
Internetowa inwigilacja 3 – przekierowania
„Do kogo idziesz?”
Wpis z serii Internetowa inwigilacja
W poprzednich częściach „Internetowej inwigilacji” porównałem informacje, jakie wysyłamy innym stronom internetowym, do etykiet naklejanych na paczki i listy.
Przyjrzeliśmy się również refererowi, jednej z tych informacji – zdradzającej stronie B, że przybywamy na nią po kliknięciu w link na stronie A.
W tym odcinku nadal trzymamy się tematu linków. Tym razem nie omówię kolejnych rodzajów informacji, jakie mogą się znaleźć na naszej etykiecie, tylko sztuczkę, dzięki której istniejące informacje mogą trafić do innej strony.
To trochę jak odwrócony referer – on mówił, skąd przychodzimy. Zaś dzięki podmianie linków i przekierowaniom strona A może się dowiedzieć, że odchodzimy z niej na stronę B.
Gwiazdą wieczoru będzie Twitter, który takie coś uskutecznia.
 Podstawy
Podstawy
Ogólnie wpis nie wymaga żadnej wiedzy o Twitterze.
Wystarczy wiedzieć, że to amerykański portal społecznościowy. Można na nim tworzyć krótkie, widoczne dla każdego wpisy zwane tweetami (liczące na dzień dzisiejszy maksymalnie 280 znaków). Tweety mogą zawierać linki, obrazki i inne dodatki.
Wprowadzenie
Wyobraźmy sobie, że jest stronka, na którą użytkownicy sami mogą wrzucać treść, w tym linki (podobieństwo do Twittera przypadkowe i niezamierzone!).
A właściciele strony chcą ich jak najdokładniej inwigilować. W jaki sposób mogą to robić?
W przypadku dodawanych treści to łatwe. W końcu mają władzę nad serwerami. Jeśli jakiś użytkownik chce coś dodać, musi to najpierw wysłać na serwer.
A wtedy właściciele zapisują: „Użytkownik nr 05467 dnia tego a tego dodał wpis z linkiem do www.ciemnastrona.com.pl”.
Ale monitorowanie, kto potem w te linki kliknie? To już trudniejsza sprawa.
Typowe linki
Przeglądarki mają własną metodę postępowania z linkami. Nawet jeśli jesteśmy na stronie A, to po kliknięciu w link do strony B przeglądarka po prostu opuszcza A i wysyła B informację, że chce ją odwiedzić.

Mem nie jest w 100% trafny – strona A tak łatwo się nie dowie, że przeglądarka przechodzi na B.
Strona A nie może zmienić działania przeglądarki. Ale może stosować sztuczki, żeby mimo to ustalić, w co klikają jej użytkownicy.
Spójrzmy najpierw na schemat. Gdyby Twitter zachowywał się jak typowe strony, to interakcje z linkami wyglądałyby w taki sposób:
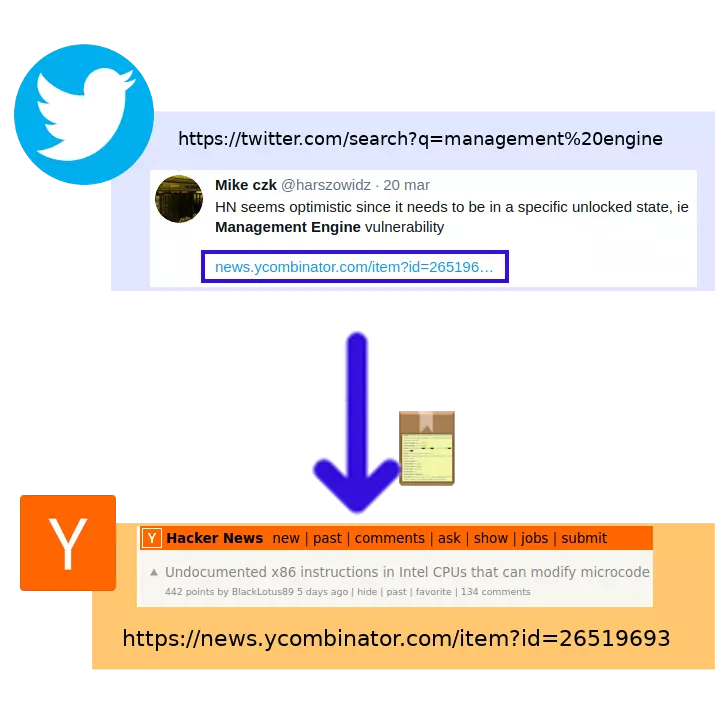
Treść tweeta to lekki spoiler odnośnie jednego z najbliższych wpisów.
