
Internetowa inwigilacja 11 – JavaScript, cz.3
„Jak wyglądasz pod lupą?”
Wpis z serii Internetowa inwigilacja
Witajcie w trzecim i ostatnim wpisie poświęconym JavaScriptowi – językowi programowania internetu! A we wścibskich rękach lingua franca śledzenia internautów.
W pierwszym wpisie na temat JS-a poznaliśmy jego wygląd i ogólne działanie. Okazało się, że może zdobywać praktycznie wszystkie informacje wymienione w ośmiu wcześniejszych wpisach. A także wysyłać je w świat, na przykład swoim wścibskim autorom.
Wpis drugi pokazał, że jego możliwości są jeszcze większe i że może podpytywać o cechy naszego procesora, pamięci, internetu…
Rozpoznając nas nawet po tym, jak zmienimy przeglądarkę i adres IP. Na szczęście nie były to metody stuprocentowo skuteczne.
Tym razem natomiast przejdziemy do metod szczególnie wrednych, które potrafią wychwycić cechy zdecydowanie nas wyróżniające i przypisać nam unikalny identyfikator.
Metody z taką mocą rozpoznawania ludzi, że mówi się na nie fingerprinting – dosłownie pobieranie odcisku palca.
Zapraszam do lektury!

Spis treści
Śledzenie to codzienność
Spora część wpisów o JavaScripcie zawiera opisy różnych mechanizmów śledzących. Od niektórych może się włos jeżyć na głowie.
Ale nie zdziwiłbym się również, gdyby niektórzy czytelnicy powoli się wyłączali, mając wrażenie, że brniemy już w jakieś science fiction albo filmy szpiegowskie. Dlatego proponuję zrobić tu krótką przerwę na oswojenie się z faktem, że te metody są codziennością.
Spójrzmy najpierw na dowody anegdotyczne. Kilka egzotycznych metod śledzenia, które omówię w tym wpisie, znalezionych w internetach:
- Na ogromnym forum Reddit wykryto śledzący skrypt od firmy HUMAN. Wykorzystujący JavaScript do sprawdzenia wielu dokładnych informacji o komputerze. A nawet wykorzystujący luki w zabezpieczeniach, jak wirus.
- Na stronie StackOverflow – najpopularniejszym forum z pytaniami i odpowiedziami dla programistów – znaleziono skrypt profilujący na podstawie karty dźwiękowej.
- Przykłady profilowania przez WebGL na największych stronach, wraz z fragmentami kodu, zebrał pewien autor na swojej stronce. Jeśli wierzyć jego przykładom, znajdziemy tam między innymi firmy Amazon, Yahoo, Instagram.
Niepokojące są również szersze trendy:
- Już w 2014 roku, gdy śledzenia było mniej, w artykule The Web never forgets… opisano, że skrypty profilujące na podstawie grafiki wykryto na około 5,5% ze 100 tysięcy najpopularniejszych stron internetowych.
- W artykule naukowym z 2017 roku jest już mowa o użyciu podobnych metod śledzenia na ponad 10% z najpopularniejszych 10 tysiący stron.
Jest to zatem rzecz częsta, popularna i – niestety – możliwe że tylko zyskująca na popularności.
W niektórych przypadkach skrypty profilujące miały ponoć służyć nie do celów reklamowo-śledzących, tylko do ochrony przed botami – żeby wykryć, że osoba Y wchodząca na stronę jest tak naprawdę osobą X, po zmianie paru informacji, która chwilę wcześniej podkradała dane z bazy.
Ale niech nas to nie uspokaja. Po pierwsze, jeśli te dane są wysyłane w świat, nie mamy pewności co do ich dalszych losów.
Po drugie: reklamodawcy i firmy analityczne też są doskonale świadomi możliwości JavaScriptu.
Posłuchajmy sami jednego z większych graczy, czyli IAB.
