
Internetowa inwigilacja 8 – pliki cookies i piksele śledzące
„Już cię u kogoś widziałem...”
Wpis z serii Internetowa inwigilacja
W poprzednich wpisach pokazałem, że za każdym razem, gdy odwiedzamy jakąś stronę internetową, nasza przeglądarka wysyła jej „właścicielom” różne informacje w tzw. nagłówkach HTTP.
Ostatnio omówiłem dokładniej jedną z tych informacji, pliki cookies, zwane potocznie ciasteczkami. Krótkie fragmenty tekstu, które przeglądarka najpierw otrzymuje, potem przechowuje, a na koniec pokazuje tej samej stronce, od której je dostała.
Poprzedni wpis skupił się na ogólnym działaniu plików cookies oraz na ich mniej groźnym zastosowaniu – logowaniu na swoje konto.
Teraz natomiast przejdziemy do plików cookies ze stron zewnętrznych (ang. third party cookies). Używanych głównie w celu śledzenia naszych wędrówek po internecie.
Moim zdaniem to jeden z najważniejszych wpisów w całej serii.
Zobaczymy tu, w jaki sposób dwa filary internetu – nagłówki oraz pliki cookies – zostały wykorzystane do masowego zbierania danych o użytkownikach.
Postaram się opisać wszystko w sposób przystępny, zaczynając od historyjki, żeby nawet nowi czytelnicy się w tym odnaleźli. Tym niemniej zachęcam do przeczytania wpisów o nagłówkach HTTP oraz o plikach cookies, jeśli chcemy mieć więcej kontekstu.
Spis treści
Historyjka o kawie i ciasteczkach
W niektórych wpisach porównywałem internet do sieci placówek pocztowych. Ale tym razem użyję innej analogii, która lepiej mi pasuje. Będzie to fikcyjna historyjka z życia.
Wyobraźmy sobie, że wykonujemy pracę biurową w dużym mieście (czyt. jesteśmy korpoludkiem). Tym miastem jest internet.
Pierwszy kontakt – korpo
Zatrudniając się w naszym korpo (zakładając konto) dostaliśmy identyfikator na smyczce. To plik cookie. Dowolna rzecz, jaką dostaliśmy od określonej firmy i jaką pokazujemy tylko jej przedstawicielom.
Jak choćby recepcjoniście. Po wejściu do korpo za każdym razem dajemy mu firmowy identyfikator. On przykłada go do czytnika, sprawdza ważność. Jeśli jest OK, to nas wpuszcza.
W tej prostej interakcji biorą udział dwie strony. My, odwiedzający, jesteśmy pierwszą. Recepcjonista drugą.
Jeśli recepcjonista chce, może sobie za naszymi plecami zanotować, że weszliśmy. O godzinie tej i tej, pokazując identyfikator taki i taki.
Ogólnie każda osoba, z którą wejdziemy w interakcję (serwer) może to notować. A my się o tym nie dowiemy. No ale trudno, żyje się dalej.
Gdyby nie istniało coś takiego jak pliki cookies od stron trzecich, to historyjka mogłaby się skończyć w tym miejscu.
Ale tak nie jest. Pewnego dnia wita nas niespodzianka. Zaraz za wejściem rozstawił się punkt z darmową kawą!
Nasze korpo uznało, że poprawi morale i tymczasowo zaprosiło do siebie popularną sieć kawiarni – nazwijmy ją Facebucks. Nie bez znaczenia był fakt, że Facebucks oferuje takie gościnne występy za darmo.

Pracownik obsługujący punkt z kawą jest w korpo gościem, więc to tak zwana trzecia strona (third party). Daje nam kawę, a oprócz niej kartę do zbierania pieczątek! Taki drobny upominek od osoby z zewnątrz to właśnie ciasteczko od strony zewnętrznej.
Nie pokazywaliśmy pracownikowi identyfikatora naszego korpo, więc nie zna naszych danych osobowych. Ale i tak notuje za naszymi plecami:
W siedzibie firmy Zdziw Corp, dnia A o godzinie B, dałem kartę numer 123420 osobie o blond włosach, zielonych oczach, mówiącej po polsku. Chyba tu pracuje.
