
Internetowa inwigilacja 4 – parametry w linkach
„Chcesz coś dodać?”
Wpis z serii Internetowa inwigilacja
W pierwszym wpisie z tej serii pokazałem po raz pierwszy nagłówki HTTP – informacje, jakie nasza przeglądarka wysyła stronom internetowym, kiedy surfujemy po sieci.
Porównałem je do etykiety naklejanej na poczcie na listy i paczki.
Drugi wpis skupił się na jednej z tych informacji, refererze – mówiącym stronie B, na którą przechodzimy, że kliknęliśmy link do niej na stronie A.
Poprzedni wpis omówił metodę stosowaną m.in. przez Twittera i polegającą na podmianie linków na przekierowania. Zamiast bezpośredniego przejścia z A do B musieliśmy iść przez stronę pośrednią C, przy okazji pokazując jej naszą etykietę z danymi.
Temat tego wpisu jest trzecim z kolei związanym z linkami. Ale na szczęście ostatnim, jeśli już zaczęły Was nudzić!
Pokażę tutaj parametry – informacje opcjonalne, jakie strony mogą dyskretnie dodawać do linków. Oczywiście również w celu śledzenia.
Parametry w praktyce
Oto link do strony, na której teraz jesteś:
Przyjrzyj mu się. Potem kliknij tutaj, żeby załadować stronę ponownie. Co się zmieniło?
Spostrzegawcze oko zauważy, że to cały czas ten sam link, tylko że na końcu dodało tekst ?strona=ciemna_strona&seria=internetowa_inwigilacja.
Wszystko po znaku zapytania to właśnie parametry, czyli elementy opcjonalne dodawane do linków.
Parametry mają prostą budowę:
- Są dodawane do linku po znaku zapytania;
- Mają format par
nazwa=wartość; - Pary są od siebie oddzielone znakami
&.
Zatem w przypadku tego linku wyżej mamy dwa parametry:
- o nazwie
stronai wartościciemna_strona; - o nazwie
seriai wartościinternetowa_inwigilacja.
 Porada
Porada
Nie ma co psuć sobie wzroku, przeglądając parametry gołym okiem. Można je łatwo wyświetlić w narzędziach przeglądarki.
Naciskamy Ctrl+Shift+I, wybieramy zakładkę Sieć u góry. Odświeżamy stronę. Po załadowaniu listy elementów klikamy na dowolny z nich. Na dole, w zakładce Parametry, zobaczymy parametry w czytelnej formie:
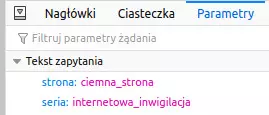
Parametry z założenia są elementami opcjonalnymi. Czyli: grzeczne serwery nie powinny się obrażać, jeśli za znakiem zapytania znajdą jakieś bzdury. Powinny to zignorować.
(Mój wewnętrzny troll już widzi potencjał na wpychanie tam spamu ![]() ).
).
Śledzenie przez parametry
No i OK, te parametry to ciekawy detal. Ale wiemy, o czym jest ten blog, prawda? Więc teraz czas na ich ciemną stronę.
Przede wszystkim umożliwiają bardzo dokładne śledzenie.
Znacie może popularny szpiegowski trik polegający na tym, że każdemu z potencjalnych zdrajców podrzuca się inne informacje? Kiedy te potem wyciekną, to będzie wiadomo, która z podejrzanych osób się wygadała.
Podobnie jest z parametrami. Jeśli strona jakimiś metodami zidentyfikuje użytkownika (na przykład przez JavaScript, który omówię za kilka wpisów), to może stworzyć link specjalnie dla niego, z unikalnym identyfikatorem wepchniętym w parametry.
Kiedy ofiara go kliknie, to trafi na tę samą stronę, na którą by trafiła, gdyby link nie zawierał parametrów. Niczego nie zauważy.
Ale w momencie połączenia serwer dostanie komplet informacji, w tym parametry. Wie, czego w nich wypatrywać. Znajdzie tam informacje, że to konkretna osoba przyszła w odwiedziny…
Nie trzeba zresztą aż tak dokładnej identyfikacji. Czasem wystarczy podrzucić na różne strony albo wysłać w różnych mailach te same linki, różniące się jedynie parametrami.