Przykład informacji z IAB
IAB, czyli Interactive Advertising Bureau. Organizacja reprezentująca firmy zajmujące się reklamą internetową, często opartą na profilowaniu użytkowników. Ujednolica pewne rozwiązania, takie jak wyskakujące okna pytające nas o zgodę na zbieranie informacji.
Wokół tych banerów narosły zresztą pewne kontrowersje, ponieważ pstryczki pozwalające nie wyrazić zgody na profilowanie są ukryte dość głęboko, wbrew zaleceniom GDPR/RODO. Systemu IAB nie polubił belgijski urząd ds. ochrony danych, uznając go za sprzeczny z prawem.
Z banerami IAB możemy zetknąć się na przykład po wejściu na strony należące do grupy Wirtualna Polska, takie jak pewien artykuł ze strony Money.pl.

Jeśli wcześniej nie pozwalaliśmy im na zbieranie informacji, to treść się rozmyje i wyskoczy baner proszący o udzielenie zgody. Jeśli nie wyskoczy, to można spróbować odwiedzić stronę w trybie incognito.
Zamiast klikać na banerze wyróżnione Zgódź się, możemy kliknąć w Listę partnerów IAB, żeby zobaczyć dokładniejsze opcje. Mamy tutaj dokładniejsze opisy rzeczy, na które chcą naszej zgody. W punkcie numer 15 piszą o tworzeniu:
(…) identyfikatora przy użyciu danych zebranych poprzez aktywne skanowanie (…) np. zainstalowanych czcionek lub rozdzielczości ekranu
To dobry przykład na to, że metody profilowania przez JavaScript nie są czymś egzotycznym, używanym tylko w ciemnych zaułkach internetu. Nie; te informacje o wymiarach okna (z poprzedniego wpisu) czy o zainstalowanych czcionkach (z tego wpisu) są znane i często stosowane. Również przez branżę reklamową, na dużych i znanych stronach. Wobec nas.
Śledzenie jest łatwe
Niektóre z metod śledzenia przez JavaScript – szczególnie te, które opiszę w tym wpisie – mogą wydawać się skomplikowane. Możemy w związku z tym mieć wątpliwości, czy to realne zagrożenie. Naprawdę jest na świecie tylu ludzi, którzy nic nie robią, tylko profilują?
Odpowiedź: tak, to realne. Dodanie do swojej strony opcji śledzenia może być kwestią paru kliknięć.
Wystarczy dołączyć do którejś z sieci reklamowych i wykonać kilka instrukcji. Takich jak dodanie do źródła strony kilku linijek odpowiedzialnych za pobranie i włączenie cudzego skryptu. Który już zrobi resztę.
Istnieją firmy, których cała działalność opiera się na opracowywaniu metod profilowania. To oni robią te bardziej pomysłowe, złożone rzeczy. Następnie pakują swoje rozwiązania w skrypty, które łatwo spiąć z inną stroną. I sprzedają je innym.
Dlatego zupełnie nie ma co się dziwić, gdybyśmy znaleźli skrypt śledzący na przykład na stronie sieci supermarketów. Jasne, raczej nie mają własnych etatowych „programistów śledczych”. Ale mogli kupić skrypty profilujące od kogoś innego i zapłacić za wdrożenie.
Kolejna sprawa: czy takie metody mogą być skuteczne? W końcu to wiele różnych danych, sygnałów. Być może firmy same potykałyby się o własne nogi, próbując z tego wyciągnąć coś sensownego?
Odpowiedź: tak, to skuteczne. W świecie komputerów istnieje bardzo popularna metoda zwana haszowaniem. Pozwala ścisnąć wiele różnych wartości do jednego ciągu znaków. Co więcej, istnieją odmiany takie jak MinHash – otrzymane ciągi znaków są tym bardziej do siebie podobne, im bardziej podobne były dane początkowe.