W świecie przeglądarek odpowiednikiem naszych widocznych cech są informacje z nagłówków HTTP.
Nasz wygląd jest jak atrybut User-Agent. Język, jakim mówimy, jak atrybut Accept-Language. Ujawniamy te informacje podczas każdej interakcji z innymi.
Drugi kontakt – targi pracy
Nasze życie toczy się dalej. Przefarbowujemy włosy na białe – bo wyszedł nowy sezon „Wiedźmina”, trzeba iść za trendami – i zaczynamy nosić niebieskie szkła kontaktowe (zapamiętajcie, to ważne!).
Z tymi nowymi cechami odwiedzamy targi pracy, bo myślimy o zmianie korpo. Wchodzimy tam po okazaniu kupionego wcześniej biletu. On również jest jak plik cookie, tylko że od organizatora targów.
A my jesteśmy dyskretni i każdej firmie pokazujemy tylko tę rzecz, jaką od nich dostaliśmy. Nasze korpo nie dowie się, że odwiedziliśmy targi. A targi nie dowiedzą się, gdzie pracujemy. Idealny układ.
Ale cóż to widzimy? Stoisko z kawą od Facebucksa! Targi ich tu wpuściły, żeby umilali czas odwiedzającym (no i – nie ukrywajmy – bo oferują takie gościnne występy za darmo. Oficjalnie po to, żeby nieść światu dobrą kawę).
Stoisko obsługuje nieznana nam brunetka. Kiedy pokazujemy swoją kartę na pieczątki, to zerka na jej numer, wpisuje coś w terminal. W końcu podaje nam kawę, mówiąc: „Też myślałam o niebieskich soczewkach!”.
Odchodzimy z lekką konsternacją, macając palcem w okolicy oka. Aż tak widać, że nosimy soczewki? Przecież wyglądały naturalnie.
A może… jakimś cudem wiedziała, że mieliśmy wcześniej inny kolor oczu? Ale odpędzamy od siebie tę głupią myśl.
Tylko że to nie była głupia myśl. Za kulisami wszystkie placówki Facebucksa korzystają ze wspólnej bazy i dzielą się informacjami. Każda karta na pieczątki (plik cookie, przypominam) ma unikalny numer przypisany konkretnej osobie. A nasze pozostałe cechy – jak wyglądamy, gdzie i kiedy nas widziano – trafiają do bazy jako informacje uzupełniające.
Teraz na przykład pracownica notuje za naszymi plecami:
Osoba numer 123420, dnia X o godzinie Y, odwiedziła targi pracy. Ma teraz białe włosy i niebieskie oczy. Reszta danych bez zmian.
Analiza: prawdopodobnie chce zmienić obecną pracę, w Zdziw Corp. Ma soczewki kontaktowe i używa białej farby do włosów. Możliwe zainteresowanie serią „Wiedźmin”.
Nie znają naszych danych osobowych, jesteśmy tylko numerem. Ale nadal mogą do tego numeru przypisywać różne obserwacje, powoli tworząc nasz profil-cień (ang. shadow profile).
Trzeci kontakt – kawiarnia
A teraz wyobraźmy sobie, że kawiarnia Facebucks nas skusiła swoją ofertą specjalną. Wyrabiając imienną kartę członkowską, dostaniemy za darmo karmelowe latte bez mleka!
Tylko że takiego czegoś nie oferują małe mobilne punkty, a jedynie ich własne firmowe lokale. Odwiedzamy jeden z nich (wchodzimy na stronę główną).
Żeby wyrobić imienną kartę, musimy pokazać swój dowód osobisty i kartę z pieczątkami. I jeszcze tylko szybki podpis pod zgodą na przetwarzanie danych. Nie czytamy, bo przecież tak dobrze im z oczu patrzy.
W momencie, gdy podamy kartę na pieczątki razem z dowodem, za kulisami następuje łączenie danych. Cały profil-cień, budowany przez małe punkty z kawą dla anonimowego numeru, zyskał właśnie konkretną tożsamość. Imię, nazwisko, numer dowodu.
My tymczasem, w błogiej nieświadomości, konsumujemy naszą słodko-mdławą nagrodę.