Kiedy użytkownicy będą w nie klikali, to po parametrach poznamy, z jakich źródeł do nas przychodzą (nawet jeśli będą ukrywali referery!). A jeśli ich dane z „etykiety” są dość unikalne, to można ich nawet rozpoznać.
Spójrzmy, kto w praktyce używa parametrów. Pewnie nie zdziwi nas widok samych znanych graczy:
- uniwersalne parametry śledzące UTM, wspierane m.in. przez Google Analytics, zaczynają się często od utm (
utm_source,utm_medium…); - te stricte od stron Google’a zaczynają się m.in. od
gclid; -
Facebooka – od
fbclid;Zresztą Facebook niczego się nie wstydzi i sam o tych parametrach wspomina w swoich materiałach dla firm.
- Instagrama – od
igshid. -
Amazona…
Ci to dorzucają całe mnóstwo, w tym wyszukiwane słowa kluczowe, dział strony, identyfikator:
?s=amazonbasics&srs=10112675011&ie=UTF8&qid=1489067885&sr=8-1&keywords=usb-c
Dzięki parametrom wszystkie te organizacje mogą łatwo monitorować, w jaki sposób przemieszczamy się po ich stronach. I mówić stronom zewnętrznym, że to od nich przychodzimy.
Ciekawostka
Gdyby interesowało Was więcej parametrów śledzących różnych stron, to tu znajduje się ogromna lista.
Ogólny format to nazwa kategorii/organizacji (np. “google”), pod nią “rules”. A wszystko co pod rules to lista parametrów na danej stronie (nie zawsze są czytelne, bo czasem to ogólne regułki oznaczające np. dowolną cyfrę).
Przypadek Facebooka
Spójrzmy dokładniej na jeszcze jeden przykład z Facebooka. Wspominałem w pewnym wpisie, w jaki sposób można tam pobierać i przeglądać swoje dane.
Tak to wygląda, kiedy wejdziemy w tryb przeglądania i chcemy wejść w całą listę swoich aktywności:
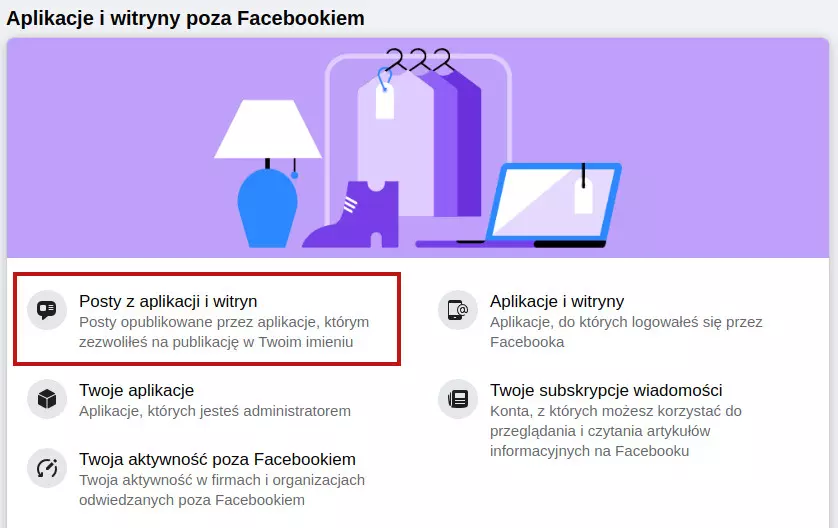
Pod zaznaczonym polem ukrywa się link:
Link prowadzi do podstrony allactivity. Zawiera trzy parametry:
-
category_keyo wartościallapps; -
privacy_sourceo wartościaccess_hub; -
entry_pointo wartościayi_hub.
Domyślam się, że skrót ayi rozwija się w Access Your Information, czyli nazwę zakładki z informacjami.
Mogę tylko zgadywać, co serwery Facebooka robią z tymi parametrami. W niewinnym przypadku po prostu jakoś sobie optymalizuje stronkę, żeby np. nie ładować czegoś niepotrzebnego.
Ale gdyby chciał, to mógłby też łatwo sobie notować, kto korzystał z dobrodziejstw RODO i interesował się swoimi informacjami. Albo liczyć, jaki ogólnie jest w narodzie trend ku sprawdzaniu swojej prywatności.
