
Internetowa inwigilacja plus 8 – profilowanie stron internetowych
„Wiem, kogo odwiedzasz”
Wpis z serii Internetowa inwigilacja
Wracam do pisania po najdłuższej jak dotąd, ponad dwumiesięcznej przerwie! Nie tylko rekreacyjnej. Dopracowałem też parę ambitniejszych projekcików, którymi jeszcze się podzielę ![]()
Ale najpierw klasyczne wpisy. Zaczynając od tego tutaj, demaskującego kolejne metody z przybornika cyfrowych stalkerów (prywatnych i korporacyjnych).
Rozwinę tu kwestie wokół ustalania, co robili internauci, mimo że ich interakcje były szyfrowane. Wciąż mogą ich bowiem zdradzić cechy ruchu sieciowego, takie jak ogólne nazwy odwiedzanych stron, kierunek przesyłu danych, ich rozmiar oraz czas wysłania.
W poprzednim wpisie na ten temat podglądacze byli bierni, tylko obserwowali. Dziś uchylę to założenie.
Znając nazwę strony, jaką odwiedzała ofiara, mogliby również ją odwiedzić i sprofilować – zebrać różne jej podstrony, ustalić łączny rozmiar każdej z nich. Znaleźć cechy odróżniające je od siebie.
Następnie ich programy mogłyby porównać te wzorce z ruchem swojej ofiary. Ustalając, co dokładnie robiła na danej stronie.

Źródła: regał z serwisu Freepik, liczby z Emojipedii, mem z Wojakiem, dymek z LibreOffice Writera. Przeróbki moje.
Spis treści
- Przypominajka
- Profilowanie na przykładzie Stack Exchange
- Ograniczenia metody
- Jak chronić siebie
- Jak chronić innych
- Zakończenie
Przypominajka
Na początek streszczę parę najważniejszych informacji z poprzedniego wpisu, podlinkowanego wyżej.
W ramach „Internetowej inwigilacji” wyróżniam często dwa rodzaje podglądaczy, różniących się pod względem możliwości wglądu w dane.
Więcej – ale tylko na swoim terytorium – widzą właściciele odwiedzanych stron albo elementów gościnnych, jak reklamy śledzące.
Drugi rodzaj podglądaczy to właściciele infrastruktury internetowej. To oni są antagonistami tego i poprzedniego wpisu. Ich przykłady:
- firma telekomunikacyjna (operator sieci komórkowej),
- właściciel routera, przez który łączymy się z siecią (np. administrator sieci firmowej/uczelnianej; personel kawiarni wyposażonej w hotspota),
- właściciel VPN-a, jeśli z jakiegoś korzystamy.
Następna kwestia: co widzą tacy podglądacze.
Przypadkiem skrajnym są strony zaczynające się od http://. W wielu przeglądarkach oznaczane ikonką przekreślonej kłódki obok górnego paska wyszukiwania. Gdy je odwiedzamy, to połączenie nie jest szyfrowane i podglądacz widzi wszystko.
Jest to jednak coraz rzadsza sytuacja, więc nie będę jej brał pod uwagę. Zamiast tego skupię się na popularniejszym rodzaju interakcji, czyli odwiedzaniu stron zaczynających się od https://.
Połączenia z nimi są szyfrowane i przeciwnik nie zobaczy, co sobie wysyłamy ani jak się sobie „przedstawiamy”. Spod szyfrów nadal jednak wystają pewne rzeczy (jak nazwa domeny, czyli np. www.ciemnastrona.com.pl), do których jeszcze wrócę.
Profilowanie na przykładzie Stack Exchange
Koniec przypominajek, czas na dzisiejsze zagrożenie! Profilowanie stron internetowych (ang. website fingerprinting). Wpisując to pojęcie w wyszukiwarkę, można trafić nawet na pełnoprawne artykuły naukowe.
Ogólne założenie metody jest proste – opiera się ona na tym, że wiele stron internetowych nie zmienia się w czasie. Jest spora szansa, że zwiedzając tę samą stronę co podglądana osoba, trafi się na te same treści.
