
Jak nie zakrywać poufnych informacji
Uczymy się na (cudzych) błędach.
Ten wpis będzie krótki i treściwy. Do jego stworzenia zainspirowała mnie poboczna dyskusja na forum Hacker News dotycząca pewnego artykułu prasowego.
Mianowicie: ktoś w komentarzach podlinkował obrazek, w którym nazwy plików rozmyto w programie graficznym. Ktoś inny napisał, że lepiej żeby to nie było nic tajnego. Bo przy odrobinie pracy dałoby się odwrócić efekt rozmycia i odczytać tekst.
Już nieraz słyszałem o wpadkach, kiedy autor wierzył że coś usunął, a jedynie to przykrył.
Dlatego powstał ten wpis. Pokażę tu kilka pułapek związanych z ukrywaniem informacji w popularnych plikach graficznych, PDF-ach i im podobnych.
Może się czegoś nauczymy. A jeśli nie, to przynajmniej można spojrzeć na wtopki innych i się cieszyć, że to (jeszcze) nie nasze ![]()
Zakrywanie informacji na obrazkach
Przedstawiam Wam piękny szary prostokąt w stylu modern art:

Widzicie tu jakiś tekst? Szczerze wątpię.
A jednak jest! Jeśli pobierzecie obrazek (opcją Zapisz obraz albo stąd), otworzycie go w edytorze GIMP (inne też powinny działać) i podkręcicie kontrast na maksa, tekst będzie całkiem wyraźny.
Proces tworzenia obrazka wyglądał tak:
- Stworzyłem w Gimpie mały obrazek z tekstem „Test”;
- Wszedłem w opcję
Kolory > Jasność i kontrast, zmieniłem wartość na -126 (najniższa to -127); - Zapisałem plik jako JPG z jakością 90/100.
Tak to wyglądało:
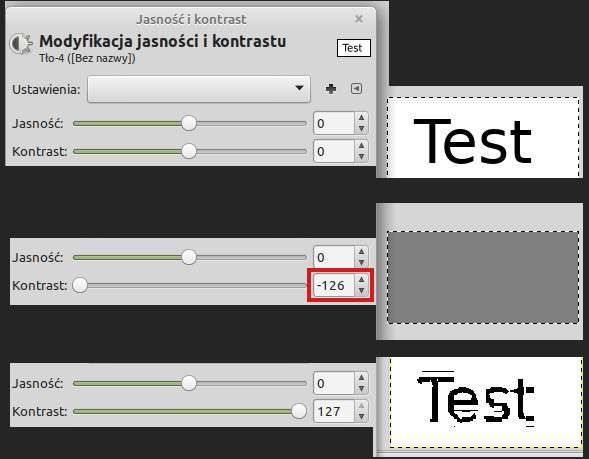
Jeden punkt robi różnicę. Gdybym dał suwak kontrastu najniżej, na -127, to tekst zostałby całkiem zniszczony. A przy -126 cały proces był łatwo odwracalny.
(Tekst jest postrzępiony jedynie dlatego, że nie zapisałem jotpega w pełnej jakości).
Pracując z komputerem, nie zawsze warto ufać oczom.
Podobnie jest ze wszystkimi algorytmami zamazującymi, rozmywającymi itp. Choć tekst wydaje się nieczytelny dla naszych oczu, na poziomie pikseli nadal mogą występować subtelne różnice.
Ktoś zdeterminowany mógłby eksperymentować, aż odkryje zakryte.
W takim razie co robić, żeby tajemnice nie ujrzały światła dziennego? Edytując obrazki, zakrywamy je jednolitym kolorem. Nie żadne rozmycia, nie żadne efekty, tylko prostokąt: cztery krawędzie i kolor między nimi.
(w Gimpie wystarczy nacisnąć R, żeby przejść do trybu rysowania prostokąta, a potem Ctrl+,, żeby wypełnić go kolorem).
Ta metoda jest prosta i skuteczna.
Ale – ważne! – odnosi się to tylko do prostych obrazków. JPG, PNG itp.
Próbując zrobić coś takiego z innymi plikami, takimi jak PDF, wpadlibyśmy w pułapkę. Już ją opisuję.
Zakrywanie informacji w PDF-ach
Dokładniej rzecz biorąc: nie tylko w nich. Dotyczy to wszelkich formatów, które przechowują nie tylko piksele, ale również tekst.
Pokażę na przykładzie pliku SVG.
Nasz plik zawierał moje bida-logo i napis „Ciemna strona”.
