
Opowieść podręcznej (pamięci)
Skarby w zakamarkach przeglądarki.
Witajcie w świątecznym wpisie!

Nasza przeglądarka – obojętnie, czy to szpiegujący nas Chrome, czy któraś z tych przyjaźniejszych – jest jak okręt, który pozwala nam bezpiecznie żeglować po wodach internetu i częściowo izoluje od groźnych rzeczy pływających w głębinach.
Na okrętowym kadłubie po wielu podróżach zaczynają się gromadzić różne rzeczy, niczym pamiątki z podróży. Algi, małże, rysy i wgniecenia…
Za ich główny odpowiednik w przeglądarce możemy uznać historię przeglądania, czyli po prostu listę stron, jakie odwiedziliśmy w przeszłości. Zapewne o niej słyszeliście.
Ale to tylko jeden z rodzajów rzeczy, które gromadzimy podczas internetowych wojaży. Inną z nich – podejrzewam że znacznie mniej znaną – jest właśnie pamięć podręczna (ang. cache).
Nazwa może być dla nas na tyle obca, że nawet jej nie zaznaczymy, rutynowo wybierając w opcjach rzeczy do wyczyszczenia.
To błąd! Pomijając fakt, że ta pamięć potrafi nabrać pokaźnych rozmiarów i zajmować miejsce na dysku, jest też cennym źródłem informacji dla wścibskich oczu.
W tym wpisie pokażę, w jaki sposób różni przykładowi złoczyńcy – od stalkerów, przez korporacje, nawet po przestępców chcących nas wrobić – mogliby wykorzystywać cechy pamięci podręcznej do swoich celów. I w jaki sposób można się przed tym chronić.
Na końcu, dla osób chętnych, zamieszczam również skrypt w Pythonie, który pozwoli nam przeglądać własną pamięć podręczną i odkrywać w niej ciekawostki ![]()
Spis treści
- Czym jest pamięć podręczna
- Pamięć podręczna w przeglądarce
- Ciemne strony pamięci podręcznej
- Jak się bronić?
- Bonus: skrypt do grzebania w pamięci podręcznej
Czym jest pamięć podręczna
Nazwy pamięć podręczna i angielskiego cache będę używał wymiennie. W kontekście wpisu oznaczają dokładnie to samo.
Najpierw spójrzmy krótko na znaczenie angielskiego terminu cache. Dosłownie oznacza ono skrytkę, miejsce ukrycia kosztowności.

Już w nieśmiertelnych Heroesach 3 pojawiało się słowo cache w odniesieniu do ukrytego skarbu.
P.S. Prawie zawsze wybierałem punkty doświadczenia zamiast złota.
Czytając o sprawach komputerowych, z pojęciem cache’a możemy się zetknąć praktycznie na każdym poziomie – od procesorów, przez programy, po szersze zagadnienie komunikacji internetowej.
To tak powszechna rzecz, ponieważ pozwala osiągnąć coś, co pewnie większość z nas sobie ceni – oszczędzić sobie niepotrzebnej i powtarzalnej roboty.
Spójrzmy na przykład z życia.
Jesteśmy głodni, tak jak ja w tej chwili. Chcemy sobie zrobić wypasione spaghetti bolognese. W tym celu musimy pokroić cebulę, pieczarki i może coś jeszcze.
Którą z metod działania wybierzemy? Taką:
- Wyjmujemy nóż i deskę
- Kroimy cebulę
- Kroimy pieczarki
- Chowamy nóż i deskę
A może taką?
- Wyjmujemy nóż i deskę
- Kroimy cebulę
- Chowamy nóż i deskę
- Wyjmujemy nóż i deskę
- Kroimy pieczarki
- Chowamy nóż i deskę
Chyba każdy myślący człowiek wybrałby wersję pierwszą! Raz naszykować to, czego planujemy użyć, a potem używać tego aż do końca.
Pamięć podręczna może przyjmować wiele różnych postaci, ale łączy je jedno – to miejsce, w które odkładamy różne rzeczy, żeby mieć do nich szybki dostęp. W naszym kulinarnym przykładzie pamięcią podręczną jest blat stołu.
Z kolei samą czynność umieszczania rzeczy w takim podręcznym miejscu można by nazwać cachingiem albo, spolszczając, cache’owaniem.
 Ciekawostka
Ciekawostka
Na caching czasami mówi się również tabling (dosł. tablicowanie). Brzmi dziwnie, ale jest w tym sens!