A to oznacza dane o takim samym rozmiarze i „kształcie”. Podglądacz jest jak człowiek otrzymujący od strony po kilka klocków i patrzący, czy pasują do otworów w jego planszy.
Żeby lepiej to zwizualizować, użyję konkretnego przykładu. Będzie nim wielkie forum Stack Exchange. Poświęcone głównie sprawom komputerowym, ale są tam też mniejsze podfora o tematyce wszelakiej. Językach świata, gotowaniu, majsterkowaniu…
 Ciekawostka
Ciekawostka
Stacka nie wybrałem tak całkiem przypadkowo. To forum już łączy się z co najmniej jednym głośnym zdemaskowaniem (choć akurat przez coś bliższego stylometrii niż profilowaniu stron).
Mianowicie: odkryto tożsamość właściciela znanej darknetowej giełdy przez pytanie o sieć anonimizującą, jakie zadał kiedyś na podforum StackOverflow. Zadziwiająco dobrze pasowało do jego działalności.
…A przynajmniej taki powód wskazano jako oficjalny. Niewykluczone, że tożsamość ustalono innymi metodami, a wersję ze Stackiem przyjęto jako wiarygodną narrację.
Scenariusz
Przykład z życia czas zacząć!
Jest sobie pewna osoba, którą nazwiemy sobie X. Wygląd, historia, zainteresowania – pozostawiam waszej wyobraźni.
Powiem tylko, że akurat jest w trakcie podróży. Zbiorkomem, bo nie trzeba tam trzymać rąk na kierownicy i można w spokoju czytać nowinki z różnych grup tematycznych.
Wysiada na dworcu i czeka na dalszy transport. Łączy się z darmowym hotspotem, żeby nieco oszczędzić danych mobilnych.
Nie wie jednak, że akurat ten konkretny hotspot jest obsługiwany przez znużonego administratora z zamiłowaniem do automatyzacji… I stalkingu.
Wszelkie dane przechodzące przez router są automatycznie analizowane. Jeśli jakieś urządzenie odwiedzi co ciekawsze strony internetowe, to programy admina zaczną zapisywać powiązany z nim ruch do osobnych folderów. Admin będzie potem gmerał sobie w tych danych, oblizując się po gałkach ocznych.
A tak się składa, że wśród domen odwiedzonych podczas tej dworcowej posiadówki była co najmniej jedna, która wzbudziła stalkerskie zainteresowanie.
Założmy, że podglądana osoba X czyta na przykład dwa ciekawe podfora Stacka. Jedno dotyczy przeglądarki anonimizującej Tor Browser, a drugie ogólnego cyberbezpieczeństwa.
Pierwszy krok: domena
Nazwa domeny oraz jej adres IP, widoczne zazwyczaj mimo szyfrowania, są świetnym punktem wyjścia dla podglądaczy.
Tak się składa, że na Stacku każde podforum ma swoją osobną subdomenę. Tej od Tora odpowiada tor.stackexchange.com, zaś dyskusje wokół cyberbezpieczeństwa toczą się na security.stackexchange.com.
W oczach użytkownika link do przykładowej dyskusji, kliknięty w wyszukiwarce, wygląda tak:
Podglądacze widzą to, co na biało. Ogólną nazwę i rozmiar danych. Z kolei czerwona część linku, jak i sama treść strony, są zaszyfrowane.
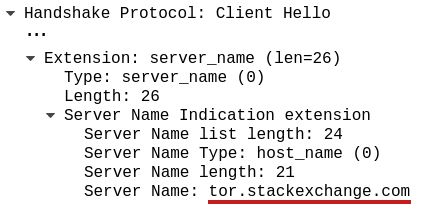
Tutaj zrzut z programu Wireshark przechwytującego ruch internetowy; nazwa strony znajduje się w polu Server Name Indication.
Gdyby Stack trzymał wszystko na jednej domenie, stackexchange.com, to podglądacz zapewne by odpuścił. Za dużo możliwości, do tego większość osób trzyma się pewnie prozaicznych pytań w stylu „jak wyśrodkować przycisk na stronie”.
