
Bobby kontra JSON – dane od Facebooka
Wpis z serii Kochajmy się jak bracia, analizujmy się jak Facebooki
W poprzednim wpisie opisałem, jak pobrać swoje dane z Facebooka. Kiedy już znajdą się u mnie na dysku, mogę je w fajny sposób analizować.
Na gwoźdź programu, czyli wiadomości z Messengera, jeszcze chwilę poczekamy. Cierpliwości! ![]()
Póki co oswoimy się z JSON-em (formatem danych), rozwiążemy podstawowe problemy i połączymy informacje z różnych plików od Fejsa we własną oś czasu, pokazującą między innymi, czego szukaliśmy i jakie profile odwiedzaliśmy.
 Dla niecierpliwych
Dla niecierpliwych
Wpis zawiera trochę fragmentów kodu. Jeśli Was nie interesują, swobodnie można je przeskakiwać. Nie są potrzebne do zrozumienia całości.
Jeśli wolicie całkiem ominąć sprawy techniczne, to możecie zacząć od wniosków z analizy.
Jeśli natomiast chcecie sam skrypt do tworzenia własnej „osi czasu”, to znajdziecie go na końcu strony.
Uwaga: Skrypt jest dopasowany tylko do danych z kategorii „Informacje o Tobie”. Nie jest w stanie obrobić innych, w tym w szczególności wiadomości z Messengera.
Reklamy na Facebooku – wprowadzenie
Na początek krótka motywacja dla całej tej analizy.
Facebook na swojej stronie (czyli www.facebook.com; w aplikacji może to działać inaczej) potrafi umieszczać reklamy w różnych miejscach. Czasem na stałe w górnym rogu, czasem wymieszane z normalnymi wpisami na tablicy.
Przykładowa reklama – tu dziwnie uboga – wygląda tak:
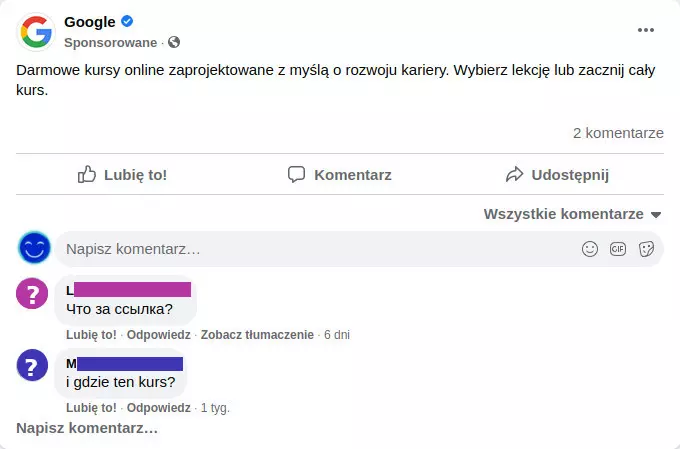
W jej prawym górnym rogu znajduje się ikona trzech kropek (1). Po kliknięciu w nią wyświetli się lista opcji. Wybieramy ostatnią, Dlaczego widzę tę reklamę? (2).
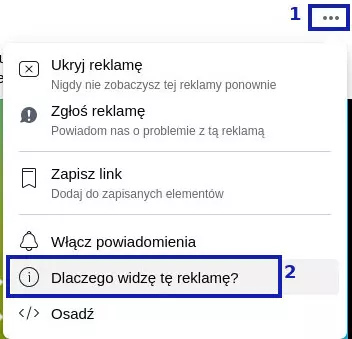
Wyświetlą się informacje o tym, na jakiej podstawie trafiła nam się akurat taka reklama. W moim przypadku zadecydował wiek, lokalizacja, język i zainteresowania:
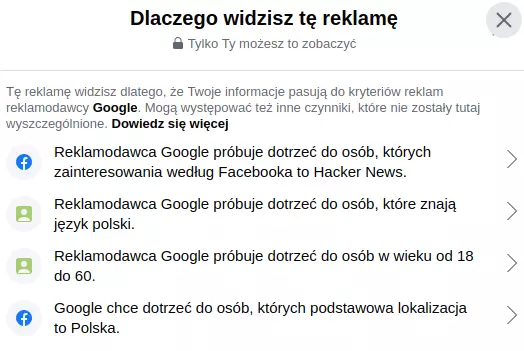
W tym przypadku moje zainteresowania odnoszą się po prostu do polubionej stronki (uprzedzając pytania – to forum stronki ogólnoinformatycznej. Hacker w znaczeniu zbliżonym do majsterkowicza, nie włamywacza).