Epilog
Kiedy przychodzimy do naszego korpo, znowu widzimy punkt z kawą od Facebucksa. Tym razem obsługuje go inny, zupełnie nam obcy sprzedawca.
Mimo to wystarczy mu rzut oka na numer naszej karty i na terminal, żeby zwrócił się do nas po imieniu, jak do kogoś znajomego:
„Cześć, Anon(-ka)! Słyszeliśmy, że myślisz o zmianie pracy. Mamy tu kilka ofert od naszych partnerów biznesowych, polecam gorąco.
Aha, a może chcesz kupić płyn do soczewek?”.
I tak oto, z lekkim dreszczem, poznajemy odpowiedź na pytanie, jakim cudem Facebucksowi opłaca się odwiedzać za darmo każde możliwe miejsce. Ich biznes nigdy nie opierał się na kawie – tylko na ciasteczkach. Posypanych danymi.
Powrót do rzeczywistości
Mechanizm działania internetowych gigantów jest bardzo podobny jak kawiarni Facebucks z historyjki.
Tworzą coś, co by się przydało wielu mniejszym stronom. Udostępniają to za darmo. Nie jest to może kawa, ale też bywa pożądane:
- Facebook – oferują przyciski, które po kliknięciu zostawiają stronie polubienia;
- Twitter – opcję łatwego umieszczania treści tweetów na stronach zewnętrznych;
- Google – cały arsenał darmowych narzędzi. Google Fonts, Google Analytics, reCaptcha…
Właściciele stron z tego korzystają i dodają te „elementy gościnne” do siebie. Efekt uboczny: gdy odwiedzamy takie strony, to dowiadują się o tym nie tylko one, ale również właściciele internetowych korporacji.
A ci goście goszczą w wielu miejscach.
Przykładowo: skrypty od Google Analytics już w 2009 roku znajdowały się na ponad połowie z 10 000 najpopularniejszych stron. A w ostatnich latach? Według strony analizującej ruch w sieci, w3techs.com:
Google Analytics jest wykorzystywane przez 56,7% wszystkich stron internetowych, co oznacza że jego udział w segmencie narzędzi do analizy ruchu wynosi 86,3%.
Źródło: raport w3techs.com (tłumaczenie moje).
Na drugim miejscu plasuje się narzędzie Facebooka, Facebook Pixel, używane na 11,3% analizowanych stron.
Taka popularność sprawia, że podczas przeciętnego spaceru po internecie spotkamy zwykle przynajmniej kilka elementów analitycznych, zapewne od któregoś z cyfrowych gigantów.
Jeśli jesteśmy zalogowani na swoje konto na którejś z wielkich stron (czyt. po wejściu w odpowiedni adres – facebook.com, gmail.com itp. – widzimy swoje dane, a nie ogólny ekran logowania), to znaczy że nosimy ze sobą ich pliki cookies.
Kiedy je nosimy, elementy gościnne pochodzące z tej samej strony będą nas rozpoznawać.
Będą wiedzieli, że byliśmy tu i tam, o porze takiej i takiej. Wszystkie te informacje mogą analizować i porównywać z istniejącymi schematami, szufladkując nas w odpowiedniej przegródce dla reklamodawców.
Istnieje wiele metod rozpoznawania użytkowników, sam je opisywałem w poprzednich wpisach. Ale strony nawet nie muszą po nie sięgać, jeśli użytkownicy sami im się przedstawiają. Pliki cookies to takie internetowe odpowiedniki legitymacji albo dowodów osobistych.
Były ogólne rozważania, więc po nich tradycyjnie czas na coś konkretniejszego. Pokażę, czym są piksele śledzące, bardzo ściśle związane z plikami cookies.
Kulisy śledzenia
Tu już będzie szczypta techniki, całe kilka linijek HTML-a z objaśnieniami. Przeżyjemy? ![]()
Jak wyglądają elementy śledzące
Przedstawiam Wam wyjątkowo prostą stronę. Zawiera dwa obrazki z podpisami. Jeden z Ciemnej Strony, jeden z Wikipedii. W przeglądarce wygląda tak:

Natomiast jeśli zajrzymy w kod strony, zobaczymy coś takiego:
<html>
<body>
<p>Mój obrazek:</p>
<img src="moja-ikona.png"/>
<p>Cudzy obrazek:</p>
<img src="https://commons.wikimedia.org/w/index.php?title=Special:Redirect/file/Example.jpg"/>
</body>
</html>
Zielony tekst po <img src= to źródła dwóch wyświetlanych obrazków.