- Klikamy link do strony B (tu: forum Hacker News) umieszczony w czyimś tweecie.
-
Nasza przeglądarka opuszcza Twittera i wysyła stronie B prośbę o przesłanie treści.
Przy okazji wysyłamy stronie B nagłówki HTTP (naszą „etykietę”) z pewnymi informacjami o sobie – no ale tak już jest w tym internecie.
- Przeglądarka otrzymuje i wyświetla stronę B.
W każdym razie – normalnie Twitter by nie wiedział o tym, że przeszliśmy na inną stronę.
Śledzące linki Twittera
Ale rzeczywistość jest inna, a ptaszysko jest wścibskie. Gdyby strony zawierały tylko tradycyjne linki, to by nie wiedziały, czy i kiedy w nie klikamy. Dlatego je podmieniają.
Metodą, która umożliwia łatwą podmiankę jest przekierowanie. To instrukcja dla przeglądarki, że ma teraz przejść na inną stronkę. Taki odpowiednik spławienia kontrolera zza płota. „A niee, z tym to idź pan do sąsiada”.
Chytra sztuczka Twittera zaczyna się już na etapie, kiedy ktoś dodaje nową treść:
- Ktoś pisze na Twitterze (stronie A) nowego tweeta, zawierającego link do strony B.
-
Twitter wykrywa link. Tworzy dla niego mini-stronkę C pod adresem t.co, której jedyną zawartością jest przekierowanie do strony B. Podmienia pierwotny link tak, żeby do niej prowadził.
Nie ma tu najmniejszego znaczenia, że tekst linku wygląda nadal, jakby prowadził pod news.ycombinator… Tak naprawdę to t.co…, własność Twittera.
Tekst linku i strona, do której prowadzi to kompletnie odrębne sprawy. Zresztą sam na blogu często ukrywam linki pod zwykłymi słowami.
Dzięki temu, że Twitter podmienił źródło linku na samym początku, będzie on zawsze prowadził na ich podstawioną stronkę. Nawet gdyby ktoś udostępnił tweeta poza Twitterem.
Etap drugi, czyli interakcja z podmienionym linkiem, wygląda tak:
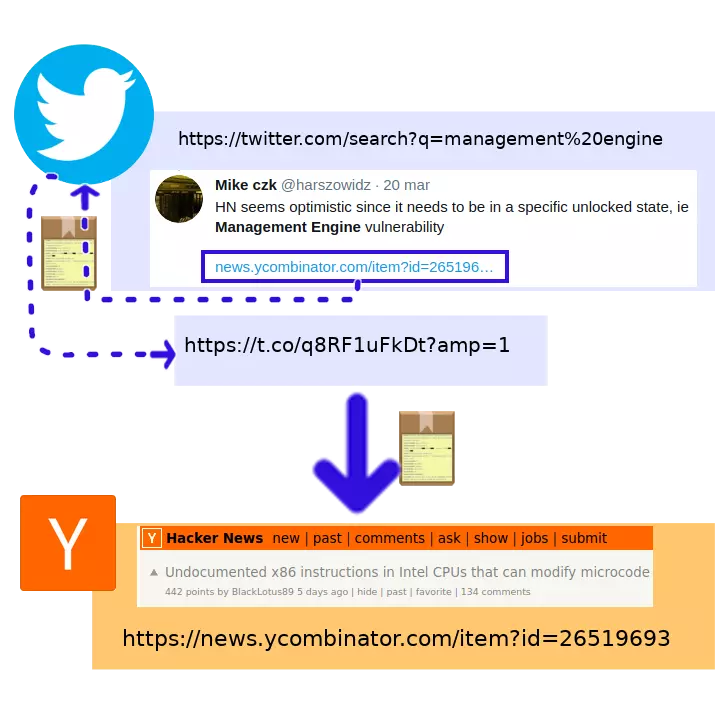
-
Ktoś klika w link z tweeta.