Jeśli przytrafiły Wam się zajęcia ze statystyki, to możecie kojarzyć takie coś jak tablice statystyczne. Zawierające gotowe rozwiązania popularnych wzorów dla często używanych liczb.
Dzięki tablicom nie musimy podstawiać liczb do dużych wzorów i liczyć wszystkiego od zera. Podglądamy jedynie wyniki, które ktoś kiedyś obliczył. Takie tablice przyspieszają naszą pracę, jak pamięć podręczna w komputerze.
Pamięć podręczna w przeglądarce
Tyle tytułem ogólników, pasujących do każdego rodzaju pamięci podręcznej. Teraz skupimy się stricte na tej w przeglądarce.
We wszystkich przeglądarkach pamięć podręczna jest folderem. Znajdują się w nim różne pliki:
Jeśli ikonki wydają się Wam obce, to dlatego że to przeglądarka systemu Linux Mint. Swoją drogą polecam.
Porada
W przypadku Firefoksa możecie łatwo sprawdzić, gdzie jest Wasz folder z pamięcią podręczną, wpisując w pasek adresu about:cache.
Swoją drogą to fajny sposób na przeglądanie, co mamy w cache’u; są tam również pliki, które nie zostaną zapisane na dysku.
Co do innych przeglądarek:
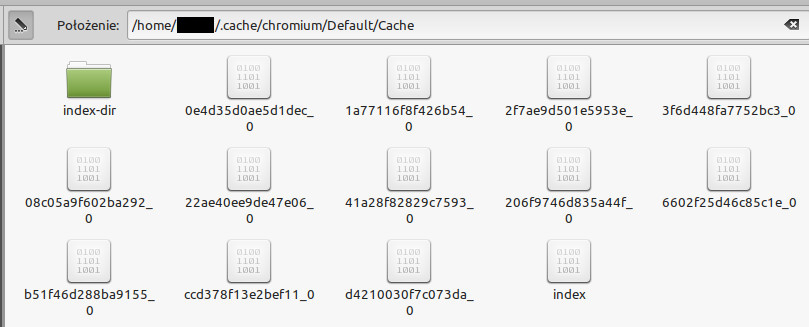
Chromium na Linuksie – pamięć podręczna znajduje się w folderze .cache/chromium/Default/Cache.
Chrome na Windowsie – w AppData\Local\Google\Chrome\User Data\Default\Cache.
(Windows ogólnie wrzuca do podfolderu AppData\Local w folderze głównym).
Ten folder wyżej to cache przeglądarki Chromium na Linuksie.
W jego wnętrzu zawsze mamy podfolder index-dir oraz plik index. A wszystkie pozostałe pliki odpowiadają rzeczom, które nasza przeglądarka odłożyła na później.
To tak zwane pliki binarne. Nie mają żadnego rozszerzenia i są swego rodzaju pojemnikami na inne pliki, zwykle już o znanych typach. W każdym z nich mamy komplet złożony z oryginalnego pliku, a także garść informacji uzupełniających (jak link do źródła, z którego go pobraliśmy, albo datę i godzinę pobrania).
W każdym takim „pojemniku” może być obrazek, zestaw czcionek, plik JavaScript, cała strona internetowa… co nam tylko do głowy przyjdzie.
Szukając tradycyjnymi metodami, nie znaleźlibyśmy plików z pamięci podręcznej (w końcu co nam da wypatrywanie wszystkiego, co kończy się na .jpg, kiedy te pliki nie mają rozszerzenia? Również ich struktura nie pasuje do powszechnych rodzajów).
A jednak tu są, na widoku. Z każdego z nich, jeśli tylko wiemy jak, możemy wyciągnąć całkiem czytelny plik.
Przykład z Ciemnej Strony
Żeby pokazać przykłady skarbów z pamięci podręcznej, zrobiłem parę testów na znanych sobie stronach. Zacznijmy od Ciemnej Strony! A właściwie od względnie nowego wpisu, poświęconego plikom cookies i fikcyjnej kawiarni Facebucks.
Na potrzeby testów odpaliłem w jednym oknie Chromium (nie Chrome’a!) i wyczyściłem doszczętnie dane przeglądania. Równocześnie w drugim oknie obserwowałem wnętrze folderu z jego pamięcią podręczną.