…Ale kiedy program podglądacza wyłapie to konkretne podforum, poświęcone dbaniu o anonimowość? Potraktuje to jako sygnał, że może tej osobie poświęcić więcej uwagi.
Ciekawostka
Taki wstępny przesiew na podstawie metadanych jest całkiem popularną taktyką w świecie cyfrowej inwigilacji. Nie tylko stalkerskiej, ale i zawodowej, szpiegowskiej.
Amerykańska agencja NSA opracowała listę stron podejrzanych, których bywalców kwalifikuje się do wzmożonej obserwacji. Co ciekawe, do takich portali zaliczono… Linux Journal, czyli nieszkodliwą hobbystyczną stronkę poświęconą alternatywie dla Windowsa.
Link prowadzi prosto do niej, gdyby ktoś chciał zerknąć ![]()
Drugi krok: wytypowanie możliwych podstron
Znając domenę, podglądacz może odwiedzić wszystkie strony, które są zebrane pod jej parasolem. Przypomnę analogię: zawartość domeny jest jak wór klocków lub puzzli o różnym kształcie, które nasz antagonista będzie sobie dopasowywał do otworów pozostawionych po swojej ofierze.
A jak duży jest ten wór?
Na podforum dotyczącym Tora znajdowało się łącznie, gdy ostatnio zerkałem, 5801 wątków. Na podforum Security, o cyberbezpieczeństwie, jest ich 69 029.
Dla człowieka może i dużo, dla komputera – tyle co nic. Podglądacz może wypuścić na interesującą go stronkę swojego crawlera, czyli program odwiedzający wskazane strony i zapisujący sobie ich treść.
W przypadku Stacka to o tyle łatwe, że przeglądanie stron nie wymaga logowania. Nawet gdyby istniały jakieś zabezpieczenia utrudniające amatorskie zbieractwo, podglądacz mógłby zapłacić zbieraczom zawodowym. Korzystając z całej sieci komputerów i dużej puli adresów IP, ominęliby blokady i pobrali całą treść.
Do tego automat mógłby wykorzystać na swoją korzyść szablonowy format linków do list zbiorczych:
https://PODFORUM.stackexchange.com/questions?tab=newest&pagesize=50&page=LICZBA
Podstawiając nazwę podforum i kolejne liczby, crawler podglądacza prosiłby o kolejne rzeczy i stopniowo zebrałby pełną listę linków do wszystkich wpisów. Wraz z podstawowymi informacjami na temat każdego z nich:

Zapamiętajcie sobie wygląd miniaturek wpisów, za chwilę do tego wrócę.
Trzeci krok: zawężenie listy podstron
Stack posiada jeszcze jedną cechę, która mogłaby pomóc zawęzić liczbę stron do pobrania. To awatary (obrazki) użytkowników, pobierane ze stronek zewnętrznych. W wątkach dyskusyjnych, wedle moich obserwacji, pojawiają się tylko w określonych miejscach:
- jeden awatar autora przy pytaniu;
- po jednym awatarze przy każdej z odpowiedzi;
- (opcjonalnie) awatar osoby edytującej, najwyżej jeden na pytanie/odpowiedź.
Fragment interfejsu Stacka na przykładzie innej dyskusji na temat Tora, awatary wyróżniłem ramkami.
Gdyby ktoś edytował któryś wpis, to po lewej stronie autora znalazłby się awatar osoby edytującej.
A teraz wrócę do listy wątków, której screen pokazałem wcześniej. Jedną z informacji przy każdym linku do dyskusji jest liczba udzielonych odpowiedzi.
Widząc „3 odpowiedzi” przy miniaturce jakiegoś wątku, podglądacz może zakładać, że jego odwiedzenie wiąże się z pobraniem od 4 do 8 awatarów (1 przy pytaniu, 3 przy odpowiedziach, reszta od ewentualnych edycji pytań/odpowiedzi).
A w jaki sposób podglądacz może wyciągnąć z historii ruchu sieciowego, ile awatarów pobrała jego ofiara? Przecież dane są szyfrowane. Łącznie z nazwami plików, więc nie widać nawet, czy coś jest obrazkiem, ikonką samego forum, skryptem czy innym wihajstrem.