Zauważmy, że mamy dwa osobne rodzaje! W pierwszym przypadku to po prostu nazwa pliku, moja-ikona.png. Odnosi się do obrazka trzymanego w tym samym folderze co główna strona.
Natomiast źródłem drugiego pliku jest link do obcej strony – commons.wikimedia.org. To z niej został pobrany obrazek z tekstem „Just an example”.
Wyobraźmy sobie, że cała ta strona z dwoma obrazkami wisi sobie gdzieś w internecie, na przykład pod adresem example.com.
Gdybyśmy weszli w link do niej, mielibyśmy wrażenie, że od razu „pojawiła” nam się kompletna strona. Ale to iluzja, po prostu internet jest szybki.
W rzeczywistości dostajemy stronkę „na raty”, a za kulisami dzieją się następujące rzeczy:
-
Przeglądarka wysyła do example.com prośbę o stronę główną.
Przy okazji wysyła parę informacji o sobie, jak przy każdej internetowej interakcji. Wśród tych informacji mogą być pliki cookies.
- Dostaje stronę. Dokładniej: ten sam kod, który widzicie wyżej. Analizuje go i zauważa tam linki do dwóch obrazków.
-
Wysyła do example.com prośbę o pierwszy z obrazków, który również jest bezpośrednio od niej.
Do tej prośby, jak do każdej innej, są załączone pewne podstawowe informacje. Wśród nich również mogą być pliki cookies. Ale nie są szczególnie groźne, bo w końcu w punkcie 1 przeglądarka już wysłała informacje tej samej stronce.
-
Wysyła do wikimedia.org prośbę o drugi z obrazków. Również załączając komplet informacji. Mogą być wśród nich pliki cookies.
…Zresztą „mogą” to zbyt zachowawcze stwierdzenie. Po otwarciu narzędzi przeglądarki i zakładki
Ciasteczkawidzimy, że one tam są. W liczbie sześciu: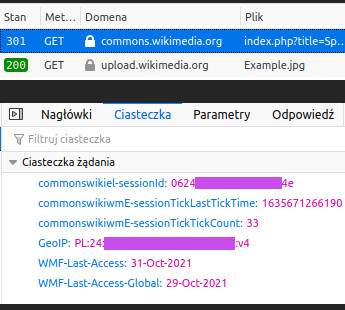
Gdyby za portalem wikimedia.org stała jakaś organizacja chcąca śledzić nasz ruch, to wykorzystałaby te ciasteczka z czwartego punktu do rozpoznania nas. Zaś informacje dodatkowe oraz fakt, na jakiej stronie i o jakim czasie byliśmy, trafiłyby do naszej kartoteki.
Ale to luźne rozważania, bo akurat Wikimedia szanuję i ich nie posądzam. Najważniejszy wniosek z tej części jest prostszy: od strony technicznej element śledzący może być dowolną rzeczą, która ma w atrybucie src link do obcej strony.
 Porada
Porada
Jeśli chcemy zobaczyć, do jakich źródeł zwraca się nasza przeglądarka, możemy nacisnąć Ctrl+Shift+I (jak Irena), żeby otworzyć narzędzia przeglądarki. Następnie wchodzmy w zakładkę Sieć i w razie potrzeby odświeżamy stronę.
Każda z pozycji na wyświetlonej liście to osobny element, o który poprosiła przeglądarka.
Dlaczego piksele?
Napisałem wyżej, że element śledzący może być dowolną rzeczą. Firmom śledzącym zależy jedynie na tym, żeby był pobierany z ich strony, a link do niego gościł na stronach cudzych.
Mogliby oferować link do filmiku. Albo do „Damy z łasiczką” w cyfrowej postaci. Albo do dowolnych innych multimediów. Nada się wszystko, byle pochodziło od nich.