Chce wejść na stronę B, ale nie wie, że link prowadzi do mini-stronki C.
- Prosząc o stronę spod tego adresu, nasza przeglądarka wysyła do t.co (Twittera) pełen zestaw informacji z nagłówków.
- W zamian otrzymuje mini-stronkę C.
- …Ale nie ma na niej nic poza przekierowaniem do strony B. Zatem przeglądarka ponownie wysyła komplet nagłówków, ale tym razem do strony B.
- Przeglądarka otrzymuje i wyświetla stronę B.
Zatem nadal wysłaliśmy naszą „etykietę” stronie B i na nią przeszliśmy. Różnica jest taka, że te same informacje zna teraz również Twitter.
Ciemna strona przekierowań
Na Twitterze sami się nie kryją z podmienianiem linków, nazywając to swoją usługą:
Our link service measures information such as how many times a link has been clicked
(…)
A link converted by Twitter’s link service is checked against a list of potentially dangerous sites.
(…)
You cannot opt out of link shortening.
Źródło: informacje z Twittera o ich przycinaczu linków.
Wiecie, czemu zaznaczyłem “such as”? Bo taki zwrot sugeruje, że to tylko przykład. A analizować mogą zapewne, co im się żywnie podoba.
Sprawa z ochroną przed innymi stronami też jest trochę szemrana. Wyobraźmy sobie – tak czysto teoretycznie – że Twitter wpada kiedyś w ręce jakiegoś dyktatora (z dowolnej strony spektrum politycznego).
Dyktator wiedziałby dokładnie, które linki prowadzą na które strony. A mając kontrolę nad przekierowaniami, mógłby jednym pstryczkiem wyłączyć wszystkie linki z Twittera prowadzące do stron, które go krytykują. Takich jak np. krytyka-dyktatora.com.
Wystarczyłoby podmienić odpowiednie mini-stronki z serii t.co. Żeby zamiast przekierowania zawierały np. materiały propagandowe.
Użytkownicy nieobeznani z takimi trikami mogliby wtedy pomyśleć, że to ze stronką krytyka-dyktatora jest coś nie tak – w końcu linki do tej strony na Twitterze miały jej normalną nazwę. Kliknęli, a tu informacja o zagrożeniu wyskakuje!
Mogłoby im nie przyjść do głowy, że to władca Twittera stosuje cenzurę. Jeden pstryczek, jedna strona odcięta. Nic nie wymknie się poza Twittera bez jego wiedzy. Uroki scentralizowanej władzy.
Aktualizacja 2023: po dwóch i pół roku od napisania posta Twitter zmienił właściciela oraz nazwę (na X).
Do tego zyskaliśmy realny przykład nadużycia skracarki. Jak podaje Washington Post, otwieranie linków do niektórych stron było celowo spowalniane. Gdyby użytkownicy je sobie skopiowali, zamiast klikać i zdawać się na przekierowanie, to dużo szybciej by się ładowały.

Źródło obrazka: Reddit. Przeróbka moja.
Ciekawostka
W USA skierowali nawet pozew zbiorowy przeciw Twitterowi, argumentując że wysyłanie po kryjomu danych o klikniętych linkach narusza kalifornijskie przepisy o ochronie prywatności (odpowiednik polskiego RODO).
Wziąłem Twittera za przykład, ale oczywiście nie jest jedyną stroną, która działa w taki sposób. Różne przycinacze linków wprost oferują możliwości analizowania ruchu każdemu, kto by tylko chciał sobie popatrzeć:
[Bitly] collects over 20 data points with every click, from geographic data down to the local city level to referral channels to device type.
(…)
Droplr is also the only URL shortener to track every link forever.
(…)
free URL shortener, tiny.cc, also provides basic free link tracking.
Źródło: droplr.com
Możemy monitorować swoje linki za darmo, na zawsze, do tego zbierać szeroki zakres danych. Cudownie ![]()
Analitycy mają prawdziwy arsenał. Ale my również nie jesteśmy bezradni, jeśli nie chcemy zdradzać informacji podczas klikania w zamaskowane linki. Zaprezentuję teraz nasze możliwości.
Jak to przechytrzyć?