Awatary jednak mocno się wyróżniają na tle reszty – pochodzą z innych domen.
Porada
Zachęcam do osobistego weryfikowania wszystkich moich przykładów w narzędziach dostępnych w niemal każdej przeglądarce ![]()
Wystarczy nacisnąć klawisze Ctrl+Shift+I, żeby otworzyć panel z narzędziami. Następnie trzeba kliknąć zakładkę Sieć u góry i w razie potrzeby odświeżyć stronę. Po najechaniu kursorem na nazwy pobranych obrazków powinny się wyświetlać ich miniaturki.
Dla wygodniejszego czytania warto też kliknąć ikonkę w górnym prawym rogu i wybrać wyświetlanie w osobnym oknie. Można je wtedy powiększać i przesuwać wedle uznania.
Wchodząc w podlinkowaną już dyskusję o Torze i zerkając w narzędzia przeglądarki, poznałem kilka źródeł awatarów:
- awatary losowe (pod pytaniem i jedną z odpowiedzi) pochodzą z domeny
gravatar.com, - awatar autora najnowszej odpowiedzi, przypominający kaczkę, od
lh3.googleusercontent.com, - inny awatar od
i.sstatic.net.
Nie do końca wiem, z czego wynika obecność Google’a. Być może użytkownicy mogą czasem wiązać swoje konto na Stacku z innymi usługami, a Stack korzysta wtedy z innych awatarów niż domyślnie?
W każdym razie – z tego co zaobserwowałem, te domeny (poza ostatnią) odpowiadają wyłącznie awatarom.
Widząc liczbę drobnych plików nadlatujących z powyższych domen, podglądacz może łatwo odgadnąć liczbę awatarów, jakie wyświetliły się ofierze. I zawęzić swoją listę do tych dyskusji, które mają odpowiednią liczbę odpowiedzi.
Czwarty krok: łączenie informacji
Ostatnim etapem po zawężeniu listy linków jest odwiedzanie po kolei każdego z nich. I porównywanie otrzymanych danych ze wzorcem. Ułatwia to szereg właściwości Stacka.
Po pierwsze: dyskusja dyskusji nierówna. Niektóre są znacznie obszerniejsze od innych. A dłuższe ściany tekstu oznaczają siłą rzeczy, że plik HTML – sam szkielet strony, wysłany jako pierwszy po jej odwiedzeniu – będzie miał nieco większy rozmiar niż te odpowiadające innym dyskusjom.
Po drugie: w dyskusjach można czasem dodawać obrazki.
Żeby już nie trzymać się tylko Torów i szyfrów – przedstawiam epicką dyskusję na temat literki z piłki dla dzieci. Dyskutanci próbują ustalić, dlaczego przy rysunkowej siekierce umieszczono literkę Y. Śledztwo sięga Chin i Skandynawii.
…I obejmuje wklejanie licznych obrazków, serwowanych głównie z domeny i.sstatic.net. Niektóre mają rozmiar po sto kilkadziesiąt kB, co skutecznie je odróżnia od awatarów. I wyróżnia całą dyskusję spośród innych, bardziej tekstowych.
Same awatary też zresztą się różnią pod względem rozmiaru. Te złożone z prostych geometrycznych kształtów, generowane losowo przez Stacka, mają zwykle nieco ponad 1 kB rozmiaru. Pozostałe, będące pełnoprawnymi (choć małymi) obrazkami, ważą ponad 2 kB.
No i pozostaje kwestia domen, z których pochodzą awatary. Poprzednio do zawężania listy wystarczyła łączna liczba wszystkich „awatarowych”.
Na tym etapie dla podglądacza bezcenne będą z kolei ich pełne nazwy. „Dwa obrazki z Gravatara, jeden z googleusercontent” to informacja, która może się okazać unikalnym identyfikatorem jakiejś dyskusji.
Łącząc te informacje w całość, klasyfikator (program analityczny) podglądacza może rozpoznać spośród możliwych dyskusji tę jedną, konkretną, którą odwiedziła wcześniej ofiara.
