
Internetowa inwigilacja 1 – podstawy
Nasze wizytówki, czyli nagłówki (HTTP)
Wpis z serii Internetowa inwigilacja
Zdarzyło Wam się podczas przeglądania internetu zderzyć się z blokadą? Albo odnieść wrażenie, że jakaś strona wie o Was więcej, niż byście chcieli?
Czasem stronki nie chcą nam czegoś pokazać. Albo jedna i ta sama reklama chodzi za nami po różnych, niezwiązanych ze sobą stronach. Albo wyświetla się (ale tylko na telefonie!) ponaglenie, żebyśmy zamiast stronki użyli aplikacji mobilnej.
Skąd oni to wszystko wiedzą?
Tej kwestii poświęcę serię wpisów Internetowa inwigilacja. Pokażę w nich różne metody, dzięki którym właściciele odwiedzanych stron mogą nas rozpoznawać i zbierać o nas informacje.
To pierwszy z tych wpisów. Wprowadzę tutaj analogię ułatwiającą zrozumienie komunikacji przez internet. I pokażę, ile informacji wysyłamy właścicielom stron przy pierwszym kontakcie – kiedy dopiero się „przedstawiamy” innemu komputerowi i jeszcze nawet nic nam nie odesłał.
Internet jako poczta
Zacznę od odrobiny słowotwórstwa. Inter oznacza między, a net oznacza sieć. Czyli: sieć komputerów komunikujących się między sobą.
Jaki jest inny, bardziej swojski przykład sieci komunikacyjnej? Poczta!
- Zarówno szarzy obywatele (klienci), jak i większe organizacje (serwery) mogą sobie wysyłać listy i paczki.
- …Przy czym zwykli ludzie częściej wysyłają lekkie listy z prośbami. A więksi gracze odpowiadają na ich prośby, odsyłając różne rzeczy w paczkach.
- Wszystko trzeba przesyłać przez placówki pocztowe. Zakładamy, że nie można tak po prostu podejść i przekazać bezpośrednio.
- Na kopertach/opakowaniach można umieszczać różnorodne informacje. Ale, żeby była możliwa dwustronna komunikacja, wśród tych informacji muszą być adresy odbiorcy i nadawcy (adresy IP).
- W odróżnieniu od prawdziwej poczty, biurokracja jest minimalna. Wszystko załatwiamy przez zaufaną panią z okienka (przeglądarkę), która już zna potrzebne informacje, sprawdzi adresy w katalogach itp. Wystarczy że powiemy, kogo i o co chcemy prosić.
Analogia nie jest w 100% moja, podpatrzyłem różne jej części w internecie. Na przykład motyw wysyłanych kopert pojawia się m.in. w tym filmiku.
 Uwaga
Uwaga
Pomijam w tej analogii sporo rzeczy, jak na przykład to że dane są wysyłane w częściach, czasem następuje ponowne wysłanie, adres IP ma inne miejsce w hierarchii niż reszta informacji itp.
Przyjmiemy dla uproszczenia, że jeden list/paczka = wszystkie rzeczy wysłane podczas jednej interakcji.
Informacje w nagłówkach
Załóżmy, że chcemy zrobić najprostszą rzecz jaką się da. „Wejść” na dowolną stronkę internetową. Na przykład na listę wpisów z ciemnastrona.com.pl. To tylko trzy proste kroki:
- Prosimy panią w okienku o stronę (wpisujemy jej adres w pasku przeglądarki);
- Nasza prośba zostaje wysłana, ktoś (serwer) ją odbiera;
- Odsyłają nam to, o co prosiliśmy (albo i nie)
Trzymając się analogii pocztowej: już nas znają na poczcie i wiedzą, że chcemy format taki a taki, mówimy po polsku itp. Więc kiedy mówimy w okienku, do kogo chcemy wysłać prośbę, po prostu biorą odpowiednią etykietę z tymi informacjami i naklejają ją na nasz list/paczkę. W świecie rzeczywistym taką etykietą z informacjami są nagłówki HTTP.