Zatem ustalenie odpowiedzi na pytanie „Czy użytkownik X to ta sama osoba co użytkownik Y?” może się sprowadzać do zebrania informacji przez skrypt, ściśnięcia ich w jedną liczbę, porównania z liczbami wcześniej zebranymi. Wszystko w pełni automatycznie.
Nie ma co liczyć na to, że zadanie przerośnie naszych adwersarzy!
Różne oblicza fingerprintingu
Mam nadzieję, że utwierdziliśmy się już w przekonaniu, że to nie science fiction, tylko nasza codzienność. Lekkie napięcie zbudowane – jak w horrorach, gdy wiemy że będzie straszno, a do tego w pierwszych sekundach wyświetla się napis „Film oparty na faktach”.
Spójrzmy na szczególnie wredne metody profilowania.
Wykrywanie dodatków
Wiele dodatków do przeglądarek zmienia w jakiś sposób strony internetowe. Na przykład stylizując w określony sposób ich elementy albo nawet dodając coś charakterystycznego od siebie:
- Przykład mi najbliższy: mój dodatek
SelSword, który stworzyłem w celu zaznaczania komentarzy trolli. Kliknięty komentarz z Twittera albo Facebooka otacza czerwoną ramką. - Drugi przykład: uBlock Origin z włączonym blokowaniem obrazków. W takim wypadku miejsce, w którym powinien być obrazek, zostaje otoczone kropkowaną ramką.
- Inny przykład, z artykułu naukowego: dodatek pozwalający zapisywać niektóre treści, który dodaje pod nimi specjalny przycisk.
Takie graficzne zmiany mogą być dla nas wygodne, bo widzimy, czy nasz dodatek działa.
Ale jest pewien problem – jeśli coś widzimy, to znaczy, że zapewne pojawiło się w kodzie HTML strony. A JavaScript ma wgląd w cały ten kod.
Na przykład czerwona ramka dodawana przez SelSword jest widoczna w kodzie jako:
JS może wykryć takie elementy obce na stronie. A jeśli ma dostęp do jakiejś wielkiej bazy, zawierającej typowe elementy zmieniane przez dodatki, to jest w stanie określić, z jakich konkretnych dodatków korzystaliśmy.
Jeśli nasz zestaw jest nietypowy, to może się to stać bardzo silnym znakiem rozpoznawczym. Z tego względu dobrze mieć tych dodatków jak najmniej; wyłącznie zaufane, najlepiej nie ingerujące w treść każdej napotkanej strony.
Canvas
Element canvas (ang. „płótno”, w sensie malarskim) z pozoru wydaje się niegroźny; to jeden z możliwych elementów podstawowych, z których można ułożyć stronę internetową. Na równi z akapitem, tabelką, przyciskiem i innymi rzeczami tego typu. Sam w sobie nie ma wyglądu, chyba że go wystylizujemy (tu np. dodałem obramowanie):
Pełni natomiast dość konkretną funkcję – kod JavaScript może na nim umieszczać elementy graficzne. Koła, linie i tym podobne. Może również wyciągać z niego stworzone obrazki, piksel po pikselu. Jak zobaczymy, to ta właściwość umożliwia śledzenie.
Gdyby element canvas był używany zgodnie z przeznaczeniem, mógłby służyć do prostych interaktywnych wizualizacji, którymi steruje użytkownik. Ale wścibskie strony znalazły własne zastosowanie.
Spójrzmy na nagłówek mojego bloga w dwóch różnych przeglądarkach:
Ten u góry został otwarty w przeglądarce Brave, ten z dołu w Firefoksie. W obu przypadkach powiększenie ustawione na domyślne (100%), pełne okno.
Nagłówki wydają się prawie identyczne, prawda? Ale zróbmy zbliżenie na lewe oko emotki.

Teraz już widać różnice. Zwłaszcza w pikselach na brzegach; to tam zachodzi antialiasing, czyli lekkie zlewanie krawędzi z tłem, żeby wydawała się gładsza. Brave i Firefox korzystają z różnych silników, więc i efekt końcowy jest inny.