Metoda potrafi być niepokojąco dokładna. Na szczęście sytuacja nie zawsze będzie idealna dla podglądaczy.
Ograniczenia metody
Przeglądarki, systemy operacyjne, internetowe serwisy… to czasem złożone bestie. A duża ilość ruchomych elementów utrudnia profilowanie.
Solą w oku drobniejszych podglądaczy może być na przykład pamięć podręczna.
Żeby nie pobierać jednakowych elementów (np. obrazków) wielokrotnie, przeglądarka zapisuje je na jakiś czas na dysku, we własnym folderze.
Przykład? Logo Ciemnej Strony z górnego paska mojego bloga. Przeglądarka pobierze je raz, przy pierwszym odwiedzeniu bloga. Ale potem, do czasu wyczyszczenia pamięci, już nie będzie o nie prosiła.
Pamięć podręczna może odebrać podglądaczom proste przejście łączny rozmiar elementów → konkretna strona. Pojawia się niepewność. Ale niektóre klasyfikatory niestety mogą być na to odporne, przypisując większą wagę tym elementom, które nie trafiają do pamięci.
Drugie utrudnienie (ale tylko na niektórych stronach) – losowość i ładowanie dynamiczne.
W roli ilustracji użyję wielkich portali, jak Facebook czy Tiktok. Choć same podglądają ludzi, są chyba najgorszym koszmarem dla podglądaczy zewnętrznych.
Po pierwsze: wykorzystują niewiele domen. Właściwie tylko główną i parę pomocnicznych, z których serwują na przykład obrazki (jak fbcdn.net w przypadku Facebooka).
Po drugie: nie mają stałej postaci. Wyświetlają różne rzeczy w zależności od profilu osoby, która z nich korzysta, zdarzeń na świecie, a może nawet zwykłej losowości.
Jest też mnóstwo czynników pobudzających napływ danych – przewinięcie tablicy, kliknięcie jakiejś opcji, nowa wrzutka od obserwowanego profilu…
Do tego znane portale po prostu są wielkie. Jak oceany danych. Praktycznie nie ma szans na ustalenie, że pobrana rzecz o rozmiarze 79 kB jest jakimś konkretnym obrazkiem.
Powyższe informacje, choć są pewnym pocieszeniem, nie powinny powodować spoczęcia na laurach. Oznaczają tylko tyle, że machina nie jest wszechmocna. Ale nadal trzeba trochę powalczyć ![]()
Jak chronić siebie
Choć profilowanie dotyczy stron, na które internauci nie mają bezpośredniego wpływu, sami również mogą puścić trochę światła we wścibskie oczy.
Zasada ogólna – trzeba ustawić między sobą a łatwą do sprofilowania stronką jakiegoś pośrednika.
Punktem wyjścia do profilowania są nazwy domen. Jeśli staną się niewidoczne, to podglądacz niewiele zdziała. Wór wymieszanych stron do sprawdzenia stałby się wielki jak internet.
Po więcej szczegółów i schematy graficzne odsyłam do poprzedniego wpisu; poniżej jedynie ogólna przypominajka.
Streszczenie metod ochrony (dla chętnych)
-
HTTPS plus szyfrowanie metadanych (DoH plus ECH)
W tym przypadku przeciwnik nie widzi nazwy odwiedzanej domeny. Widzi za to adresy IP, rozmiar danych, czas ich wysłania.
Ograniczeniem metody jest to, że musi być wspierana przez odwiedzane strony. A że jest względnie nowa, to póki co nie jest zbyt popularna. Lepiej zakładać jej brak. -
pośrednik/VPN
Przeciwnik widzi jedynie adres IP pośrednika i nie wie, jakie części internetu są po jego drugiej stronie. Widzi też rozmiar i czas wysłania danych, ale to może niewiele pomóc.
Wadą rozwiązania jest konieczność powierzenia pośrednikowi prawdziwych nazw domen i adresów… A nie ma gwarancji, że sam tych danych nie gromadzi. -
sieć Tor
Jak VPN na sterydach. Zamiast jednego pośrednika – łańcuszek kilku rozsianych po świecie, z których każdy jest losowo dobierany i ma tylko strzępki informacji. Zewnętrzny podglądacz zobaczyłby tylko adres IP pierwszego z nich.