Ale nieraz te moje rzekome zainteresowania potrafią mnie zdziwić. Dlaczego akurat takie?
To właśnie motywacja, jaka mi przyświecała. Spojrzeć na te same dane, na jakie patrzyły algorytmy Fejsa i spróbować zrozumieć, dlaczego przypisano mi określone rzeczy. Ale to cel na dłuższą metę.
Ten wpis opisuje pierwszy krok w tę stronę. Patrzę na względnie suche dane dotyczące wyświetleń i wyszukań. Pokazuję, że w połączeniu z datami nawet one potrafią opowiedzieć pewną historię.
Przygotowanie danych
Na początku pobrałem dane, zgodnie z metodą z poprzedniego wpisu. Do tej analizy wziąłem z Facebooka tylko dział „Informacje o Tobie”, z samego dołu listy plików do pobrania:
Format JSON, zakres dat od początku do końca, jakość mediów niska (tu bez znaczenia, bo to sam tekst).
Pliki pobrałem dnia 24.02. Zawierające je archiwum jest bardzo małe i lekkie. Mój plik zip „waży” łącznie około 150 kB, w porównaniu z ponad 2 GB wszystkich danych.
Pobranego zipa ułożyłem w osobnym folderze i rozpakowałem. Tak są w nim rozmieszczone pliki:
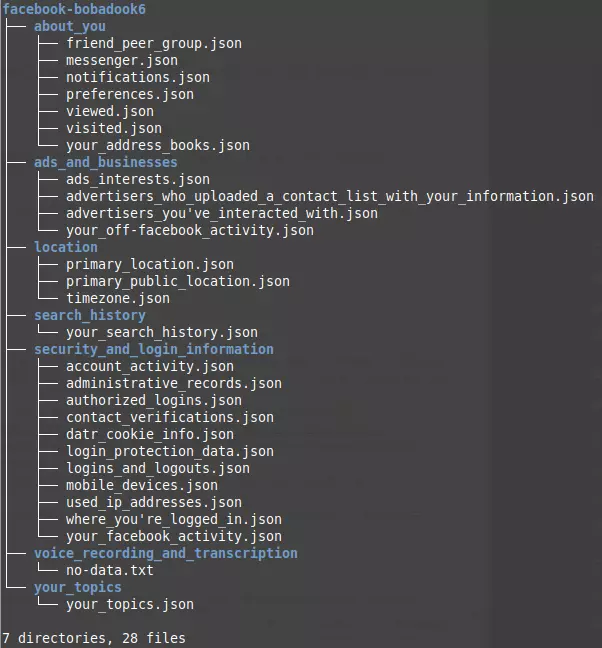
Wizualizacja układu plików wykonana programem tree na Linuksie.
28 plików rozbitych na 7 folderów. Głównie JSON-y. Do tego w folderze na transkrypcje jeden plik tekstowy z informacją o braku danych. Bo z żadnych transkrypcji nie korzystałem.
Po pierwszym kontakcie zacząłem grzebać w plikach i wypatrywać powtarzających się rzeczy.
O JSON-ie ogólnie nie musicie nic wiedzieć, poza tym że jest dość czytelny i przyjazny. Wnętrze przykładowego pliku .json wygląda tak:
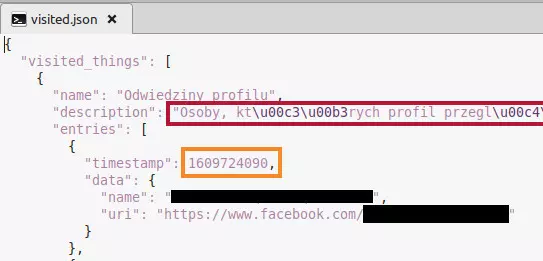
Pomarańczowym kolorem otoczyłem liczbę zwaną znacznikiem czasu (dosł. stemplem z czasem), kluczową dla naszej analizy. Bordowym przykład tekstu, który niestety nie uznaje polskich liter. Te i inne kwestie muszę rozwiązać, zanim będę w stanie wyciągnąć z danych coś sensownego.