Następnie wkleiłem w pasek przeglądarki link prowadzący do wpisu. Przeniosło mnie na oczekiwaną stronę. A w mojej pamięci podręcznej przybyło plików! Zresztą tych samych, które pokazałem na wcześniejszym screenie.
Użyłem swojego skryptu badawczego, żeby wybrać spośród tych plików obrazki i skopiować je do osobnego folderu. Tak się w nim prezentowały:
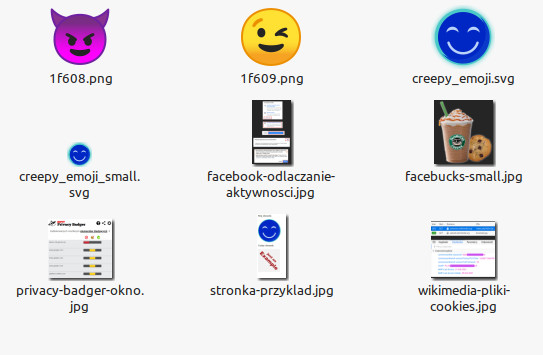
Niektóre nazwy plików i obrazki są dość charakterystyczne. Ktoś mógłby je teoretycznie wpisywać w wyszukiwarkę (albo wklejać w wyszukiwarkę obrazkową) i na tej podstawie ustalić, z jakiej strony pochodzą.
Tylko że w tym przypadku byłby to zbędny wysiłek; pliki z pamięci podręcznej same zawierają pełne linki do źródeł, nie trzeba ich zgadywać. Ktoś zaglądający w cache’a szybko by odkrył, jaki wpis wyświetliłem.
Ciemna Strona jest statyczna, a do każdego wpisu prowadzi osobny link.
Jedna strona = konkretny zestaw plików z pamięci podręcznej = jedna pozycja w historii przeglądania.
Dlatego w tym przypadku oba źródła informacji, historia i pamięć podręczna, wydają się sobie równe; może z lekką przewagą historii za jej zwięzłość i czytelność.
Tym niemniej zawsze może się zdarzyć, że ktoś wyczyści historię, a pamięci podręcznej nie. Warto wiedzieć, że w takim przypadku cache będzie najlepszą – bo jedyną – kopalnią informacji.
Przykład z Facebooka
Wykonałem podobny test jak poprzednio. Wyczyściłem do zera pamięć podręczną, a potem wszedłem na stronę główną facebook.com. Poczekałem, aż załadują się aktualności, otwarłem miniaturkę czatu, lekko przewinąłem wiadomości.
Jeśli nie macie większego doświadczenia z Facebookiem, to uściślę: wszystko tu jest ładowane dynamicznie i na raty. Choć oglądam coraz więcej treści, nie muszę wchodzić na osobne podstrony; cały czas jestem pod adresem facebook.com.
Dlatego, gdy po swoim teście zerknąłem na historię przeglądania, znalazłem jedynie stronę główną Fejsa:
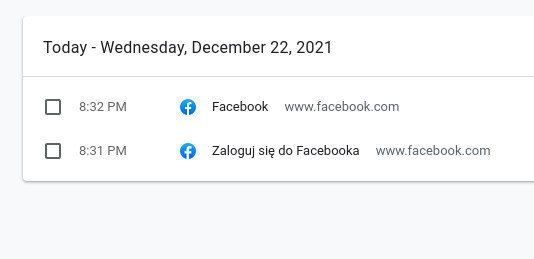
W moim przypadku to bardziej dwie strony, bo jedna to ekran logowania, a druga to główna facebook.com.
A w cache’u? Zapisały się tam (chyba) wszystkie obrazki, jakie mi się wyświetliły. Zarówno na stronie, jak i na czacie. Miniaturki znajomych, z którymi coś pisałem. Reklamy i ilustracje do wpisów, jakie akurat mi pokazało na tablicy.
Tutaj przykład jednego niewinnego zdjęcia, które mój znajomy dodał do grupowej konwersacji:
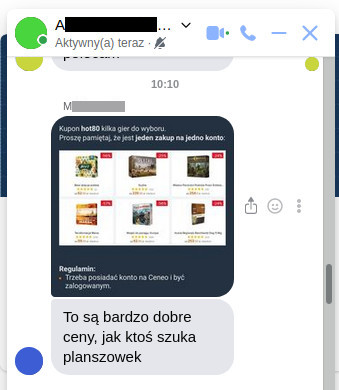
Ono również trafiło do miniaturek w cache’u, mimo że teoretycznie czat jest czymś prywatniejszym niż tablica. Gdybym kliknął zdjęcie, żeby je powiększyć, to do cache’a dołączyłaby również jego wersja w pełnej rozdzielczości.