Co więcej, Tor stosuje dodatkowe mechanizmy ochronne. Dane są wysyłane w nieregularnych, losowych odstępach czasu. Koszmar dla podglądaczy.
A co, jeśli nie ma się dostępu do żadnego pośrednika typu Tor/VPN, a jedyną opcją jest bezpośrednie odwiedzanie stron? Można wtedy skorzystać z większych stron zdolnych wyświetlać cudze treści pod swoim „szyldem”.
Przykładem są archiwa internetowe jak archive.org czy archive.is, gromadzące treść przeróżnych stron. Podglądaczom dużo trudniej by było je zmapować, choćby ze względu na ich rozmiar.
Żeby korzystać z archiwów, wystarczy skopiować interesujący nas link i wkleić go w ich wyszukiwarki. Jeśli ktoś już kiedyś zapisał taką stronę do archiwum, to wyświetli się kalendarz z historią poprzednich zapisów. Tam nieraz się znajdzie szukaną treść. A podglądacz łatwo jej nie pozna.
Powiązane wpisy
Podobne obejście opisałem we wpisie na temat cenzury przez DNS. To dlatego, że zasada działania jest bardzo podobna – jakaś menda, widząc nazwy niektórych domen, jakie próbujemy załadować, zachowuje się wobec nas niegrzecznie. Więc tę nazwę ukrywamy, żeby wymusić domyślną grzeczność.
Rozwiązania pomocnicze
Najpierw podkreślę: wszystko poza ukrywaniem domen (i adresów IP) to jedynie dodatkowe szlify. Stosowanie ich bez zadbania o fundamenty wydaje mi się bezcelowe.
Tym niemniej, jeśli ktoś nie ma jak skorzystać z pośrednika albo chce dopracować parę rzeczy… To warto wiedzieć, że odrobinę mogą namieszać niektóre dodatki modyfikujące działanie przeglądarki. Jak uBlock Origin, bloker śledzących reklam.
W opcjach dodatku można ustawić, żeby nie pobierał obrazków większych niż ustalony rozmiar (w kilobajtach). Ta opcja sprzyja głównie oszczędzaniu danych… Ale ma też niezamierzony wpływ na prywatność.
Użytkownicy odbiegają od wzorca. Pobierają znacznie mniej danych niż oczekiwałby podglądacz, dzięki czemu ich aktywność może być trudniejsza do sklasyfikowania.
Jeśli korzysta się z pośrednika/Tora/VPN-a, to podglądacz widzi tylko jeden adres IP.
Można wtedy dodatkowo namieszać, otwierając kilka podstron w osobnych kartach. Jedną po drugiej. Nastąpi wtedy większy napływ danych z tego samego adresu i może być trudniej rozpleść, z jakich podstron to pochodzi.
Jak chronić innych
Właściciele stron raczej nie uchronią się przed odwiedzinami crawlerów i mapowaniem swoich stron. Mogą natomiast na kilka sposobów wspomóc swoich użytkowników, czyniąc strony mniej podatnymi na profilowanie przez stalkerów.
Niewinne domeny, winne podstrony
Domena była pierwszym krokiem w profilowaniu strony. Dlatego, w miarę możliwości, można wybrać sobie jakąś grzeczną nazwę, żeby nie przykuwała uwagi. Dla tego bloga już na to za późno, ale dla was może jeszcze nie ![]()
Dla rozluźnienia wplotę mikrowątek baśniowy. Wyobraźmy sobie, że żyjemy w fikcyjnym Królestwie Gudwajbinii (zmyślona domena nadrzędna: .gud).
Jego mieszkańcy są szczęśliwi. Muszą być. Bo jakiekolwiek zwątpienie w dobrobyt skończyłoby się odwiedzinami knechtów i siepaczy o trzeciej nad ranem.