Brzmi jak teoria spiskowa? Może, ale kiedyś Facebook już kusił ludzi darmową apką, która potem wysyłała mu listę innych zainstalowanych aplikacji. Dzięki temu wykrywał na bieżąco, czy wyrasta mu konkurencja. I wykupił WhatsAppa, nim ten urósł w siłę.
Ciekawostka
Już od jakiegoś czasu ich nie widziałem, ale kiedyś Facebook potrafił dodawać do różnych nowinek na tablicy parametr cft[0], którego wartością był dłuuuuugi ciąg znaków. Inny dla każdego posta, ale taki sam dla wszystkich linków z tego posta (czyli np. obrazka, linku do profilu autora, linku z treści…).
Jakiś unikalny identyfikator?
Chcąc poszukać, o co chodzi z tymi parametrami, wpisałem w wyszukiwarkę cft[0] in facebook. Okazało się, że ktoś już o to zapytał, ale nie dostał żadnej odpowiedzi.
Dowiedziałem się jedynie, że według autora to __cft[0]__ to coś względnie nowego, z maja 2020 r.
Parametry + przekierowania
Nawiążę teraz do poprzedniego wpisu, o podmianie linków i przekierowaniach. Twitter dla każdego linku tworzył osobną mini-stronkę. Jak się okazuje, nie trzeba być tak rozrzutnym.
Dzięki parametrom można naszykować jedną i tę samą stronę dla wszystkich przekierowań. A adresy stron, do których mają zostać przekierowani ludzie, upychać w parametrach.
Tutaj przykład z chatu platformy Steam znaleziony na stronie dodatku Link Cleaner:
Link prowadzi do podstrony linkfilter w domenie steamcommunity.com.
Ma jeden parametr: url, o wartości https://getfedora.org/. To link docelowy.
Steam oczekuje, że będzie tak:
- Klikniemy w ten ich podmieniony link;
-
Przeniesie nas do strony linkfilter.
Oprócz parametrów serwer dostanie teraz naszą etykietę z informacjami (w tym zapewne m.in. pliki cookies Steama, identyfikujące nasze konto). Będzie wiedział, że ta konkretna osoba kliknęła w ten konkretny link.
- Serwer przeanalizuje parametr url.
-
Przekieruje nas do strony z tego parametru.
Albo i nie. Jeśli strona mu się nie spodoba, to może nas nie przepuścić; poza tym mógłby zapisać sobie w bazie, że ten konkretny użytkownik klika w nieodpowiednie linki.
A jak będzie, jeśli dysponujemy odpowiednim dodatkiem do przeglądarki? Wtedy wszystko odbędzie się w nieco inny sposób, przyjaźniejszy dla nas.
Jeśli przechytrzymy Steama:
- Klikamy w ten podmieniony link.
-
Włącza się dodatek i znajduje w linku parametr z nazwą innej strony.
(Może już mieć zapisane w kodzie, żeby przy linkach ze steamcommunity.com patrzeć na parametr url; może też przeszukiwać parametry wszystkich linków)
-
Każe przeglądarce iść prosto do tej strony.
W ten sposób Steam się nie dowiaduje, że kliknęliśmy w link. A jeśli go blokował, to nie ma to znaczenia – bo idziemy bezpośrednio do celu, a nie przez Steamowe przekierowanie.
(W ostateczności moglibyśmy nawet wykonać to ręcznie, zaznaczając link ukryty w parametrach i kopiując go do paska przeglądarki).
Podsumowanie linków
Możemy zauważyć, że wszystkie trzy sprawy związane z linkami (referer, przekierowania, parametry) nieco się ze sobą łączą:
- jeśli kliknięty link robi nam przekierowanie, to wysyłamy swoje informacje stronkom, którym może nie chcieliśmy;
- wśród tych informacji jest referer, który zdradza gdzie byliśmy.
- w dodatku zarówno w refererze, jak i w klikniętym linku mogą być parametry, które mówią o nas jeszcze więcej.
Myślę, że ta porcja informacji wystarczająco obniżyła naszą ufność do parametrów.
W poprzednich wpisach mówiłem, że referera można zwykle usuwać bez obaw, a przekierowania da się obejść. A co zrobić z parametrami?
A może by tak usuwać?