W pamięci podręcznej była też miniatura krótkiego filmiku wrzuconego przez znajomą. Oznaczyła na nim inną osobę – tagiem w stylu @JAKAŚ_OSOBA, który po lekkim mrużeniu oczu dało się odczytać z miniaturki.
Ktoś z zewnątrz, zaglądając w moje obrazki, miałby nazwę jednego użytkownika na tacy.
Ten przykład pokazuje nam, że w przypadku dynamicznych stron pamięć podręczna potrafi zdradzać dużo więcej szczegółów niż historia przeglądania.
Ciemne strony pamięci podręcznej
Pliki, które zapisują się na naszym dysku niezależnie od zawartości. O których mało kto wie; a nawet gdyby wiedział, nie byłby w stanie ich wyszukać domyślnymi narzędziami systemu. A zarazem łatwe do otwarcia dla osoby, która będzie wiedziała czego użyć.
Brzmi jak przepis na potencjalną katastrofę? Co najmniej na trzy! Zapraszam do przemyśleń nad tym, co może pójść nie tak ![]()
Żyła złota dla stalkerów
Wyobraźmy sobie, że korzystamy z jakiegoś komputera – może publicznego w czytelni; może ze składaka wuja Janusza, którego odwiedziliśmy w święta; może nawet z własnego laptopa. Przyjmijmy, że sam komputer jest w 100% bezpieczny, nie ma żadnych wirusów ani programów monitorujących co robimy.
Mając poczucie bezpieczeństwa, odwiedzamy parę stron i logujemy się do kont na portalach społecznościowych. Czytamy wiadomości od znajomych.
Ale zachowujemy szczyptę ostrożności! Na koniec wylogowujemy się z kont i wybieramy opcję „Wyczyść historię przeglądania”, bo słyszeliśmy że tak warto robić.
Tylko że nie rozumiemy, czym jest ta opcja „Pamięć podręczna”… Może to te zakładki z ulubionymi stronami? To chyba lepiej nie usuwać? Zatem nie usuwamy.
Potem do tego samego komputera, z którego wcześniej korzystaliśmy, zasiada stalker (będę pisał w rodzaju męskim, ale oczywiście może to być też stalkerka! ![]() ).
).
Szemrana osoba w każdym razie. Nie musi mieć żadnych zdolności hakerskich. Wystarczy, że ma pendrive’a i minimum wiedzy, który folder skopiować.
A do przeglądania plików może użyć gotowych programów, jak Chrome Cache View.
Stalker(-ka) kopiuje cały folder z pamięcią podręczną i zabiera go ze sobą, żeby wykopać z informacji cenne rzeczy.
Przede wszystkim, patrząc na miniaturki i awatary różnych ludzi, może być w stanie ustalić naszą tożsamość. Być może nie od razu, być może trzeba będzie trochę przyglądać się awatorom i wyszukiwać je z osobna, potem patrzeć po znajomych. Ale to kwestia czasu.
W przypadku takiego Facebooka na pewno pomaga fakt, że w pierwszej kolejności zwykle ładowane są obrazki bliższych znajomych. Pozwala to znacznie zawęzić poszukiwania.
Nawet gdybyśmy korzystali z publicznego komputera, gdzie pamięć podręczna przyjmuje obrazki od różnych osób, ktoś mógłby łatwo porozdzielać zdjęcia z różnych kont, patrząc na godziny ich otrzymania.
Nowa duża porcja obrazków = nowy zalogowany użytkownik, któremu załadowały się inne miniaturki.
Poza tym wśród obrazków będą również te z naszych prywatnych konwersacji. Nowy dowód osobisty, który wysłaliśmy siostrze? Pinezka na mapie i kod do drzwi, jaki podaliśmy bliskiemu znajomemu dokarmiającemu kota pod naszą nieobecność? Zdjęcia, które powinny pozostać prywatne?
W pamięci podręcznej wszelkie wrażliwe dane mogą być na widoku. Jeśli ktoś je dorwie i połączy z naszą tożsamością, to wszystko może się zdarzyć.
Śledzenie przez korporacje
Tak już działa ten internet, że nasza przeglądarka przy każdym kontakcie z innymi stronami wysyła im kilka podstawowych informacji. Coś w rodzaju naszej wizytówki.
