyli Excela, gdyby wyświetlił Wam inny wykres niż chcieliście, bo zaznaczyliście złą kolumnę?
Sposób opisywania tej całej sprawy w mediach osobiście skrytykował jeden z autorów opisywanego badania:
(…)
Analyzing the reward function and changing the parameters of an experiment is NOT the same as “unplugging” or “shutting down AI”. If that were the case, every AI researcher has been “shutting down AI” every time they kill a job on a machine.
Źródło: post autora na FB. Skróty moje.
Przedstawianie AI w taki sposób robi ludziom wodę z mózgu. I jak tu się dziwić, że potem otrzymujemy chaos, zdjęcia robotów, debaty o dobroduszności albo złej woli maszyn?
W każdym razie walka z dezinformacją to sprawa na dłużej. Na razie cieszmy się jednym obalonym mitem – nie było żadnego własnego języka robotów ani paniki badaczy.
Podsumowanie
Mam nadzieję, że trochę odczarowałem kwestie związane z AI albo przynajmniej wywołałem wzruszenie ramion u tych, dla których ta kwestia od początku była oczywista.
Jeśli jakiś szaman marketingu obieca Wam albo działowi Waszej firmy „inteligentne rozwiązania AI” za miliony monet, to proponuję go słuchać z błyskiem w oczach… błyskiem politowania.
Wracając do zimy AI, którą zostawiłem na teraz – długie przerwy w badaniach nad AI wynikały nie tylko z braku możliwości, ale też z rozczarowań. Po początkowych niestworzonych obietnicach inwestorzy odkrywali, że obiecuje im się gruszki na wierzbie. Strumień pieniążków wysychał, a badacze rozchodzili się do bardziej obiecujących dziedzin.
Zima AI była skutkiem rozdmuchanych oczekiwań, wynikających z pochopnych obietnic jej twórców, zawyżonych oczekiwań użytkowników i powszechnego promowania w mediach.
Źródło: AI Winter na Wikipedii. Tłumaczenie moje.
Brzmi znajomo? ![]()
Łatwo sprzedawać obietnice, straszyć „idźcie w to, bo was przyszłość ominie” i dmuchać bańkę oczekiwań. Ale bańki mają to do siebie, że po rozdęciu w końcu pękają. Z niezbyt fajnymi konsekwencjami.
Prawdziwe śnieżne zimy sprzed kilku lat mogą się już nie powtórzyć. Ale zimy AI sprzed kilkudziesięciu mają szansę!
Tym niemniej uczenie maszynowe to ciekawa działka, lubię ją i jeszcze nieraz zagości na łamach bloga. Więc życzę jej, żeby jeszcze trochę trzymała się w zdrowiu.
Podobnie jak Wy! ![]() Do zobaczenia w kolejnym wpisie.
Do zobaczenia w kolejnym wpisie.
Anonim 1
(…) Hawking wielokrotnie ostrzegał przed sztuczną inteligencję, ale z ludźmi to jak z wyznawcami sekty - obudzą się gdy będzie już za późno.