Przede wszystkim patrzmy czasem, w co klikamy. Nawet jeśli tekst linku mówi dobrastronka.cool, to pod tekstem może się kryć link do niedobrastronka.fuj.
Najprostszą metodą, żeby to sprawdzić, jest najechanie kursorem na link i spojrzenie w lewy dolny róg przeglądarki. Wyświetli się tam, dokąd on naprawdę prowadzi.
(W przypadku urządzeń mobilnych przytrzymujemy palec na linku. Ostrożnie, żeby nie kliknąć!).
Kiedy już wiemy, czy mamy do czynienia z podmienionym linkiem, możemy go przechytrzyć.
Kopiowanie tekstu
Jeśli widzimy pełen adres strony w formie tekstu, ale ukryty pod nim link prowadzi w inne miejsce, to możemy, zamiast klikać link, po prostu skopiować tekst i wkleić go w pasek przeglądarki. W ten sposób przejdziemy prosto na tę stronkę, na którą chcieliśmy. Bez pośredników.
(Jeśli uważnie czytaliście wpis o refererze, to być może zauważyliście, że tam też wklejenie linka w pasek ucinało część informacji. Taka uniwersalna metoda).
Porada
Czasami widoczny adres strony jest przycięty, ale pokazuje się w całości po najechaniu kursorem. Tak jest w przypadku tego linka z Twittera (obrazek poniżej; widać, że po najechaniu pokazują się obie brakujące cyfry).
Jeśli boimy się techniki, to możemy skopiować do paska przeglądarki tę część, którą się da, a resztę wyświetlić i dopisać ręcznie.
Ale lepiej kliknąć link prawym przyciskiem, wybrać Zbadaj element i skopiować potrzebny tekst prosto z kodu strony (w razie potrzeby klikając w strzałki, żeby rozwinąć elementy).

No, ale czasem szczęście nam nie sprzyja. Widzimy tylko skrócony link, bez żadnej wskazówki dokąd prowadzi. Albo używamy urządzenia mobilnego i ciężko zajrzeć w kod strony.
Jeśli nie klikniemy w skrócony link, to się nie dowiemy, co się za nim kryje.
Ale jeśli klikniemy, to stronka A się dowie, że to zrobiliśmy.
I tak źle, i tak niedobrze. Czy jest jakieś rozwiązanie?
GetLinkInfo
Otóż jest – ale wymaga odrobiny spychologii. Jeśli ktoś musi w ten link wejść, to niech to będzie ktoś inny. Na przykład strona GetLinkInfo.com.
Najpierw klikamy prawym przyciskiem na link (na mobilnym: przytrzymujemy palec) i wybieramy Kopiuj adres odnośnika. W ten sposób skopiujemy do schowka ten skrócony adres, t.co… w przypadku Twittera.
Potem odwiedzamy getlinkinfo.com, wklejamy adres w puste pole i klikamy przycisk Get Link Info. Ich serwery wezmą na klatę podrobiony link, odwiedzą go i pokażą nam, dokąd prowadził (zaznaczyłem na czerwono):
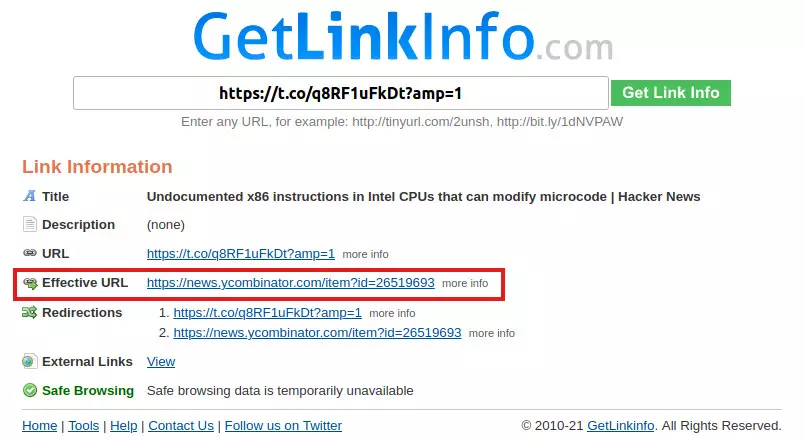
Teraz wystarczy tylko w niego kliknąć… Albo go skopiować i wkleić w pasek przeglądarki (żeby nie wysyłać w refererze informacji, że przybywamy z getlinkinfo.com ![]() ).