Przykładowy zestaw nagłówków w formie etykiety na paczce:
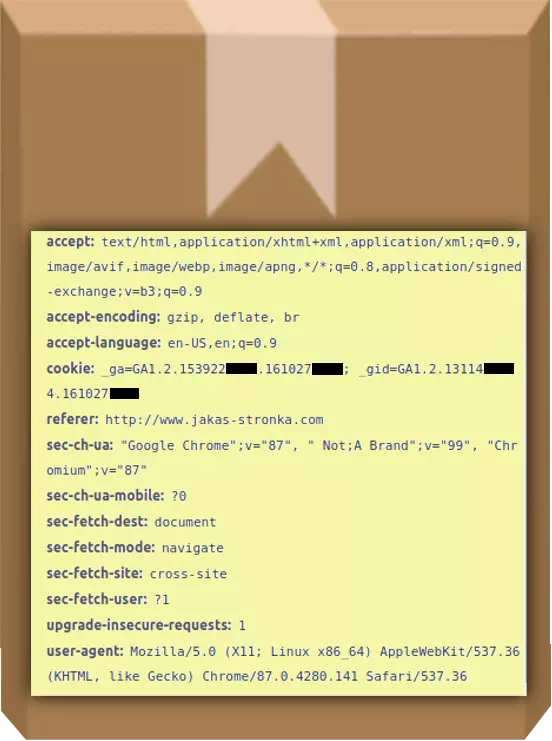
Oprócz nich na opakowaniu – ale w innym miejscu – znajduje się również nasz adres IP.
Po wysłaniu naszej przesyłki tracimy nad nią kontrolę. Nie wiemy, co się z nią dalej dzieje. Odbiera ją adresat albo jakiś jego pełnomocnik – w przypadku Ciemnej Strony serwer należący do amerykańskiej firmy, Githuba.
Nie wiemy, na które informacje z „etykiety” zwróci uwagę ani co z nimi zrobi. Może na ich podstawie na przykład:
-
Uszanować prośbę.
Czyli odesłać nam stronkę, o którą prosimy, uwzględniając informacje z etykiety; jeśli np. informacje mu wskażą, że korzystamy z urządzenia mobilnego, może nam od razu przesłać mniejszą wersję.
-
Zignorować prośbę.
Niektóre informacje z etykiety nie mają większego znaczenia albo trudno się do nich odnieść. Jeśli na etykiecie np. jest wskazane, że używamy języka polskiego, ale strona nie ma polskiej wersji, to tak czy siak dostaniemy wersję angielską.
-
Dyskryminować nas.
Co, jeśli na podstawie informacji serwer wywnioskuje że piszemy z Polski, a nie lubi Polaków? Może nam wtedy odesłać notkę „Nie mamy twojej strony, i co nam zrobisz?”. Albo inny, bardziej dyplomatyczny wariant tych słów. Najbardziej wkurzające w informacjach z nagłówków może być właśnie to, że często na ich podstawie blokuje się nam treść.
Jest jednak jeszcze jedna, może nawet gorsza możliwość. Niezależnie od działań widocznych na zewnątrz, serwer może:
-
Gromadzić i analizować informacje
Serwer zawsze może sobie zapisać komplet informacji o całej naszej interakcji: dokładny czas, nasz adres IP oraz wszystkie informacje z „etykiety”. Często je przechowuje w formie plików tekstowych, tak zwanych logów.
Do zapisanych informacji serwer może wrócić po dowolnym czasie, o ile nie zostaną do tego momentu usunięte. Co może z nimi zrobić?
Jeśli będzie je tylko liczył, to zakładam ostrożnie, że wiele nie zrobi. Zwłaszcza że informacje z nagłówków mogą się zmieniać albo nie być prawdziwe (sam Wam pokażę, jak je zmieniać ![]() ).
).
Poza tym takie informacje często się powtarzają. Prawie każdy smartfoniarz zostanie odnotowany jako Android + Chrome + popularny język, ewentualnie jako iOS + Safari.
Ale co, jeśli odwiedzamy jedną stronę przez dłuższy czas i ciągle używamy dość unikalnej kombinacji (np. ustawiony język suahili + system operacyjny Linux + jakaś niszowa przeglądarka)?
Wtedy ktoś analizujący logi może słusznie założyć, że jesteśmy jedną i tą samą osobą.
Potem, nawet jeśli nie znają naszej tożsamości, mogą ująć nas w statystykach jako pojedynczego bywalca. Trochę w stylu Spotify’a:

Źródło: Tribeca Citizen
A szczególnie sadystyczny administrator może zostawić serwerowi instrukcję w stylu „Jeśli fotkę tego kota po raz setny wyświetli ten świr z Linuxem + dziwną przeglądarką + ustawionym językiem suahili, to zacznij wyświetlać że kitka nie ma, bo zaoglądany na śmierć”.
Poza tymi wydumanymi przykładami zwykłe liczenie informacji z nagłówków nie jest dla nas groźne.
Jeśli natomiast serwer zacznie analizować zebrane informacje i łączyć je z innymi, to może zdziałać zadziwiająco wiele, w tym również rozpoznawać nas jako konkretną jednostkę i śledzić nasze działania.
Kolejne wpisy będą poświęcone tym możliwościom. Jest spora szansa, że będziecie równie zaskoczeni jak ja, kiedy po raz pierwszy się o tym dowiedziałem.