Właściciele stron mogą analizować te informacje, żeby rozpoznać, z jakimi innymi ich stronami wchodziliśmy w interakcję. Na tej podstawie mogą budować profil naszych zainteresowań.
Jeśli czytaliście moją najdłuższą serię, Internetową inwigilację, to pewnie jesteście już całkiem nieźle zaznajomieni z tym procederem ![]()
A przechodząc do meritum: jedna z wysyłanych informacji może być związana z pamięcią podręczną. Nazywa się ETag (skrót od Entity Tag, gdzie entity to takie bardzo ogólne pojęcie, coś w stylu „rzecz”).
W praktyce to długi ciąg znaków. Może wyglądać na przykład tak:
Źródło: opis ze strony Mozilli.
To atrybut opcjonalny, nie zawsze jest przesyłany. Jest swego rodzaju identyfikatorem pliku, takiego jak obrazek.
Kiedy nasza przeglądarka wyśle ten atrybut jakiejś stronie K, oznacza to że mówi „Mam w swojej pamięci taki obrazek. Czy coś się w nim zmieniło?”.
Serwer strony K porównuje ten identyfikator z tym, co ma u siebie. Jeśli nic się nie zmieniło, to krótko informuje o tym przeglądarkę. A ta bierze obrazek ze swojej pamięci, zamiast pobierać go od nowa. Unikamy wielokrotnego przesyłania tych samych rzeczy.
Gdyby stronka była prawilna i używała Etaga zgodnie z przeznaczeniem, wyłącznie do odciążenia przeglądarek, to tworzyłaby po jednym tagu dla każdej rzeczy (np. obrazka), a następnie wysyłała ten sam tag różnym osobom.
Stronka bardziej szpiegowska – często jakaś duża korporacyjna – tworzy zamiast tego osobne tagi dla różnych odwiedzających ją użytkowników. Dzięki temu wie, że osoba „legitymująca się” na stronie B konkretnym Etagiem to ta sama osoba, która wcześniej okazywała go na stronie A.
Wrabianie niewinnych osób
Mechanizm działania pamięci podręcznej niesie za sobą jeszcze jedną niepokojącą implikację. Co raz odczyta nasza przeglądarka, to trafia na nasz dysk.
Pojawia się tu ciekawy problem natury prawnej. Otóż niektóre obrazki są zakazane. W przypadku polskiego prawa samo ich posiadanie jest karalne.
Nie będę tu rzucał nazwami, bo szkoda by było, gdyby naiwne algorytmy Ej-aj przypisały mojego bloga do tych kategorii. Ale wiemy, o co chodzi – rzeczy z udziałem nieletnich.
(Mogłyby to być też dowolne inne obrazki zakazane prawem jakiegoś kraju; choćby materiały antyrządowe w państwach totalitarnych).
Wyobraźmy sobie, że jakiś troll internetowy wrzuca zakazane obrazki na forum, które akurat przeglądamy. W momencie, kiedy to robi, przeglądarka automatycznie je zapisuje w naszej pamięci podręcznej.
Mogliśmy tych obrazków nie widzieć (bo nowy komentarz dopiero się pojawił w dolnej części ekranu, my patrzymy tylko na pierwszy od góry). A jednak w momencie, gdy jakiś złoczyńca je wrzucił, trafiły na nasz dysk. Staliśmy się posiadaczami. Gdyby prawo było zero-jedynkowe, to również przestępcami.
Ciekawostka
Powiecie, że to absurd? A jednak kiedyś na forum Wykop.pl miała miejsce podobna afera!
Banda trolli wrzuciła tam w nocy posta z zakazanymi obrazkami. Niektórzy użytkownicy dali pod tymi zdjęciami plusy.
Niekoniecznie przez swoje skłonności; rzekomo mieli włączone programy do automatycznego plusowania wszystkich nowości, żeby ich konta wydawały się aktywniejsze (ach ta gamifikacja…).
Ale plusowanie podbija widoczność. W związku z tym takie osoby de facto udostępniały nielegalne treści. Właściciel serwisu zapowiedział, że zgłasza na policję również plusujących. Finału sprawy nie znam.
Ale powiedzmy, że jednak istnieje jakaś sprawiedliwość i w sytuacji takiej jak wyżej (tzn. sprzed ciekawostki) uznaliby naszą niewinność. Jasna sprawa, wiele pokrzywdzonych osób, świadkowie itp.