Znacznik czasu
Te liczby przy atrybucie timestamp, jak nazwa wskazuje, pewnie mówią nam coś o czasie. Są dla nas bardzo ważne. Ale w jaki sposób przekształcić je na daty?
Po wpisywaniu w wyszukiwarkę haseł w stylu „python timestamp to date” wypatrzyłem rozwiązanie. Wystarczy załadować moduł od dat i stworzyć krótką funkcyjkę:
from datetime import datetime
def _convert_timestamp( timestamp ):
return datetime.fromtimestamp( timestamp )
Co by się stało, gdybyśmy jako znacznik czasu przyjęli 0 i odpalili naszą funkcję? Zobaczymy wtedy, co jest dla komputerów początkiem czasu, takim punktem zero dla dat!
Okazuje się, że nasze _convert_timestamp(0) dałoby datę… 1.01.1970 r.! To nasza data zerowa.
Dlaczego taka? Z prozaicznych powodów – ponoć to we wczesnych latach 70. określano standardy dla komputerów. Dla autorów wygodna była data: a) jak najokrąglejsza i b) nie sięgająca zbyt daleko w przeszłość.
Jeśli czasem zdarzyło Wam się spotkać absurdalne daty i gdzieś było w nich 1970, to już wiecie, skąd się to wzięło.
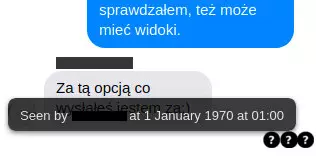
Zresztą, żeby daleko nie szukać, sam się z tym niedawno zetknąłem podczas jakiejś czkawki Messengera:
Kodowanie znaków
Mamy daty, czas uzyskać tekst.
Zwykle, kiedy otwierałem w Pythonie pliki JSON, nie było żadnych problemów z kodowaniem. Po prostu działało, miałem polskie litery i inne znaki. Dlaczego tutaj jest inaczej?
Jak się okazało, Facebook włożył dużo mniej serca w oddawanie danych użytkownikom niż w obrabianie ich pod kątem reklam. Takie kodowanie to ponoć ewidentny błąd z ich strony:
I can indeed confirm that the Facebook download data is incorrectly encoded (…). The original data is UTF-8 encoded but was decoded as Latin -1 instead. I’ll make sure to file a bug report.
Proponowane rozwiązanie jest na szczęście krótkie i treściwe:
def _fix_fb_text_encoding(text):
return text.encode('latin_1').decode('utf-8')
Wyświetlanie znaków emoji
Oprócz polskich znaków na FB mamy też pełno różnych emotek. Wyglądają ładnie, ale za kulisami są utrapieniem (tym razem nie z winy Fejsa).
Zacznijmy od tego, że są „większe”. Jeśli je zapisać w formie bajtów:
- Polska litera ą to
\xc4\x85. - Emotka puszczająca oko (
 ) to
) to \xf0\x9f\x98\x89.
Ten dziwny zapis może nam nic nie mówić, ale widać co dłuższe.
A to jeszcze nic! Np. piracka flaga to dwie osobne emoty – czarna flaga i czaszka – postawione obok siebie. A także dwa znaki pomocnicze, które nie są wyświetlane.
Z tych i może innych powodów niektóre programy nie radzą sobie z emotami. Na przykład najprostszy terminal Windowsa.
Mój IDLE w wersji 3.6.9, domyślny edytor Pythona, również nie daje rady i przy próbie wyświetlenia emoty wyrzuca błąd UnicodeEncodeError (choć podobno w nowych wersjach to poprawili).
Emoty na Facebooku lubią być wszędzie, w każdej nazwie. A ja mogę sobie prosić, ale nigdy nie wiem, w czym ktoś odpali mój skrypt. Dlatego postanowiłem to prowizorycznie załatać:
try:
print( emoji_text )
except UnicodeEncodeError:
print(bytes( emoji_text, 'utf-8'))
Gdyby program miał się rozkraczyć podczas wyświetlania tekstu, to zamieni emoji na zapis „bajtowy”, ten z iksami i ukośnikami. Może i nieczytelne, ale nie wymaga pobierania żadnych dodatków. A kontekst widać.