Oni jednak wolą przyoszczędzić. Jaka jest najmniejsza możliwa rzecz, jaką mogą zaproponować naszej przeglądarce, żeby ta wysłała im dane? Odpowiedź: to obrazek o wymiarach 1 na 1. Czyli piksel!
W ten sposób rozwiązaliśmy zagadkę. W pikselach nie ma nic wyjątkowego, są po prostu najmniejszym możliwym elementem zewnętrznym.
Tym, co umożliwia śledzenie, jest tak naprawdę sama „zewnętrzność” elementu, sprawienie żeby był pobierany od firmy śledzącej. Jego wygląd to detal bez większego znaczenia. Zresztą prawdopodobnie i tak go nie zobaczymy, bo będzie ukryty.
Piksele, filmiki czy obrazy Leonarda… Jakiejkolwiek formy nie przyjęłyby elementy śledzące, warto się chronić przed wścibskim wzrokiem ich właścicieli. Opiszę teraz, w jaki sposób możemy to zrobić.
Jak się chronić?
Przypomnijmy: śledzenie opisane w tym wpisie polega na tym, że przeglądarka dostrzega link do obcego elementu i ochoczo go pobiera, razem z ciasteczkami.
Zatem gdybyśmy sprawili, że będzie ignorowała niektóre elementy (albo przynajmniej nie przechowywała od nich ciasteczek), to pokonamy ten mechanizm.
W praktyce można to osiągnąć przez zainstalowanie dodatku do przeglądarki. Będzie porównywał elementy zewnętrzne ze znanymi czarnymi listami. Jeśli zobaczy coś, co mu się nie spodoba, to tego nie pobierze.
Instalacja dodatku blokującego
Instalacja dodatku wydaje się najłatwiejszym rozwiązaniem, więc to na tym się skupię. Mam trzy, które osobiście sprawdziłem i polecam:
-
uBlock Origin
Koniecznie Origin, nie samo uBlock!
Jeśli czytaliście kilka moich ostatnich wpisów, to już możecie mieć lekkie deja vu, bo nieraz wspominałem o tym dodatku
Ale po prostu nie sposób go nie wymienić w kontekście elementów śledzących. To jedno z najskuteczniejszych narzędzi w walce z nimi.
Tutaj znajdziecie mój wpis na jego temat. A tutaj jego stronę główną. -
AdNauseam
Zbudowany na bazie uBlock Origin, ale z dodatkowym bajerem. Chowa reklamy przed naszym wzrokiem, a ich stronom macierzystym wysyła informację zwrotną, że je kliknęliśmy

Jest z nim trochę zachodu, jeśli używamy Chrome’a i pokrewnych przeglądarek, bo został zbanowany. Trzeba go pobrać i zainstalować ręcznie, co nie jest trudne, ale to nadal dodatkowe kroki. Z kolei na takim Firefoksie instalacja jest bezproblemowa.
Znajdziecie go tutaj. -
Privacy Badger
Ma mniej opcji niż dwa wcześniej wspomniane dodatki, ale ta prostota może być jego atutem. Po prostu go instalujemy i o nim zapominamy, a reklam robi się mniej.
Można go pobrać ze strony Electronic Frontier Foundation.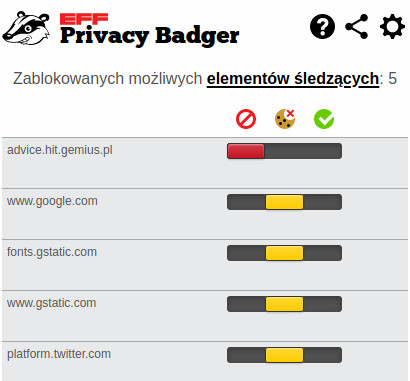
Menu Privacy Badgera. Suwaki w czerwonym kolorze oznaczają, że w całości zablokowano pobieranie zewnętrznego elementu. Te w żółtym oznaczają, że go pobrano, ale nie zapisano jego plików cookies.
Nie wykluczam, że są inne fajne dodatki blokujące. Ale na pewno lepiej unikać tych, które biorą udział w programie Acceptable Ads (AdBlock, AdBlock Plus, stary uBlock). Przepuszczają wybrane reklamy, a zatem również zawarte w nich elementy śledzące.