A tymczasem możemy się tutaj zatrzymać, jeśli chodzi o dawkę informacji. Więcej w kolejnych wpisach! ![]()
Jeśli natomiast chcecie zobaczyć, jak osobiście sprawdzać nagłówki, to zapraszam do krótkiego samouczka. Osoby na każdym poziomie dadzą radę – są tu dwa skróty klawiszowe, kilka kliknięć i brak ryzyka, że coś się popsuje.
Bonus: Jak sprawdzać nagłówki HTTP
Chcesz sprawdzić, co jest naklejone na Twoją przesyłkę?
Najprostsze rozwiązanie – możesz to zrobić na przykład przez stronkę Web Sniffer. Pod linijką Request Header zobaczysz, co wysłało Twoje urządzenie na jej serwer. To dobra opcja, jeśli korzystasz z urządzenia mobilnego.
Ciekawostka
Tę stronkę już podawałem jako przykład w pierwszym wpisie. Jest na niej jedna reklama Google’a, bo nie znalazłem niczego, co by pokazywało informacje z nagłówków HTTP i było wolne od reklam/analityki. Waga strony bez reklamy to ok. 4 kB. Waga strony po załadowaniu całej reklamy, to ok. 1,5 MB (ponad 375 razy więcej; głównie elementy śledzące) ![]()
Jeśli natomiast masz dostęp do komputera, to nie trzeba odwiedzać żadnej strony, wszystkie informacje masz na miejscu.
Pokażę to na przykładzie Firefoksa, ale narzędzia Chrome’a są bliźniaczo podobne.
Najpierw naciskamy Ctrl+Shift+I (jak „Irena”). Pojawi się okno ze szczegółowymi informacjami – w Firefoksie na dole, w Chromie po prawej stronie ekranu.
Okno na dole jest moim zdaniem mało wygodne. W obu przeglądarkach możemy zmienić układ, klikając w opcje w prawym górnym rogu i wybierając np. Wyświetlaj z prawej:
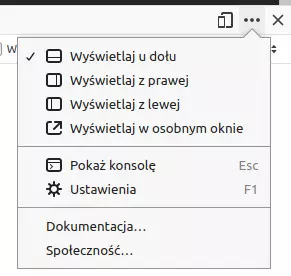
Klikamy zakładkę Sieć w górnym pasku:

Naciskamy F5, żeby odświeżyć stronę. Okno zapełni się listą rzeczy, o które poprosiła nasza przeglądarka. Klikamy dowolną z nich, na przykład pierwszą od góry:
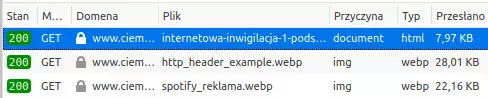
Pojawi się okno ze szczegółowymi informacjami. Klikamy w nim zakładkę Nagłówki:

Pod spodem wyświetlą się dwie listy – najpierw lista nagłówków, jakie dostaliśmy od serwera (Nagłówki odpowiedzi), a pod spodem nagłówki wysłane przez nas, nasza „etykieta” (Nagłówki żądania). To o tym mówiłem przez cały wpis.
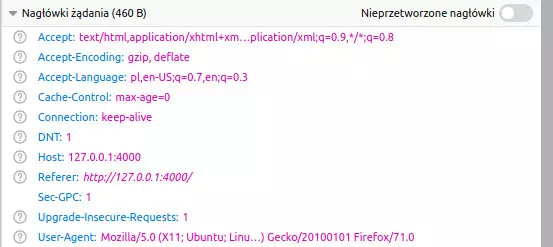
Ciekawostka
Jeśli spojrzysz na kolumnę 2 głównej listy (Domena), to zobaczysz że większość rzeczy pochodzi z ciemnastrona.com.pl. Część jednak przybyła z domeny github.githubassets.com.
To strona zewnętrzna i to nie ją odwiedzasz. Mimo to, jeśli spojrzysz na nagłówki, zobaczysz że dostała prawie wszystko to, co nasza Ciemna Strona.
Tak niestety jest – odwiedzane przez nas strony to często straszni plotkarze i od razu przekazują innym informacje o odwiedzających. Nigdy nie zakładajmy, że wysłanie czegoś pozostanie prywatną sprawą między nami a stroną.
W tym przypadku odnośniki na szczęście nie zdradzają tajemnic. To taka wygodna opcja korzystania z ikonek emoji od Githuba. Który zapewnia hosting Ciemnej Stronie, więc tak czy siak widziałby wszystkie etykiety.
A do plotkarskich stron jeszcze wrócimy. Trzymajcie się i do zobaczenia! ![]()
Był to wpis z serii Internetowa inwigilacja