Gorzej, jeśli ktoś bardzo chce nas wrobić. W takim wypadku może założyć stronę X – minimalistyczną, na pozór niewinną, ale zawierającą ukryty obrazek, który jako źródło ma ustawioną cudzą stronę Y z nielegalnymi treściami.
Osoba wrabiająca zachęca nas życzliwie do odwiedzenia strony X. Kiedy to robimy, za kulisami przeglądarka pobiera kompromitujący nas obrazek i zapisuje go na dysku.
Jednocześnie nasz wróg zawiadamia anonimowo policję, że możemy mieć coś nielegalnego. A ze swojej strony X usuwa link do szemranej Y, żeby zatrzeć ślady.
Nie mamy pojęcia o istnieniu tego obrazka, więc chętnie dopuszczamy policję do naszego komputera. „To na pewno jakaś pomyłka, nie mam nic do ukrycia”.
A co znalazłby w naszej pamięci technik przeglądający pliki? Zakazany obrazek, a w informacjach uzupełniających – link do jego źródła, znanej strony Y z zakazanymi treściami.
Żadnego tropu ukazującego stronę X jako winną.
Znalazłaby się co najwyżej jej nazwa w historii przeglądania, ale już nie zawierałaby linków do niczego nielegalnego. Zresztą tak naprawdę, nie znając się na działaniu przeglądarki, nie mielibyśmy pojęcia co się stało. Moglibyśmy do końca nie wiedzieć, kto był naszym wrogiem.
Nie mam pojęcia, na ile taka sytuacja jest realna od strony prawnej, czy faktycznie tak trudno byłoby się wybronić. Ale od strony technicznej wydaje się niepokojąco możliwa.
Jak się bronić?
Każdy z trzech przypadków, które wcześniej opisałem, wymaga osobnej metody przeciwdziałania. Ale na szczęście wszystkie sprowadzają się do paru kliknięć na krzyż.
Zanim zaczniemy, jeszcze tylko drobna uwaga: jeśli usuwamy rzeczy od jakiejś strony z pamięci podręcznej, a potem wracamy na tę stronę, to wszystko załaduje nam się od nowa.
Jeśli zależy nam na oszczędzaniu transferu danych (na przykład korzystamy z internetu mobilnego), to lepiej stosować opisane metody ostrożnie.
Przed stalkerami
Przede wszystkim czyśćmy pamięć przeglądarki. Zwłaszcza jeśli użyjemy komputera bardziej publicznego, do którego może później mieć dostęp inna, niekoniecznie fajna osoba.
We wszystkich przeglądarkach, które sprawdzałem, należy najpierw otworzyć opcje historii, potem wybrać opcję w stylu Wyczyść dane przeglądania. Powinno pokazać nam się okno, w którym zaznaczamy, co dokładnie chcemy wyczyścić. W tym miejscu zaznaczamy opcję Pamięć podręczna i klikamy przycisk potwierdzający. I już!
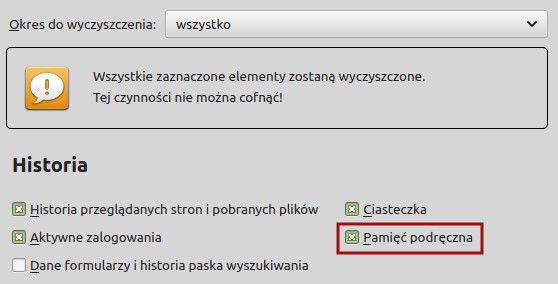
Tutaj na przykładzie Firefoksa.
Warto również, zwłaszcza jeśli korzystamy z publicznego komputera, przeglądać w trybie prywatnym (incognito). Nasza przeglądarka wydziela wtedy osobnego cache’a na czas przeglądania, a po zamknięciu przeglądarki go czyści.
Kolejna sprawa: jestem zdania, że warto pousuwać z wiadomości bardziej prywatne obrazki. Zdjęcia swoich dokumentów i inne fotki, których raczej byśmy nie pokazywali szerszym internetom.
Nawet jeśli sami będziemy się pilnować, to pamiętajmy, że konwersacja ma przynajmniej dwie strony.
Druga osoba może sobie siąść przy publicznym komputerze. Weźmie ją na wspominki i zajrzy w naszą dawną rozmowę, a potem nie wyczyści cache’a.