Bo widzicie… Grafika to złożona sprawa. Zaczyna się od prostej instrukcji graficznej, mówiącej komputerowi „stwórz linię”. Kończy się na pikselach wyświetlonych na ekranie.
Po drodze mamy wszelkie konwersje, transfery do karty graficznej, zaokrąglanie liczb, wygładzanie kantów… W efekcie istnieją subtelne różnice między tym samym obrazkiem u dwóch różnych użytkowników. Zaś jeden i ten sam użytkownik ma zwykle podobne piksele.
Na tym opiera się śledzenie przez canvas; kod JavaScript każe naszej przeglądarce dodawać do tego elementu (ukrytego przed naszym wzrokiem) różne kształty. Potem pobiera gotowy obrazek i porównuje piksele z tymi, które wyszły innym internautom wchodzącym na wirtualne „terytorium” danej firmy.
Możemy zmienić swój adres IP, wyczyścić pliki cookies, włączyć tryb incognito. Ale dopóki cały czas używamy tej samej kombinacji sprzętu, systemu i przeglądarki, wychodzą nam te same piksele. Jesteśmy rozpoznawalni.
Możecie sami sprawdzić, przez stronę BrowserLeaks, jaki odcisk palca zostawicie na płótnie. Polecam też rozwinąć zakładkę How Does It Work i spojrzeć na ich przykładowy kod. Nawet jeśli jest uproszczony, to widać że takie profilowanie nie jest jakąś wyższą matematyką. Względnie łatwo je u siebie wdrożyć.
 Ciekawostka
Ciekawostka
Firmą przodującą w „śledzeniu przez płótno” jest AddThis; ich elementy śledzące znajdowały się ponoć w wielu różnych miejscach, w tym na stronie YouP*rn (autocenzura wyłącznie z obawy przed deindeksacją).
A także… na stronie Białego Domu.
Czcionki
Sprawa dość mocno związana z poprzednią. Mianowicie: JavaScript, oprócz kształtów geometrycznych, może również kazać przeglądarce tworzyć tekst.
Pierwszy sposób, w jaki czcionki mogą nas identyfikować, to wspomniane wyżej różnice między pikselami; zwłaszcza na brzegach, tam gdzie działa wygładzanie. Dodawanie tekstu można w ten sposób uczynić częścią canvas fingerprintingu, żeby poprawić jego dokładność.
Ale czcionki można wykorzystać do jeszcze dokładniejszego profilowania – określić, jakie dokładnie trzymamy na swoim systemie.
Bo widzicie – wszystkie zainstalowane programy zwykle czerpią czcionki z jednego, zbiorczego folderu, żeby się nie dublować.
Kiedyś chciałem napisać pewnej osobie życzenia w Gimpie, czcionką w kocie łapy. W tym celu ją pobrałem i włożyłem do specjalnego folderu na swoim komputerze.
Ale w ten sposób stała się widoczna również dla pozostałych programów, w tym przeglądarki.
I teraz, kiedy odwiedzam wścibską stronę, może się zdarzyć coś takiego:
- JavaScript wydaje mojej przeglądarce polecenie: „Napisz w tym miejscu Hejo czcionką CatFont”;
- przeglądarka to robi;
- JavaScript sprawdza, jaka jest szerokość elementu po dodaniu do niego tekstu. Jeśli zgadza się ze spodziewaną, to znaczy, że mamy czcionkę CatFont na komputerze.
- Następnie każe napisać ten sam tekst czcionką DogFont.
- …Ale jej już nie mamy, więc zamiast tego przeglądarka tworzy napis czcionką domyślną.
- JavaScript to mierzy i widzi, że szerokość mu się nie zgadza. Wniosek: nie mamy tej czcionki.