To bardzo poufny tekst, więc zakryłem go jednolitym, nieprzezroczystym, szarym prostokątem:

SVG ma wszelkie cechy obrazka – da się go otworzyć w programach do grafiki; mówi się że to grafika wektorowa. A jednak to coś więcej!
Gdyby to był zwykły obrazek, jak JPG, to po zakryciu nikt by nie wiedział, co się pod tym prostokątem ukrywa.
Ale SVG za kulisami to nie piksele, lecz seria instrukcji. Czasem czytelnych dla człowieka.
Jeśli zajrzymy do wnętrza mojego pliku, to sami zobaczymy:
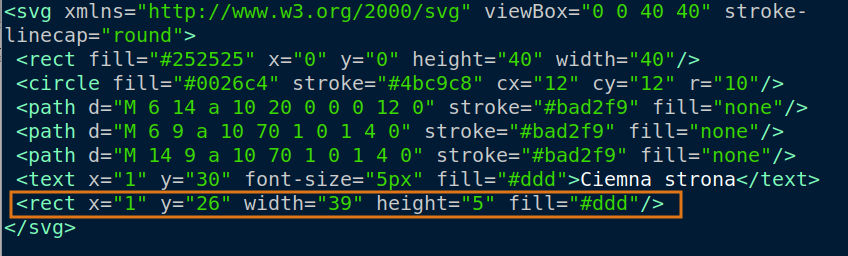
Bebechy naszego pliku SVG.
W formie screenshota, żeby tekst nie „wylewał się” poza ekran.
Pomarańczową ramką otoczyłem element odpowiadający szaremu prostokątowi.
A nad nim? Wyraźnie widać cały nasz tekst.
Jeśli chcecie sami to sprawdzić, możecie pobrać mój plik.
Następnie otwieramy go jako tekst, na przykład w Notatniku.
W tym celu klikamy go prawym przyciskiem myszy, wybieramy Otwórz za pomocą... i znajdujemy Notatnik na liście.
Dokładnie tak samo działają PDF-y. Każdy dodany element to po prostu nowa instrukcja. Zakrywa tekst, ale go nie usuwa.
Różnica polega na tym, że PDF-y są potem kompresowane, więc nie poczytamy ich przez Notatnik, jak plików SVG.
Ale nawet najmniej techniczna osoba może otworzyć PDF-a w programie – choćby w Adobe Readerze – zrobić Ctrl+A, Ctrl+C i skopiować sobie cały tekst, łącznie z naszymi tajemnicami.
I nie są to teoretyczne rozważania. Wtopki z czarnymi prostokątami już wiele razy się zdarzały. Również ważnym i poważnym.
Polskie instytucje mamy na co dzień, więc pośmiejmy się z zagranicznych:
- australijska komisja lekarska ujawniła dane pewnej lekarki i jej syna;
- prawnicy Paula Manaforta, byłego szefa sztabu wyborczego Donalda Trumpa, ujawnili niechcący utajone szczegóły sprawy (dokument jest tutaj);
- opinia amerykańskiego sędziego federalnego zdradziła parę informacji na temat powiązań biznesowych Apple;
- Z podobnie „utajonej” korespondencji wewnętrznej Facebooka dowiedzieliśmy się, że rozważali sprzedawanie firmom pełnego dostępu do danych użytkowników.
W jaki sposób zapobiec takim gafom?
Jednym ze sposobów jest użycie wbudowanych funkcji redagowania dokumentów. Ma takie coś np. Adobe Acrobat. Nadal jest tu jednak miejsce na ludzki błąd, gdybyśmy wybrali nie tę opcję.
Istnieje również rozwiązanie nuklearne, ale pewne.
Można skonwertować każdą stronę na obrazek, pozakrywać sekrety jednolitymi prostokątami, a potem ewentualnie połączyć te obrazki w nowego PDF-a.
Jeden minus taki, że drastycznie urośnie rozmiar pliku. Ale uznajmy, że to do przeżycia.
Bardziej może nas zaboleć druga sprawa: w ten sposób niestety stracimy cały tekst.
Na szczęście można go odzyskać poprzez OCR (Optical Character Recognition). Na pewno nie będzie w 100% dokładny – a po jego dodaniu ciężkie pliki staną się jeszcze cięższe – ale odzyskamy choć częściowo możliwość przeszukiwania PDF-a.
W każdym razie po takim przemieleniu w pliku nie zostaną już żadne sekrety ![]()
Gdybyście kiedyś musieli usuwać tajemnice z dokumentów, to życzę powodzenia! A gdyby była wtopa, to pamiętajcie, że zawsze mogło być gorzej. Jak u naszych elitarno-prawniczych Amerykanów.