Nieregularność w danych
Bez wchodzenia w szczegóły: dane w formacie JSON są pogrupowane w słowniki (oznaczone nawiasami wąsatymi, {}) i listy (nawiasy kwadratowe, []). Jedne elementy mogą być zawarte w drugich – w liście słownik, w tym słowniku kolejne listy itd.
Żeby wyciągnąć z tego dane, trzeba robić to co w „Incepcji” – zagłębiać się poziom po poziomie w kolejne warstwy, aż znajdziemy szukany element.
W moim przypadku tym elementem było słowo timestamp. Gdyby wszystkie pliki miały podobną budowę, to mógłbym się po prostu zatrzymać po dotarciu do niego i zgarnąć wszystko wokół. Niestety tak nie jest:
- W niektórych plikach dane są podzielone na podgrupy (np. osobno odwiedziny na profilach, osobno na wydarzeniach);
- W pliku your_search_history.json na tym poziomie co znacznik czasu jest element data, w nim jeszcze parę zagnieżdżonych rzeczy. Te wartościowe najgłębiej.
Do tego jest tam element attachments, który w ogóle wydaje się niepotrzebny, bo zawiera to samo co data. - W pliku your_off-facebook_activity mamy na odwrót – nazwę strony na wyższym poziomie, a zdarzenia (wraz z ich znacznikami czasu) niżej. Czekając na znacznik, przegapilibyśmy istotne informacje.
Na pewno dałoby się stworzyć jakiś elastyczny program – zapamiętujący informacje z wyższych poziomów podczas schodzenia w głąb albo nawet odgadujący ich rodzaj.
Ale to zrobię później. Jestem leniwym człowiekiem, więc po prostu nie dzielę na podkategorie, traktując każdy plik jak jedną odrębną. Dodałem też osobne funkcje do obróbki tych dwóch plików, które wyłamują się ze schematu.
Ciekawostki z moich danych
Po rozwiązaniu problemów mogłem sobie sprawniej przeglądać dane – czasem skryptem, czasem po prostu otwierając JSON-y.
W ten sposób dowiedziałem się kilku rzeczy, które może nie znajdą miejsca na osi czasu, ale nadają się na ciekawostki:
-
Pliki z podfolderu security_and_login_information dotyczą głównie spraw technicznych.
Są tam adresy IP, pliki cookies, informacje o naszych urządzeniach… Bardziej pasują do „Internetowej inwigilacji” niż do tej serii, więc póki co je pominę.
-
Przy danych o odwiedzonych profilach Facebook pokazuje tylko jedne, najnowsze odwiedziny.
Upadł zatem mój pomysł na liczenie, ile razy obejrzało się czyjś profil lub stronę. Nie pośmieszkujemy z obsesyjnego przeglądania

…Ale! Informacje o jednorazowych wizytach również da się wykorzystać, piszę o tym niżej. -
Informacje o powiadomieniach i rzeczach wyświetlonych na tablicy (notification.json i viewed.json) są trzymane przez FB tylko przez 90 dni.
Powiadomienia moim zdaniem to głównie spam, więc niewielka strata.
A wyświetlonych rzeczy szkoda. Dzięki nim moglibyśmy lepiej rozumieć działanie Facebooka. Dlatego od teraz planuję „zamykanie kwartału” i archiwizowanie co 3 miesiące swoich danych. -
Z zaskoczeń: Facebook zbiera historię ustawień językowych (plik preferences.json).
Czyli jeśli na jakiś czas zmieniliśmy język na hiszpański, potem na angielski, potem na polski, to będzie to odnotowane na zawsze w kartotece, razem z datami.
-
Informacje o zainteresowaniach z ads_interests.json to cała kopalnia zaskoczeń. Niektóre dalekie od prawdy, a niektóre to zupełny zonk.
Dowiedziałem się na przykład, że interesują mnie tematy: Coaching, Dizziness, Most, Dominika, Ramię, Staw (akwen), Zatoka (geografia)

Reklam mostów jeszcze na profilu nie widziałem. Szkoda, kupowałbym. -
Jest też JSON z listą reklamodawców, którzy załadowali plik z informacjami o mnie.