W ten sposób na dysku jakiegoś bibliotecznego albo uczelnianego komputera, ku uciesze potencjalnych stalkerów, zostaną nasze zdjęcia.
Na takim Facebooku/Messengerze możemy usunąć wiadomość, klikając ikonę trzech kropek obok niej i wybierając Usuń → Cofnij wysłanie do wszystkich.
Ogólnie proponuję patrzeć na internetową korespondencję w ten sposób: to nie jest przekazywanie listów z ręki do ręki. To zostawianie ich w ustronnym miejscu, z nadzieją że tylko jedna osoba je odnajdzie.
Przed korporacjami
…Czyli, przypomnę, przed śledzeniem przez atrybut ETag.
Ręczne czyszczenie pamięci albo używanie internetu w trybie incognito też by tu działały.
Ale musielibyśmy to robić na tyle często, że stałoby się to niepraktyczne i uciążliwe – wylewalibyśmy dziecko z kąpielą, pozbawiając się pamięci podręcznej, a zatem szybkości i lekkości.
Dlatego lepiej mieć coś działającego w tle, co będzie nam automatycznie olewało atrybut ETag i nie przesyłało go znanym wścibinosom, a przy tym nie zmuszało nas do czyszczenia całego cache’a.
Takim czymś jest dodatek ClearURLs. W wersjach na różne przeglądarki:
Uprzedzę, że akurat funkcji blokowania Etagów nie testowałem. Ale sam dodatek jest dość popularny i ma inne fajne bajery (głównie związane z czyszczeniem linków), więc tak czy siak można z niego korzystać, na zasadzie „minimum dodatków, maksimum funkcji”.
Inna propozycja to dodatek PrivacyPossum. To rozwinięcie popularnego Privacy Badgera o kilka bardziej radykalnych funkcji blokujących.
Uprzedzę jedynie, że PP od ponad roku nie był aktualizowany. Polecam bardziej dla ekperymentatorów.
Przed podrzuceniem plików
Zanim zostanę posądzony o paranoję: sam nie uważam kompromatów za realne zagrożenie dla większości z nas.
Gdyby ktoś chciał nas skompromitować, to miałby na to łatwiejsze sposoby niż jakieś fałszywe strony i zmuszanie do pokazania cache’a. Analogowe anonimy i pomówienia mogłyby wystarczyć ![]()
Ale być może chcemy czasem nuklearnej opcji? Zamiast pamiętać o czyszczeniu pamięci, zamiast blokować wybrane elementy… po prostu całkiem ją wyłączyć, żeby przeglądarka nic nam nie zapisywała na dysku?
To już całkiem realna potrzeba i da się to zrobić! Naciskamy Ctrl+Shift+I (jak „Irena”), żeby otworzyć opcje przeglądarki. Tam wchodzimy w zakładkę Sieć i klikamy Wyłącz pamięć podręczną.
Od teraz nie będzie nam zapisywało do cache’a żadnych plików (ale te wcześniej dodane musimy sami wyczyścić). Gdyby ktoś z zewnątrz chciał je dorwać, to musiałby mieć dostęp bezpośrednio do naszej pamięci RAM – a gdyby miał, to znaczy że mamy dużo większe problemy niż jakieś rzeczy z cache’a!
Warto pamiętać, żeby potem odhaczyć tę opcję, gdy znowu będziemy ufać swojemu komputerowi. W innym wypadku przeglądarka będzie nam znacznie wolniej działała, często pobierając od nowa rzeczy, które widziała sekundy wcześniej.
Uwaga
Zanim zaufacie tej opcji: upewnijcie się, czy na pewno działa. Kliknijcie ją, otwórzcie w osobnym oknie folder cache’a (najlepiej po czyszczeniu), odwiedźcie parę stron i patrzcie, czy faktycznie nie przybywa plików.
Piszę o tym, bo np. Chromium wymaga, żeby okno z narzędziami przeglądania było przez cały czas otwarte. Mimo że u mnie było, a opcję kliknąłem, wciąż jednak dodawało pliki do cache’a.
Kusi wyjaśnienie spiskowe, bo w końcu Google, śledzenie itp. ![]() Ale nie, to raczej bug związany z moim programem. Parę innych, neutralnych opcji też nie działa jak powinno.
Ale nie, to raczej bug związany z moim programem. Parę innych, neutralnych opcji też nie działa jak powinno.
W każdym razie: dla pewności sprawdźcie.