W takich warunkach antymonarchistyczni blogerzy powinni przede wszystkim pamiętać, żeby ich domena nie ujawniała złych intencji. Nie powinna mieć nazw jak poniższe:
https://krol-jest-nagi.gud https://krol-jest-nagi.nowinki.gud
Może natomiast nazywać się:
https://nowinki.gud/krol-jest-nagi
…Ponieważ gdy działa HTTPS, to wzrok podglądaczy kończy się na ukośniku po domenie. Nie widzą tego, co na czerwono.
Oczywiście należałoby też zadbać o to, żeby nie dało się z góry uznać całej domeny za niepożądaną. Oprócz podstron /krol-jest-nagi powinna zawierać również niewinne, jak /ku-chwale-krola albo /rozmyslania-o-niczym. W ten sposób trudniej by było kogoś ukarać na podstawie samego odwiedzenia domeny.
Inną realną opcją mogłoby być publikowanie tekstów na cudzych stronach; na tyle dużych, żeby nie były tak łatwe do zmapowania.
Przykładem mogą być wspomniane już archiwa internetowe takie jak archive.is albo archive.org, przechowujące u siebie treści z całego internetu. Ale nawet większe megafora i portale społecznościowe, o ile nie są na usługach monarchy, dałyby radę.
Jedna domena
W przykładzie z udziałem Stacka istotną rolę odgrywały domeny, z których serwowano awatary. Pozwalały zawęzić przestrzeń do sprawdzenia, a ich nietypowe kombinacje umożliwiały rozróżnianie dyskusji.
Żeby zapobiec takim sytuacjom, warto zadbać o jak najmniejszą liczbę domen, z których ładują się elementy strony. A przynajmniej sprawić, żeby ich zestaw był identyczny dla każdej podstrony.
Należałoby też unikać hotlinkingu, czyli umieszczania na stronce specjalnych linków każących przeglądarkom pobrać rzeczy z cudzych stron.
Przykładem hotlinkingu byłoby okazjonalne umieszczanie elementów obrazkowych typu <img src="cudza-strona.pl…"/> w źródle własnej strony. Ktoś mógłby łatwo zmapować, że mamy gdzieś na swoim portalu tę jedyną podstronę ładującą obrazek od cudza-strona.pl.
Lepsza opcja? Pobranie obrazków z innej strony na swój dysk, wyraźne oznaczenie źródła, umieszczenie ich pod własną domeną.
Z powyższego względu warto też nie korzystać z elementów osadzonych, jak tweety albo filmiki z YouTube’a. Działają na podobnej zasadzie jak hotlinking obrazków i będą się wyróżniały w historii ruchu sieciowego. Pomijając już fakt, że ich strony źródłowe mogą próbować wpływać zdalnie na ich treść.
Lepsza opcja? Screeny albo cytaty, a pod nimi link.
Ujednolicanie podstron
To chyba najtrudniejsza część – jak sprawić, żeby nie dało się rozróżnić podstron na podstawie rozmiaru ładowanych elementów?
Przycinanie wszystkich elementów do jednego rozmiaru raczej nie wchodzi w grę, więc pozostaje równać w górę – dopychać pustymi danymi, aż wszystko osiągnie ten sam rozmiar. Po angielsku takie dopychanie nosi nazwę padding.
Problem w tym, że może być to zbyt uciążliwe dla wielu osób tworzących strony.
Przykład? Jeśli jeden wpis ma sześć obrazków, a inny tylko dwa, to gdzieś do tego drugiego należałoby dodać cztery obrazki-zapychacze. Do tego dopchać każdy z realnych obrazków do maksymalnego rozmiaru.
Strasznie dużo koordynacji. Do tego konieczność istotnego przekształcania swojej strony przy każdej drobnej zmianie.
Mam tu jednak potencjalne rozwiązanie, które ułatwiłoby ujednolicanie stron – korzystanie ze stron jednoplikowych, będących pojedynczymi plikami HTML.
Takie strony nie muszą być gołym tekstem. Elementy dodatkowe, takie jak obrazki czy arkusze styli, można bowiem zagnieździć bezpośrednio w kodzie HTML. W przypadku obrazków trzeba je przekonwertować do postaci Base64.