Powtarzając takie polecenia wiele tysięcy razy, JavaScript może dokładnie ustalić, jakie czcionki zainstalowaliśmy u siebie na systemie. A ta cecha – zwłaszcza jeśli robimy coś związanego z grafiką i często dodajemy nowe czcionki – może bardzo mocno nas wyróżniać.
WebGL
Kolejna graficzna rzecz!
Współczesne przeglądarki, szczególnie Chrome, lubią dodawać nowe bajery. Jednym z nich jest możliwość wyświetlania zaawansowanej grafiki w przeglądarce przez WebGL (gdzie WebGL to przeniesienie w realia internetu bardzo popularnego pakietu OpenGL. GL od Graphics Library).
Grafika w czasie rzeczywistym – taka jak sceny w grach komputerowych – jest dość wymagająca. Zatem przeglądarka usuwa się z drogi, dając stronie bezpośredni dostęp do pewnych funkcji procesora i karty graficznej.
A JavaScript może wykorzystać te informacje do dokładniejszego profilowania. W praktyce wykorzystuje WebGL w dwojaki sposób:
- Podpytuje przeglądarkę o parametry karty graficznej, dostępne rozszerzenia itp. Jest tych informacji naprawdę sporo.
- Każe przeglądarce zrobić coś związanego z grafiką, na podobnej zasadzie jak przy canvas fingerprintingu. Identyczny efekt końcowy oznacza zapewne identycznego użytkownika.
Jeśli chcemy zobaczyć pełną listę rzeczy, jakie ujawnia nasza przeglądarka, to polecam podstronę o WebGL na Browser Leaks.
Warto się w szczególności upewnić, czy nie ujawniamy pola Unmasked Renderer – to pełna nazwa naszej karty graficznej. Chrome i podobne mu przeglądarki to ujawniają.
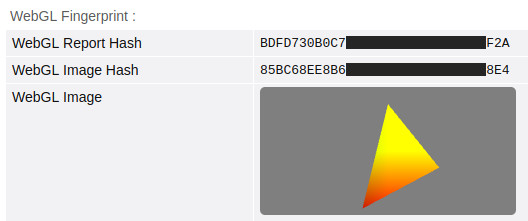
Źródło: Browser Leaks. Hasze zakryte przeze mnie.
Z nowszych, tegorocznych spraw: twórcy innej stronki testującej naszą anonimowość, AmIUnique, zbadali pewną metodę profilowania, której nadali kryptonim DrawnApart.
Jest ona o tyle niepokojąca, że ustala wnikliwie pewne cechy naszej karty graficznej, które mogą się różnić nawet między tymi samym jej modelami.
Załóżmy, że używam popularnej karty graficznej zintegrowanej z procesorem – dajmy na to Intel i5-4590. Ktoś inny używa takiej samej karty, przeglądarki oraz publicznego hotspota. W normalnych warunkach byśmy się ze sobą zlewali, ale przez WebGL dałoby się nas od siebie odróżnić, na podstawie subtelnych różnic fabrycznych między naszymi kartami.
Web Audio
Wielu z nas lubi sobie posłuchać jakiegoś dobrego bangerka. Dlatego nasze komputery, oprócz procesorów i kart graficznych, dysponują również kartami dźwiękowymi.
Tym kartom również wyszli naprzeciw twórcy przeglądarek, dając JavaScriptowi możliwość bezpośredniej komunikacji z nimi. Możliwość oczywiście nadużytą do celów śledzenia.
W kwestii opisu metody zdam się na ludzi od FingerprintJS. Mówiąc ogólnie, polega ona na podaniu komputerowi kilku parametrów, żeby najpierw wygenerował falę dźwiękową, a potem ją skompresował.
Efekt jego działań zmienia się w zależności od przeglądarki, ale zapewne każdorazowo będzie taki sam dla tego samego zestawu sprzęt + system + przeglądarka. Zatem: kolejny identyfikator do kolekcji.