Dobry dodatek to nie wszystko. Powinien mieć też przeglądarkę, która pozwoli mu rozwinąć skrzydła. Na pewno taką przeglądarką nie jest Chrome, który stoi po stronie śledzących reklam. Warto go zmienić.
Jeśli nie macie takiej opcji, to trudno, już lepszy Chrome z dodatkiem blokującym niż Chrome bez niczego.
Przeglądarką, która lubi się z dodatkami blokującymi, a przy tym sama daje pewną domyślną ochronę, jest Firefox (potrafi na przykład automatycznie blokować Google Analytics). Sam używam i polecam.
Można też użyć przeglądarki Brave, która podobno daje jeszcze silniejszą ochronę domyślną. Acz jej akurat nie testowałem, czeka w kolejce.
Wyłącznik na Facebooku
Zainstalowanie dodatku blokującego przynosi wielorakie korzyści i powinniśmy to zrobić w pierwszej kolejności. Nic nie stoi natomiast na przeszkodzie, żeby to uzupełnić o rozwiązania szczegółowe.
Niektóre duże strony – zapewne pod naciskiem unijnych przepisów – udostępniają własne menu, pozwalające wyłączyć łączenie danych z naszego głównego konta z tymi pozyskanymi przez elementy śledzące ze stron zewnętrznych.
Przykładem takiej strony jest Facebook.
Żeby wyłączyć jego elementy śledzące, wchodzimy na podstronę dotyczącą aktywności poza Facebookiem.
(Najlepiej przez komputer; spójrzcie też na pasek z adresem, żeby się upewnić, że to prawilna strona Facebooka, a nie jakaś podpucha ![]() ).
).
Tam, po prawej stronie, mamy menu. Klikamy w nim Więcej opcji u dołu, potem wybieramy Zarządzaj przyszłą aktywnością i odznaczamy co trzeba. Jeśli wolicie formę obrazkową, to służę:
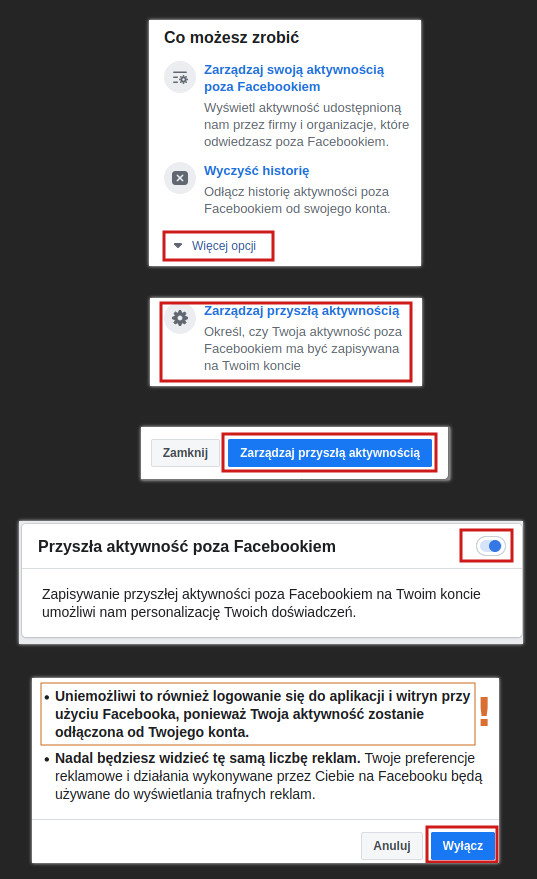
Zatrzymajmy się na moment przy zdaniu, które wyróżniłem wykrzyknikiem. Fejsik mówi nam, że jeśli wyłączymy łączenie danych z tymi zewnętrznymi (czyli przez pliki cookies), to stracimy opcję „Zaloguj przez Facebooka”.
Oczywiście nadal będziemy mieli dostęp do Fejsa. Tym niemniej istnieją nieliczne strony, które dopuszczają tylko logowanie przez FB zamiast tradycyjnego; spotkałem się kiedyś choćby z takim hotspotem. W takim wypadku pstryknięcie wyłącznikiem może nam nie być na rękę.