Dziwnie tam dużo zestawów samochód + miasto: Acura of Rochester, Audi Columbia, Chrysler Dodge Jeep Ram of Calallen (to ostatnie kojarzy mi się z jakimś brytyjskim szlachcicem) i wiele innych.
-
…Z drugiej strony przypisane mi szersze tematy (your_topics.json) były zadziwiająco trafne.
Może wrzucają tam tylko pewniejsze, powtarzające się rzeczy.
-
Informacje o aktywności poza Facebookiem (your_off-facebook_activity.json) mówią z kolei o tym, kto przekazał Facebookowi dane o tym, że byliśmy na ich stronach.
Nie robią tego wprost, mailem czy faksem, tylko przez dodanie do swoich stronek elementów „społecznościowych” od FB.
U mnie takich interakcji jest tylko 25 (Firefox + dodatki uBlock Origin i Privacy Badger chyba robią swoje ). Ale niektóre osoby mają ich kilkaset.
). Ale niektóre osoby mają ich kilkaset. -
Najbardziej tajemniczy element to dla mnie książki adresowe (address_books.json).
Jest tam kilkanaście osób. Niektórych mam w znajomych (nawet bliższych), z niektórymi wymieniłem tylko pojedyncze wiadomości. Prawie do nikogo nie mam numeru telefonu, więc pierwsze skojarzenie odpada. Sprawa do zbadania.
Zajrzyjcie w swoje pliki, też na pewno znajdziecie coś ciekawego ![]() To tak osobiste sprawy, że trudno mi uogólniać.
To tak osobiste sprawy, że trudno mi uogólniać.
Moja oś czasu
Czas na gwóźdź programu. Po rozwiązaniu problemów z danymi trochę wszystko uogólniłem, uprościłem i zebrałem w jeden skrypt Pythona.
Oprócz tego zdecydowałem się nie uwzględniać danych z trzech plików, mimo że też zawierały znaczniki czasu:
- notifications.json – bo nie widziałem w powiadomieniach cennych informacji;
- used_ip_addresses.json – bo powtarzają się z innymi informacjami;
- viewed.json – bo to, że coś nam się wyświetliło na tablicy, nie wynika z naszego bezpośredniego działania.
Zostawiłem w skrypcie opcję łatwego włączenia tych plików do analizy, gdybym zmienił zdanie.
Gotowy skrypt zbiera listę moich działań z pozostałych plików – o ile tylko zawierały znaczniki czasu – i układa je w sposób chronologiczny. Powstaje taka oś czasu, tylko że o mnie, a nie o innych.
W podobny sposób może nas za kulisami postrzegać Facebook (chociaż oczywiście ma więcej danych; przypominam, że na razie użyłem tylko 150 kB z ponad 2 GB).
Mój skrypt, po odpaleniu w folderze z danymi, tworzy plik tekstowy z prostymi informacjami ułożonymi według dat. 3014 wydarzeń z mojego facebookowego życia.
Tu fragment mojej tekstowej osi czasu:
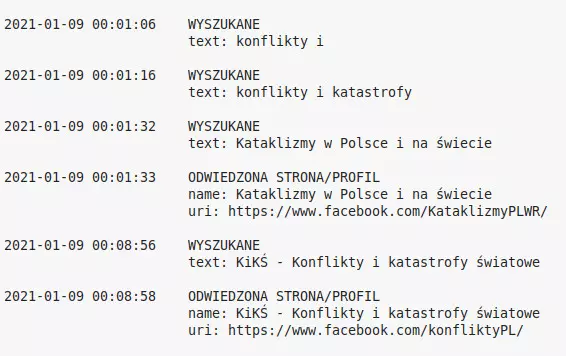
Dzięki połączeniu dwóch rodzajów informacji ukazuje się tutaj krótka historia z mojego życia:
- Nie miałem co robić po północy 9.01 (w noc z piątku na sobotę, jeśli wierzyć kalendarzowi).
- Szukałem strony, która mi się kojarzyła. Wpisałem w wyszukiwarkę Fejsa fragment jej nazwy.
- Chyba nic się nie pojawiło, bo wyszukałem ponownie, po dopisaniu jednego słowa.