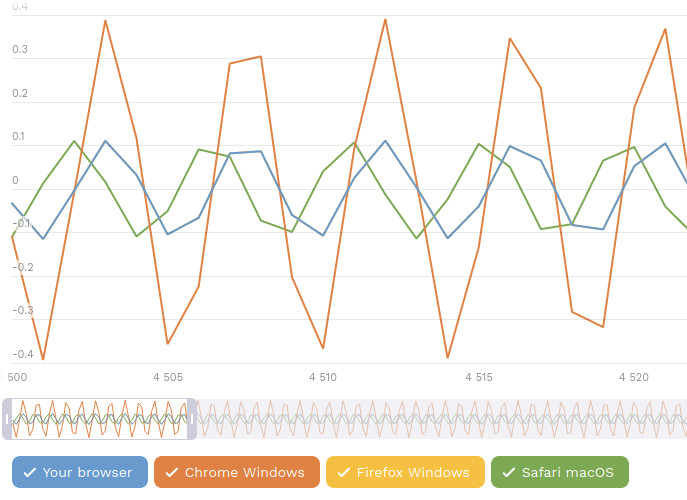
Źródło: artykuł FingerprintJS. Nie widać żółtej linii, bo mój wykres pokrywa się niemal w 100% z tym dla Firefoksa na Windowsie.
Skrypt profilujący przez dźwięk, jak już wspomniałem, został znaleziony między innymi na znanym forum StackOverflow.
Właściwości silnika JavaScriptu
Skrypt śledzący z Reddita, prawdziwa skarbnica śledzącego JavaScriptu, zawierał tajemniczy komentarz: haha jit go brrrrr.
Sam autor wpisu analizującego kod nie miał stuprocentowej pewności, do czego to służy, ale podejrzewał jakieś hece z silnikiem przetwarzającym kod.
Tłumaczenie mema
Wyobraźcie sobie bardzo śmiesznego mema. I zacznijcie się śmiać.
A tak na serio: haha X go brrr (gdzie zamiast brrr mamy czasem inny dźwięk) pierwotnie pojawia się w memie o drukowaniu kasy. Potem został on uogólniony do każdej sytuacji, kiedy jedna postać ma na coś proste, choć toporne rozwiązanie, a drugą to wkurza.
Istnieje na przykład wersja z Aleksandrem Wielkim i węzłem gordyjskim.
„Niee, nie możesz tego tak po prostu przeciąć”. „Haha, miecz robi ciach, ciach”.
{kind=link}
Ale koniec z memami. Bardziej niż go brrr interesuje nas JIT.
To zapewne skrót od Just In Time; metody, jaką JavaScript wykorzystuje do przekształcania naszego kodu w coś czytelnego dla komputera.
Zachęciło mnie to, żeby powpisywać jit javascript fingerprinting i podobne rzeczy w wyszukiwarkę. I w ten sposób natrafiłem na artykuł na temat profilowania na podstawie JavaScriptu.
Okazuje się bowiem, że można nas profilować według zachowania JavaScriptu, wyciągając ciekawe fakty na temat naszego procesora.
Wspominałem wcześniej o grafice: na początku mamy prostą, czytelną dla komputera regułkę, a po wszystkich przeróbkach otrzymujemy piksele wyświetlone na monitorze. Czytelne dla nas.
Przy przekształcaniu języka jest na odwrót. Zaczynamy od czytelnego kodu JavaScript, napisanego przez człowieka. A po różnych przekształceniach kończymy z enigmatycznymi instrukcjami przeznaczonymi dla komputera.
Wszystkie te przekształcenia mają na celu sprawienie, żeby kod szybciej działał, lepsze dopasowanie go do możliwości procesora.
W skrajnych przypadkach, pokazanych w artykule, dwa prawie identyczne fragmenty kodu dają różne zestawy instrukcji. W zależności od tego, czy procesor jest przystosowany do pracy z blokami 32- czy 64-bitowymi:

Jedno i drugie brzmi dla mnie jak marsjański; ale widać, że pierwszy marsjański nieco się różni od drugiego.