Skoro łatwo je rozpoznać, bo zawsze zaczynają się po znaku zapytania… to włączmy gdzieś regułkę ucinającą wszystko po takim znaku. I po problemie!
…Tylko że niestety nie. W przeciwieństwie do referera, parametry są bardzo aktywnie używane. Jeśli je zablokujemy, spory kawałek internetu przestanie nam działać tak jak powinien.
Najpierw przykład z YouTube’a. Kiedy udostępniamy komuś link do filmu – klikając przycisk Udostępnij, a nie po prostu kopiując adres obecnej strony – to możemy wskazać konkretny moment, od którego zacznie się film.
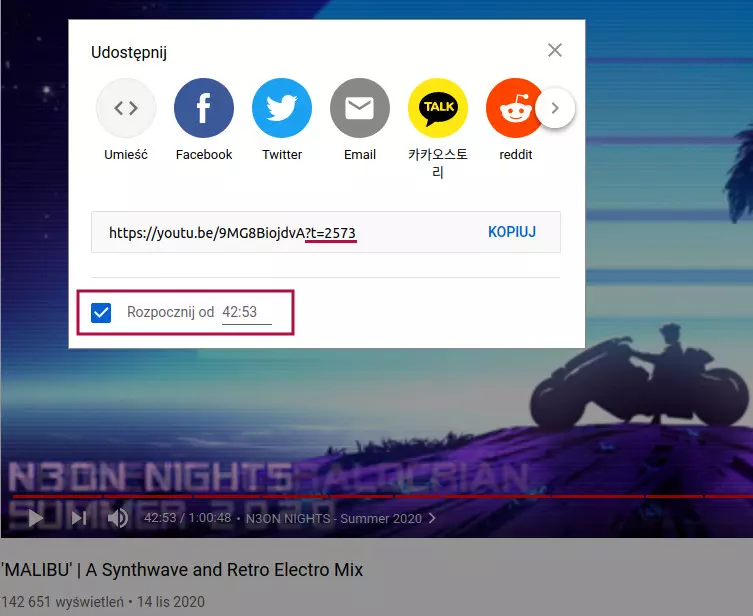
Wtedy do linku zostanie dodany parametr t. Jego wartość to liczba sekund od rozpoczęcia filmu.
Gdybyśmy ucinali wszystkie parametry i przesłali link bez nich, to strona nadal będzie działała, ale film będzie nam się wyświetlał zawsze od początku, a nie od wskazanego miejsca.
Innym razem parametry są wręcz niezbędne i strona bez nich nie działa. Przykładem Hacker News, bodaj moje ulubione anglojęzyczne forum dyskusyjne. Link do jednej z dyskusji kończy się parametrem id=26274035.
Jeśli usuniemy z linku parametry, czyli wszystko po znaku zapytania, to zostaniemy praktycznie z niczym. A po wejściu w taki link wyświetli nam błąd:
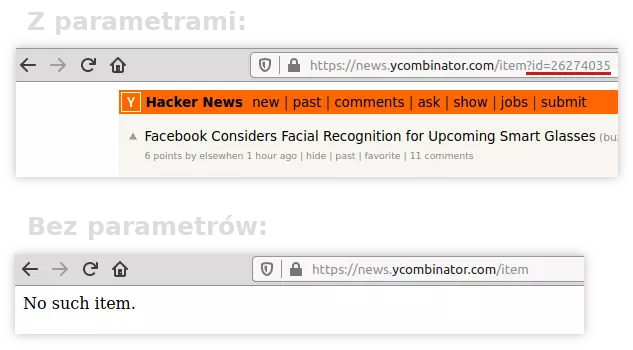
Jak widać, bez parametru id z określoną wartością nie dostaniemy tego, na co liczyliśmy. Gdybyśmy automatycznie usuwali wszystkie parametry, to strona by w ogóle nie działała.
A Hacker News nie jest tutaj wyjątkiem. Jest wiele innych stron, dla których parametry mają znaczenie. Formularze, zakupy online… do wyboru, do koloru.
W związku z tym parametry są integralną częścią internetu i opcja nuklearna raczej nie zadziała. Każdy przypadek jest inny.
Pewnym rozwiązaniem jest tworzenie i aktualizowanie na bieżąco list z nazwami parametrów, które służą tylko do śledzenia. Żeby je potem usuwać bez obaw. Takie listy prowadzą m.in. twórcy dodatków do przeglądarek.