I to tyle z porad i omówień! Chętnych zapraszam do dalszej lektury o tym, w jaki sposób własnoręcznie można w tym cache’u szperać. A pozostałym życzę udanych świąt ![]()
Bonus: skrypt do grzebania w pamięci podręcznej
Też chcielibyście, moi praworządni czytelnicy, sprawdzić zawartość swojej (i tylko swojej) pamięci podręcznej?
Oto skrypt buszujący w cache’u, który skleiłem z twórczości mądrzejszych osób. Istnieje niezerowa szansa, że zadziała.
Uwaga
Ten skrypt, w przeciwieństwie do moich poprzednich, mógłby wzbudzić gniew jakiegoś antywirusa.
To dlatego, że bądź co bądź zagląda do folderów innego programu. Antywirus nie wie, że sami możemy tego chcieć, i może to oznaczyć jako potencjalne zagrożenie.
Ja niczego nie ukrywam; kod źródłowy skryptu macie na widoku, a każda osoba znająca Pythona może sprawdzić, czy bezpieczny ![]() .
.
Możecie go odpalić w dowolnym folderze. A on poszuka folderów z pamięciami podręcznymi dla znanych sobie par system + przeglądarka.
Gdyby skrypt miał problemy ze znalezieniem pamięci podręcznej, możecie obejść domyślne ustawienia, wprost wskazując mu ścieżkę oraz nazwę przeglądarki, z jakiej pochodzą pliki. W tym celu edytujcie zmienne CUSTOM_PATH i CUSTOM_BROWSER pod koniec pliku.
Skrypt nie wymaga dodatkowych modułów, wystarczy domyślny Python. Testowałem go na następujących kombinacjach systemów i przeglądarek:
- Linux Mint + Chromium / Firefox / Vivaldi / Opera
- Windows 10 + Firefox
I działał! Ale pamiętajmy, że autorzy przeglądarek zawsze mogą coś zmienić w formacie plików binarnych z cache’a, przez co ubiją skrypt. W takim wypadku trzeba by go mocniej zmienić, co jest póki co poza moim zasięgiem. Żeby mieć większą pewność działania, najlepiej trzymajcie się Firefoksa.
Przykłady zastosowań
Jednym z najczęstszych zastosowań może być wyciąganie plików z pamięci do osobnego folderu, żeby potem się z nimi zapoznać. Możemy do tego celu użyć kilku zwięzłych funkcji:
# Można wyciągnąć wszystkie pliki ze wszystkich folderów cache
extract_data()
# Albo tylko same obrazki
extract_images()
# Albo obrazki tylko z pamięci Firefoksa
extract_images( browser="Firefox" )
# Albo wszystkie obrazki z Ciemnej do folderu "Obrazki"
extract_images( url_text="ciemnastrona.com.pl", folder="Obrazki" )
Mamy też kilka funkcji do prostej, interaktywnej analizy:
# Zdobyć pliki png ze stron zawierających słowo 'facebook'
fb = get_entries( url_text="facebook", extensions="png" )
# Potem wyświetlić posortowane wyniki jeden pod drugim
show_entries( fb )
# Albo zrobić to co wyżej jedną komendą
show_entries( url_text="facebook", extensions="png" )
# Albo pokazujemy tylko te pliki, których adresy URL
# zawierają cztery cyfry pod rząd
# (korzystamy z wyrażeń regularnych)
show_entries( url_text="[0-9]{4}", regex=True )
Moje gotowe funkcje można oczywiście mieszać z domyślnymi Pythonowymi:
# Bierzemy z cache'a Chromium elementy, których linki
# zawierały parametry (co odczytuje funkcja urlparse).
# Potem zapisujemy je w osobnym folderze "Z_parametrami"
elems = get_entries( browser="Chromium" )
elems = [e for e in elems if urlparse(e.url).params]
extract_data( elems, folder="Z_parametrami" )
Ale myślę, że i tak osoby kreatywne znajdą własne zastosowania i odkryją w swoich (i tylko swoich!) pamięciach rzeczy, o jakich nawet mi się nie śniło.
Miłego przeczesywania pamięci!
Ach, swoją drogą… Mamy święta, więc naszykowałem świąteczny prezent!
Wśród obrazków z pamięci podręcznej odpowiadających temu wpisowi powinniście znaleźć niespodziankę, której zapewne nie widzieliście gołym okiem ![]() Spokojnie, jest niegroźna.
Spokojnie, jest niegroźna.