Źródło: artykuł z 2019 roku.
A to tylko jedna z możliwości. Artykuł porusza również inne kwestie, takie jak zachowanie modułu zarządzającego pamięcią. Sens metody zapewne podobny; patrzenie na punkty graniczne, w których coś ulega istotnej zmianie.
Odpowiednio dobierając zadania dla kodu, można ustalić kilka istotnych właściwości, jakie posiada nasz sprzęt. I dorzucić je do naszego odcisku palca.
Myślę, że na dziś nam starczy. A jeśli komuś mało, to zachęcam do zastanowienia się, ile punktów do analizy zyskałyby firmy, gdyby w sieci spopularyzowała się wirtualna rzeczywistość (wymagająca stałego monitorowania ruchów ciała i gałek ocznych).
Jak się chronić
Przede wszystkim instalujemy dodatek uBlock Origin – blokuje pliki z zewnętrznych witryn, zgłoszonych przez użytkowników jako podejrzane. W tym również JavaScript śledzący od firm takich jak wspomniana AddThis. Jakąś część śledzenia w ten sposób wytniemy z życia.
A co, jeśli JavaScript znajduje się bezpośrednio na odwiedzanej stronie, wkomponowany w jej elementy, i nie jest pobierany z zewnątrz?
Jakimś sposobem jest korzystanie z przeglądarek, które mają swoje zasługi w walce z profilowaniem i nie dodają na ślepo wszystkich nowinek. Polecam Firefoksa albo Brave’a. Nie polecam Chrome’a, bo aktywnie działa na szkodę dodatków blokujących.
W przypadku Firefoksa można włączyć funkcję dodatkowej ochrony.
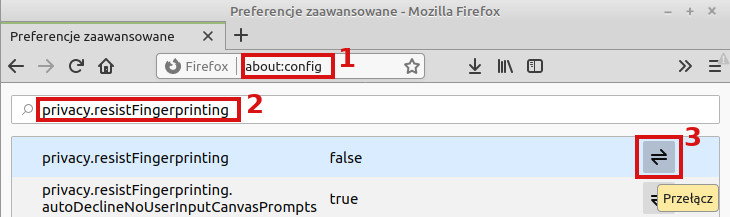
W tym trybie przeglądarka staje się lisem kłamczuchem i podaje stronom nieprawdziwe informacje, żeby ułatwić nam zlanie się z tłumem.
Niestety wymaga to pewnych wyrzeczeń. Przykład: zmienia nam strefę czasową, więc mogą przestać działać automatyczne podpowiedzi podczas np. kupowania biletów kolejowych online.
Wytrawni gracze mogą korzystać z Tor Browsera. To nie tylko anonimowe IP; Tor dba również o wiele innych aspektów anonimizacji. Ale do codziennego użytku może być nieprzyjemny, bo jest raczej powolny i niejedna strona go blokuje.
Unikanie zamiast walki
W każdym razie, niezależnie od jakości przeglądarki, powtórzę nieco kontrowersyjną poradę z poprzedniego wpisu.
A brzmi ona: jeśli zależy nam na zwycięstwie w tej grze, to najlepiej w nią nie grać.
Nawet jeśli ufamy swojej przeglądarce. Zawsze może się pojawić jakaś metoda profilowania, której jej twórcy nie wychwycą; a fakt, że nasza przeglądarka próbowała jej unikać, tylko nas wyróżni.
Dlatego, chcąc naprawdę chronić prywatność, wyłączmy JavaScript całkowicie. Wiele odwiedzanych stron nie będzie działało, ale na niektóre może się udać wejść.
A jeśli mamy do sprawdzenia coś, czego naprawdę nie chcemy ujawniać internetowym korporacjom, to warto się przejść do miejsca publicznego i skorzystać z tamtejszych komputerów. Pamiętając, żeby nie logować się na żadne swoje konto.