Bonus: konkretne programy
Wyżej były ogólniki, a tutaj będą konkretne nazwy!
Zakładam, że zakrywamy coś sekretnego, więc żadne rozwiązania internetowe nie wchodzą w grę. I bardzo dobrze! Klasyczne offline’owe programy w zupełności wystarczą.
Do samego zakrywania obrazków prostokątami wystarczy GIMP albo nawet Paint. Innych nie używałem, więc nie wiem czy polecić. Natomiast aby zmienić PDF-y tekstowe w obrazkowe, musimy wykonać kilka kroków:
1. Zapisanie każdej strony PDF-a jako osobnego obrazka
To również można zrobić przez GIMP-a, o ile korzystamy z wersji 2.10 lub nowszej.
Wtedy po prostu klikamy PDF-a prawym przyciskiem, otwieramy w GIMP-ie. A następnie działamy zgodnie z tą instrukcją (po angielsku).
A jeśli nie boimy się konsoli?
Wtedy warto zainstalować Popplera – zestaw programów konsolowych do pracy z plikami PDF. Ma wersje na systemy Linux, MacOS oraz Windows.
Jeśli mamy przykładowo PDF-a o nazwie jakis.pdf, to otwieramy konsolę w tym samym folderze co on i uruchamiamy przez nią taką komendę (wpisując tekst, a potem wciskając klawisz Enter):
Gdybyśmy kopiowali stąd tekst do wklejenia w konsolę na Linuksie, to warto pamiętać, że robi się to skrótem Ctrl+Shift+V.
Skończymy z plikami JPG – po jednym na jedną stronę. Jeśli jeszcze nie zakrywaliśmy informacji jednolitymi prostokątami, to teraz jest na to dobry czas.
2. Połączenie obrazków w jednego PDF-a
Czas na połączenie obrazków z poprzedniego kroku. W jednego PDF-a, w którym każdy obrazek jest osobną stroną. Nie widzę łatwego sposobu na zrobienie tego w GIMP-ie, ale to nic!
Na Windowsie wystarczy je wszystkie zaznaczyć, wybrać opcję Drukuj, a potem Drukuj do pliku.
Z MacBookami nie mam doświadczenia, ale jeśli wierzyć tej instrukcji, działa to podobnie.
Na Linuksie też się da na kilka sposobów.
3. (Opcjonalnie) Nałożenie tekstu na naszego obrazkowego PDF-a
OCR nigdy nie będzie w 100% dokładny, ale zawsze daje jakąś możliwość przeszukiwania tekstu. Przy obrazkowym PDF-ie byłaby zerowa.
Do nałożenia tekstu możemy użyć komercyjnego programu ABBYY FineReader (tylko na Windowsa i Maca). Gdy już nam rozpozna co trzeba, wybieramy opcję zapisania pliku jako PDF, z tekstem pod warstwą obrazkową.
A jeśli nie boimy się konsoli?
Można zamiast płatnego programu zainstalować darmowego Tesseracta (tutaj nieformalne instrukcje, a tutaj Tesseract na Windowsa).
Tesseract czyta tylko obrazki, więc najlepiej go użyć zaraz po kroku 1, pomijając krok 2 (łączenie obrazków w PDF-a).
W tym celu w tym samym folderze musimy stworzyć plik tekstowy (powiedzmy obrazki.txt), w którym – linijka pod linijką – będą wymienione pliki z obrazkami, które chcemy połączyć w PDF-a.
Jeśli obrazków jest tylko kilka, możemy nawet stworzyć ten plik ręcznie. Ale szybciej będzie konsolką. Na Windowsie wpisujemy w nią:
Na systemach Linux i MacOS:
Usuwamy z pliku tekstowego te nazwy plików, które nie są obrazkami. Upewniamy się, że mamy go w tym samym folderze co obrazki. Po czym odpalamy Tesseracta:
Po powyższej komendzie powstanie nam plik po_ocr.pdf. Zawierający zarówno obrazki stron, jak i rozpoznany tekst.
Jeśli spróbujemy w naszym końcowym PDF-ie zaznaczyć i skopiować jakiś widoczny tekst, to zobaczymy że to działa – lepiej lub gorzej.
Ale jeśli spróbujemy coś skopiować spod miejsc zakrytych prostokątami, to wyjdą nam co najwyżej losowe znaki. Co miało być niemożliwe do odczytania, to takie jest.
To tyle na dziś! Może kiedyś sklecę jakiś własny skrypt, bo wydaje się że jest popyt. A póki co – do kolejnych wpisów ![]()