).
Metoda jest uniwersalna i powinna skutecznie działać, kiedy musimy wejść w nieznane, skrócone linki. Warto dodać GetLinkInfo gdzieś do zakładek.
Alternatywne strony
W internecie znajdziemy stronki działające jak pośrednicy – pobierają zawartość większych portali, a następnie nam ją wyświetlają. Czasem dodają przy tym pewne udogodnienia.
W tym wpisie było sporo o Twitterze, więc wspomnę o alternatywie dla niego. Nazywa się Nitter – to nie tyle strona, co cały zestaw narzędzi pozwalających powielać u siebie Twittera. Najbardziej znaną opartą na nim stroną (instancją) jest nitter.net.
Kiedy z niego korzystamy, wszystkie linki przekierowujące t.co są zamienione na linki do oryginalnych źródeł.
Uwaga
Nie zawsze rozwiązuje to całkiem sprawę przekierowań. Czasami ludzie korzystają najpierw z własnej skracarki, zmieniając na przykład link stronka.pl na bit.ly/1234. A po wrzuceniu na Twittera ten link zmieni się w jakieś t.co/6789.
Nitter rozwinie nam skrócenie od Twittera, ale z tym pierwotnym musimy poradzić sobie sami.
Niestety stronki takie jak Nitter są zapewne solą w oku większych portali. Ostatnio stronka nitter.net wydaje się coraz częściej blokowana i nie pokazuje niektórych twittów. Sprawniej działa mi nitter.cz. A obszerną listę innych alternatyw znajdziemy tutaj.
Dodatek Universal Bypass
(Dodano 8.04.2021 r.)
To może być najprzyjaźniejsze rozwiązanie do obchodzenia popularnych przekierowań (t.co, bit.ly…), ponieważ nie wymaga każdorazowego odwiedzania GetLinkInfo. Wszystko dzieje się w tle.
Firefox:
Możecie zainstalować go bez problemu z oficjalnego archiwum dodatków.Chrome:
Bypassa nie ma w uniwersalnym archiwum Chrome'a. Więcej informacji w ramce poniżej. Jeśli Was to nie zraża, to twórcy opisują na stronce, w jaki sposób zainstalować Bypassa ręcznie.(Ale i tak nalepiej zmienić Chrome'a; robienie z niego przeglądarki chroniącej prywatność to jak robienie wyścigówki z malucha).
Inne przeglądarki na PC:
Dostępna jest wersja na Edge'a.Poza tym wszystkie przeglądarki oparte na Chromium (Brave, Vivaldi, Opera…) powinny dać radę. Może jednak być konieczna ręczna instalacja dodatku.
Na Androida:
Wspiera go podobno Kiwi Browser (nie testowałem). Inne przeglądarki niestety kuleją ze wspieraniem dodatków.
Niedobry Google
Dlaczego wspomnianego dodatku Universal Bypass nie ma na Chromie? Okazuje się, że to Google go usunął odgórną decyzją. Jako wyjaśnienie podają, że może służyć do omijania płatności na stronach.
Tylko że ciężko spotkać się z takim zastosowaniem przekierowań, dużo częściej są używane do śledzenia. Brzmi to jak wymówka. No ale takie uroki monopolu…
Google took it down for apparently 'circumventing paywalls.' I have clarified that Universal Bypass is more of an adblocker and asked for details of where paywalls are circumvented, but it's Google, so of course I didn't get a response.
Źródło: strona Universal Bypass
Widać zatem, że nie jesteśmy bezbronni w walce z przekierowaniami. Jest od tego dodatek. Jeśli nie chcemy dodatku (albo przeglądarka go blokuje), to stronka GetLinkInfo. Jeśli jesteśmy tradycjonalistami i da się skopiować adres, to wklejanie w pasek.
Ale póki co życzę nam, żeby te myki nie były potrzebne, a wszystkie linki – jak drogi do Rzymu – od razu prowadziły tam, dokąd powinny.
Do zobaczenia w kolejnym wpisie!
Był to wpis z serii Internetowa inwigilacja