Porada
Specjalnym przypadkiem jest Google oraz inne firmy mające jednocześnie apki mobilne oraz strony, na których czegoś szukamy.
Idąc do biblioteki w tajemnicy przed nimi, najlepiej nie brać ze sobą telefonu (albo przynajmniej włączyć w nim tryb samolotowy).
Dlaczego? Bo moglibyśmy nieświadomie się połączyć z bibliotecznym hotspotem. Po czym nasz telefon, w ramach rutynowej aktualizacji apek, pobrałby coś od nich. Przy okazji mógłby „podpisać” się tym samym adresem IP, z którego właśnie robimy nasze prywatne wyszukiwania na ich stronach.
A jeśli jesteśmy gotowi całkiem wyłączyć JavaScript?
Można to zrobić przez opcje wspomnianego uBlock Origin. Skoro i tak go używamy przeciw plikom śledzącym ze stron zewnętrznych, to można również skorzystać z pozostałych jego możliwości.
Niszczenie banerów
A jeśli nie chce nam się specjalnie iść do biblioteki ani użerać się z częstym włączaniem JS-a, gdy strona bez niego nie działa?
W takim wypadku pozostaje wziąć ryzyko na siebie; natomiast mam jedną propozycję, która może nieco ułatwić nam życie.
Mianowicie: uBO posiada dość rzadko opisywaną funkcję niszczenia elementów, oznaczoną ikonką błyskawicy. W tym trybie klikamy jakiś element na stronce, a on znika. Można ustawić własny skrót klawiszowy włączający tę opcję – osobiście wybrałem Ctrl + , (przecinek).
Pamiętacie baner od IAB, który pokazałem na początku? Strony chcące działać zgodnie z GDPR/RODO nie powinny zbierać od nas żadnych danych (również przez JavaScript), dopóki nie klikniemy, że wyrażamy na to zgodę. Jeśli wyłapiemy, że robią inaczej, to mamy prawo ich zgłosić.
A co się stanie, jeśli po prostu zniszczymy baner zaraz po tym jak wyskoczy? Zapewne zniknie, pozwalając nam przeglądać stronę. A żadnej zgody oficjalnie nie wyraziliśmy, więc nie powinno być śledzenia ![]()
W przypadku ustawienia skrótu klawiszowego niszczenie banerów to kwestia sekund. Wystarczy:
- Nacisnąć ustawiony skrót;
- Najechać kursorem myszy na wkurzający element (oznaczy się kolorem);
- Naciskać
Delete, dopóki nie znikną wszystkie niechciane elementy; - Nacisnąć
Esc, żeby wyjść z trybu usuwania.
Potem można w spokoju przeglądać stronkę, o ile nie korzysta z wredniejszych metod antyblokerowych. Metoda niecodzienna, ale może dzięki temu skuteczna. Polecam!
Podsumowanie
Tym wpisem kończę trylogię na temat JavaScriptu. Nie oznacza to w żadnym razie, że wyczerpałem temat – metody śledzenia ogranicza jedynie ludzka kreatywność. A coraz to nowe funkcje, promowane przez firmę Google i ich Chrome’a, z pewnością będą na bieżąco wykorzystywane do celów profilowania ![]()
Powoli zbliżamy się też do końca „Internetowej inwigilacji”.
Wiemy już całkiem sporo o mechanizmach, z jakich korzystają firmy, żeby kompletować nasze cyfrowe teczki. Od informacji ujawnianych przy pierwszym kontakcie aż po te wymagające wnikliwego testowania naszego urządzenia.
W kolejnym wpisie zbiorę to w całość i połączę w jeden poradnik po ochronie internetowej prywatności. Będzie to również oficjalne zamknięcie serii; tej głównej, bo stworzę jeszcze niejeden wpis uzupełniający.
Do zobaczenia!
Był to wpis z serii Internetowa inwigilacja