Ale wydaje mi się, że jeśli jakaś strona nie potrafi nam zapewnić normalnego logowania przez e-mail, tylko musi nas uzależniać od amerykańskich gigantów, to i tak nie zasługuje na naszą obecność. Zatem klikamy Wyłącz.
Co przyniesie przyszłość
Jako zwykli użytkownicy możemy po prostu zainstalować dodatek, zmienić przeglądarkę i żyć dalej. Ale warto wiedzieć, że za kulisami od wielu lat trwa konflikt w sprawie plików cookies i ich losy mogą różnie się potoczyć.
Już kiedyś mieliśmy unijne przepisy nakazujące informować użytkowników, że strona zbiera ciasteczka. Niestety przyniosły one tylko wkurzające banery z informacjami, które zaczęliśmy odruchowo zamykać.
Nieco ostrzejsze przepisy weszły na poziomie Unii parę lat temu, wraz z dyrektywą GDPR (w Polsce znaną jako RODO). Od teraz nie wystarczyło informowanie użytkowników o fakcie dokonanym – muszą wprost wyrazić zgodę na śledzenie ich aktywności. W dodatku organizacje ds. ochrony danych zyskały możliwość nakładania kar finansowych.
Przechodząc z sektora publicznego w prywatny: sam Google ogłosił, że planuje usunąć z Chrome’a wsparcie dla ciasteczek ze stron zewnętrznych. W ten sposób cały mechanizm śledzenia z dnia na dzień przestałby istnieć.
Czyżby giganta tknęło sumienie?
Optymista by chciał, ale realista powie raczej, że Google stał się już na tyle potężny, że ma lepsze źródła informacji. Usunięcie tej metody śledzenia podbiłoby mu PR i być może wykosiło mniejszych konkurentów, którzy są od niej bardziej zależni.
Po co mu przybliżone dane z szerszego internetu, gdy może mieć dokładne – z Androida, Chrome’a oraz własnych stron, dobrowolnie odwiedzanych przez użytkowników?
Innym argumentem przeciw dobrej woli Google’a jest to, że planuje wprowadzić w Chromie zmiany, które zmniejszą skuteczność dodatków blokujących (o czym alarmuje twórca uBO).
Poza tym w miejsce ciasteczek Google proponuje reklamodawcom własny system, FLoC. Zintegrowany z przeglądarką, niezależny od stron internetowych. Automatycznie, rzekomo w sposób anonimowy, rozdzielający ludzi na różne kategorie, do których będą kierowane odmienne reklamy.
Ciekawostka
Nazwa FLoC to rozwinięcie pewnego technicznego skrótu, ale kryje się pod nią dość ciekawa dwuznaczność – identycznie brzmiące angielskie flock to między innymi określenie na stado owiec.
Propozycja spotkała się z oporem, ponieważ to kolejny krok do uczynienia internetu mniej otwartym, a bardziej zależnym od Google’a.
Wśród przeciwników są autorzy Wordpressa, najpopularniejszego silnika do tworzenia blogów. Zapowiedzieli, że domyślnie będą wyłączali opcję łączenia wordpressowych stron z Google’owym systemem.
Jak się to wszystko skończy? Zmianą ducha czasu i zniknięciem ciasteczek ze stron zewnętrznych? Przekształceniem ich w coś innego, trudniejszego do zwalczenia? Czy też kontratakiem korporacji i jeszcze większym obłożeniem internetu elementami śledzącymi?
Czas pokaże! Na pewno dołożymy do zmian swoją cegiełkę, chodząc po sieci z dodatkami blokującymi.
Tym wpisem kończę część „Internetowej inwigilacji” poświęconą informacjom, jakie nasza przeglądarka wysyła automatycznie, zanim w ogóle dostaniemy stronę internetową.
Teraz ta strona w końcu do nas dotarła, można ją odpakować jak prezent na Mikołajki.
A w niej możemy znaleźć elementy interaktywne napisane w języku JavaScript. Dające mnóstwo możliwości… również jeśli chodzi o śledzenie.
To ten język będzie tematem kolejnego wpisu z serii. Do usłyszenia!
Był to wpis z serii Internetowa inwigilacja