Wtedy obrazki zamiast atrybutu
src="ŚCIEŻKA_DO_PLIKU.jpg"
zawierałyby w sobie:
src="data:image/jpeg;base64,/9j/DŁUGI_CIĄG_ZNAKÓW"
Takie sprowadzanie strony do jednego pliku stosuje dodatek SingleFile, można podejrzeć jego rozwiązania.
W ostateczności, mając niewielką stronę i możliwość ręcznego dodawania plików HTML, można nawet użyć SingleFile w roli konwertera. Otwierać po kolei swoje stronki, zapisywać z użyciem SingleFile do pojedynczych plików. Podmienić nimi pierwotne strony.
Efekt rozwiązania? Każda podstrona byłaby jednym, samowystarczalnym plikiem HTML. Dużo łatwiej by było je dopchać pustymi danymi (np. długim komentarzem na końcu), żeby wszystkie miały identyczny rozmiar.
Wada rozwiązania? Wzrost rozmiaru stron. Użytkownicy będą musieli dłużej czekać, aż się wyświetlą, bo nie będzie ładowania na raty. Ale dla niektórych to niewielka cena za ochronę prywatności.
Parę innych szlifów
W tym miejscu zbiorę parę innych luźnych pomysłów. To dyrdymały na tle najważniejszych kwestii, czyli domen i rozmiaru elementów. Ale zawsze coś.
Gdyby ujednolicanie rozmiaru wszystkich plików HTML było dla kogoś upierdliwe, można przynajmniej dać użytkownikom bezpieczną poczekalnię na swojej wrażliwej stronce.
Mianowicie: umieścić na serwerze takie regułki, żeby każdy użytkownik – niezależnie od tego, z jakiego publicznego linku przychodzi – dostawał stronkę o takim samym rozmiarze. Zawierającą ostrzeżenie i zachętę do skorzystania z Tora lub pośrednika przed załadowaniem dalszej treści.
Na tym etapie jeszcze byłoby za wcześnie, żeby kogoś oskarżać o szkalowanie króla. Dopiero kliknięcie w link prowadziłoby do właściwej treści. A na tym etapie ludzie już zostali ostrzeżeni, reszta to ich sprawa.
Chętni mogą dodatkowo namieszać, dodając losowość. Czasem pobierać jakiś dodatkowy element, a czasem nie. Takie rozwiązanie można umieścić zarówno w kodzie serwera, jak i (poprzez JavaScript) na samych podstronkach.
Taki element nie musi być widoczny dla użytkownika, może być niewielki. Przeglądarka i tak go pobierze, a podglądacze – zobaczą rozmiar danych. Ale może im być trudniej do czegoś to przypisać.
Zakończenie
Profilowanie stron internetowych jest zagrożeniem nieco nietypowym jak na tego bloga. Nie wydaje się czymś masowym, z czego notorycznie korzystałyby firmy reklamowe. Ma praktyczne zastosowanie tylko wobec niektórych stron.
Ale, jeśli już zostanie z powodzeniem zastosowane, może szczególnie mocno uderzyć w osoby, którym zależało na prywatności.
Osobiście nie planuję wprowadzać na swoim blogu jednolitych, jednoplikowych stron czy losowych elementów. Być może komuś na świecie się to przyda. Ale ja, przy mikroskali bloga i luźnych tematach, tylko bym poświęcał minimalizm w imię larpowania ![]()
Rozważam natomiast serwowanie emotek wyłącznie z domeny ciemnastrona.com.pl zamiast z githubassets. Być może w formie wycinków z jednego obrazka (sprite’ów). To akurat by się nie kłóciło z prostotą, a nawet jej sprzyjało. Mniej domen, mniej zależności. Zobaczymy.
Na tę chwilę, gdyby ktoś nie chciał ujawniać Ciemnej w swoich logach, zachęcam do odwiedzania bloga przez Tor Browsera. Działa zacnie. A żaden admin hotspota czy stalker-hobbysta nie zobaczy w logach, że przeczytaliście właśnie wpis numer 92.
Do zobaczenia w kolejnych w drodze do setki! ![]()
Był to wpis z serii Internetowa inwigilacja