- Pewnie zobaczyłem coś w podpowiedziach, bo przeszedłem na inną stronkę o zbliżonej nazwie. Spędziłem na niej ok. 7 minut.
- Potem pewnie kliknąłem w inną podpowiedź (bo w wyszukiwaniach mam pełną nazwę strony, co do litery).
- Trafiłem na stronę, której szukałem na początku.
Ogranicza mnie oczywiście to, że widzę tylko najnowsze odwiedziny na stronie. Ale mimo wszystko da się całkiem znośnie wykorzystać te dane.
Inna historia to wizyta w Hiszpanii w 2020 r. W pierwszych dniach, kiedy byliśmy na odludziu, zero aktywności. Potem wyszukiwanie i zwiedzanie lokalnych grup polskich. Interakcje z zewnętrznymi stronami biur podróży (których szukaliśmy na szybko).
Dane układają się w spójną historię, jeśli się je umieści w szerszym kontekście.
Ciemna strona danych
Takie przypominajki z danych dałoby się też wykorzystać w bardziej złowieszczy sposób.
Przyjmijmy, że jest pewien człowiek płci dowolnej. Nazwijmy go Anonek. Pewnego dnia ktoś napisał komentarz, który Anonka strasznie wkurzył. Na przykład szkalujący pizzę hawajską. Anonek z gniewu aż wszedł na profil tej osoby, planując zemstę.
Jednak być może nie udało mu się odegrać. Omyłkowo się wylogował, potem wyczyściło mu historię przeglądarki. Nie pamiętał już imienia osoby, na której chciał się zemścić. A profili przeglądał bardzo wiele, więc nawet gdyby pobrał dane, nie chciałoby mu się grzebać w samym visited.json w surowej formie.
W normalnych warunkach, nie mając punktu zaczepienia, może by odpuścił.
Ale, korzystając z naszej osi czasu, mógłby wyszukać inne zdarzenie, które miało miejsce w tamtym czasie. Może na przykład pamięta, że tamtego dnia szukał przez FB fanklubów hawajskiej?
Otwiera więc plik z osią czasu w Notatniku i wyszukuje „hawaj”, żeby znaleźć ten dzień. Patrzy na wydarzenia z tagiem ODWIEDZONA STRONA/PROFIL z tego samego dnia.
Znajduje jakiś profil. Nazwa użytkownika jest inna niż zapamiętał. Tamten szkalujący łotr zmienił nazwę konta, żeby przed nim uciec! Gdyby Anonek szukał tradycyjnymi metodami, to by go nie znalazł.
Oprócz nazwy użytkownika jest też pole uri. To link do konta na Facebooku. Wiele osób zmienia nazwę swojego konta, ale identyfikator często pozostawiają taki jak poprzednio.
Anonek kopiuje link do przeglądarki i wchodzi na profil wroga. Po miesiącach frustracji może się zemścić.
Porada
Co zrobić, jeśli na FB mignie Wam jakaś dawno niewidziana znajoma, której nazwisko nijak się Wam nie kojarzy (bo np. w międzyczasie wyszła za mąż)? Jak szybko ustalić tożsamość?
Możecie najechać kursorem na jej imię i spojrzeć w lewy dolny róg przeglądarki. Pojawi się tam link do profilu. Jeśli macie szczęście, to się nie zmienił od założenia konta i nadal zawiera nazwisko panieńskie.
Twoja oś czasu
Na koniec mój skrypt w Pythonie, efekt działań z tego wpisu:
- Najpierw pobieramy swoje dane z Facebooka.
- Uzyskany plik zip dajemy do jakiegoś folderu. Możemy go rozpakować, ale nie musimy.
- W tym samym folderze umieszczamy mój skrypt i go odpalamy.
- Jeśli wszystko dobrze poszło, powstanie plik tekstowy fb_moja_os_czasu.txt. Można go otworzyć np. w Notatniku. Zawiera listę różnych naszych działań ułożonych chronologicznie.
Oddaję skrypt w Twoje ręce, możesz używać i modyfikować do woli. Teraz Twoja oś czasu jest Twoja.
To tyle na dziś. W kolejnym wpisie mój „konik”, czyli analiza tekstu (wiadomości z Messengera). Będzie się działo! ![]()
Był to wpis z serii Kochajmy się jak bracia, analizujmy się jak Facebooki