Dodatki do przeglądarek
Dodatków jest na szczęście sporo. Wystarczy wejść na stronę odpowiednią dla swojej przeglądarki i je sobie zainstalować.
Wśród dostępnych opcji wyróżniają się dwa dodatki – ClearURLs i NeatURL
Pod względem ocen i opinii na forach idą praktycznie łeb w łeb. Oba sprawnie usuwają znane parametry śledzące.
Różnice między nimi? ClearURLs jest częściej aktualizowany, ale listy parametrów do usunięcia zapewnia społeczność.
Z kolei NeatURL jest mniej aktywny, ale pozwala dodawać własne reguły usuwające. Więc może nam wiernie służyć, nawet gdyby społeczność straciła zainteresowanie.
Sam jako zwolennik odrobiny majsterkowania wybrałem Neat URL.
Oczywiście możecie sprawdzić oba i wybrać ten, który się spodoba (rym ![]() ).
).
Firefox:
Oba dodatki dostępne w oficjalnym archiwum.NeatURL tutaj, zaś ClearURLs tutaj.
Chrome:
Również znajdziemy oba dodatki w oficjalnym archiwum Chrome'a(chociaż Google trochę rzucał im kłody pod nogi, szczegóły poniżej).
Tutaj Neat URL, zaś tutaj Clear URLs.
Inne przeglądarki na PC:
Nie testowałem innych przeglądarek, ale zwykle to co działa na Chromie działa też na przeglądarkach na tym samym silniku (Edge, Brave, Vivaldi, Opera).
Niedobry Google
Niedawno miała miejsce aferka z udziałem ClearURLs i Google’a.
Dodatek został usunięty przez Google z Chrome Web Store’a (ich archiwum dodatków do przeglądarki) z dość naciąganych przyczyn. Po burzliwej dyskusji i odwołaniu się przez autora został przywrócony.
Tym niemniej cała sytuacja pokazuje, jak dużą władzę nad przeglądarką ma Google. Kiedy pobieramy dodatki, to je „instalujemy” (z nazwy), ale nie ma to nic wspólnego z trwałą instalacją normalnych programów.
Wystarczy że Google przełączy po swojej stronie jeden pstryczek, a nasz dodatek do Chrome’a przestaje działać.
Podsumowanie
Parametry to dość ciekawy przykład tego, że granica między śledzeniem a normalnymi funkcjami internetu bywa rozmyta. I nie jest to ostatni przykład. Podobnie jest z innymi danymi, jakie wysyła nasza przeglądarka i jakie jeszcze poznamy.
W takiej sytuacji możemy oczywiście zdać się na autorów bezpiecznych przeglądarek i dodatków blokujących. I wierzyć, że będą na bieżąco aktualizowali listy blokowanych rzeczy.
Ale to tylko ludzie, a przeciwko sobie mają kilka wielkich organizacji. Kiedy zablokują jakiś parametr śledzący, to ich adwersarze mogą łatwo zmienić jego nazwę. Albo nawet całkiem wyłączyć ich dodatek.
Prywatność domyślna, za kulisami i bez kiwnięcia palcem ze strony użytkowników, to moim zdaniem utopia.
Dlatego jedyną trwalszą ochroną jest własna wiedza.
Żeby osoba chcąca prywatności wiedziała przynajmniej, żeby korzystać z jak najsilniejszej blokady. A kiedy jakieś strony nie będą działały, to żeby umiała tę blokadę tymczasowo wyłączyć.
Nie wydaje mi się, żeby to przerastało ludzi – w końcu już teraz podobnie wygląda sytuacja z ad blockerami. A w różnych korpo szkolenia z ochrony przed phishingiem są powszechne.
Takie „ABC” prywatności w sieci nie wydaje się poza zasięgiem, a dużo by zmieniło.
Ale koniec rozważań, robota czeka ![]()
W kolejnym wpisie będzie chwila odpoczynku od linków i powrót do „etykiety” (nagłówków HTTP).
Omówię rzecz ciekawą, ale nieco mniejszego kalibru – user agenta, czyli informacje o urządzeniu i przeglądarce. Do zobaczenia!
Był to wpis z serii Internetowa inwigilacja